



クラウド時代に考える“ワークロード特化型”インテル® Xeon® プロセッサーの価値
HPCワークロードの特性を考えたアクセラレーターも搭載
“HPC専用”で性能強化! 広帯域メモリ内蔵のインテル® Xeon® CPU Maxシリーズ
2023年06月15日 11時30分更新


HBM(広帯域幅メモリ)を内蔵した「インテル® Xeon® CPU Maxシリーズ」
新型コロナウイルスの構造解析、地球気候変動シミュレーション、新素材・新物質の探索など、HPC(ハイパフォーマンスコンピューティング)はすでに、われわれの社会と生活を支える身近な存在となっている。近年では金融、創薬、設計/製造のような、産業界における民間のHPC利用も一般的になってきた。
第1回記事では、最新のデータセンター向けCPU「第4世代 インテル® Xeon® スケーラブル・プロセッサー」(第4世代 インテル® Xeon® SP)が、「実環境のワークロード性能」を重視した設計によってパフォーマンスを飛躍的に向上させていることを紹介した。その一例としてAI/データ分析ワークロードを取り上げたが、同じように、HPCワークロードでも大幅な性能向上を実現している。

中でもHPCワークロード向けで注目されるのは、64GBのHBM(広帯域幅メモリ)をCPUパッケージに内蔵した「インテル® Xeon® CPU Maxシリーズ」だろう。1コアあたり1GBを超えるメインメモリを内蔵することで、メモリ制約の大きいHPCワークロードにおいて、前世代のCPU比で「最大3.7倍」もの性能向上を実現している※注。今回は、HPCワークロードに最適な最新インテル® Xeon® プロセッサーの“強み”を見てみよう。
※注:インテル実施のベンチマークテストに基づく(以下、本文中のテスト結果はすべて同様)。
「HPCワークロード」の特性とは?
気象シミュレーションからゲノム配列決定、流体シミュレーション、金融リスク分析まで、「HPC」という言葉でひとくくりにされるワークロードは幅広い。「いわゆるスパコン(スーパーコンピューター)が処理するようなワークロード」と表現してもよいが、その特徴を簡単にまとめると「超ビッグデータ処理」「複雑な演算処理」「大規模な並列処理」といったものになる。
こうしたワークロードを高速に処理するために、プロセッサーにはどんな能力が必要だろうか。たとえば、巨大なデータを扱う処理には広帯域の(高速な)I/O、特に広帯域のメモリI/Oが重要である。ワークロードによっては、このメモリI/OがボトルネックになってCPUコア本来の性能が発揮できないこともあるという。また、大規模並列処理を実行するために、より多くのコア数も求められる。
他方では、データセンターの環境負荷が問題視されている現在、「消費電力あたりの処理性能」も重視されるだろう。世界のスパコンランキング「TOP500」が近年、消費電力性能によるランキング「Green500」も発表しているように、HPC分野でもより電力効率の良い処理性能が重視されるようになっている。
HPC向けアクセラレーターを搭載する第4世代 インテル® Xeon® SP
前回記事で紹介したとおり、第4世代 インテル® Xeon® スケーラブル・プロセッサーは、前世代のプロセッサー比でおよそ1.5倍の“基礎体力”(汎用ワークロードの処理性能)を備えている。

第4世代 インテル® Xeon® スケーラブル・プロセッサーの主な特徴
上述したHPCワークロードの要件に照らし合わせると、たとえば「広帯域なI/O」としては、最大4800MT/s(DDR4比で1.5倍)のDDR5メモリチャンネル、80レーン(4.0比で2倍)のPCIe 5.0、次世代I/O規格であるCXL(Compute eXpress Link)1.1などを備える。また「大規模並列処理」を高速化するものとして、1CPUあたりのコア数が最大60コアに拡張されたほか、CPUソケット間のインターコネクトとして最大16GT/s(4リンク)の広帯域なUPI(Ultra Path Interconnect)2.0を採用している。

第4世代 インテル® Xeon® スケーラブル・プロセッサーは各種インタフェースを刷新してI/Oを高速化
さらに第4世代 インテル® Xeon® スケーラブル・プロセッサーでは、特定の処理を効率化するアクセラレーターやテクノロジーを多く搭載している。特にHPCワークロードに対応するものとしては、以下が挙げられる。
●インテル® AVX-512(Advanced Vector Extention 512):AIや数学など、演算負荷の高いワークロードを高速化する新たな命令セット。
●インテル® AMX(Advanced Matrix Extention):行列計算処理を効率化し、ディープラーニングの学習や推論を高速化する命令セット。
●インテル® DSA(Data Streaming Accelerator):ストリーミングデータの移動/変換処理を高速化するアクセラレーター。
AVX-512は、1ステップ(1クロック)で処理できる命令種類の拡張、データを保持するレジスター数の拡張によって、より効率的に複雑な演算処理を実行できるようにする命令セットだ。たとえば分子動力学シミュレーションソフト「NAMD」に適用すると、AVX-512不使用時と比べて最大2.4倍のアクセラレーション効果があるという。
DSAは、CPUとメモリ/ストレージ/ネットワークとの間のデータ移動処理(コピーや変換、チェックなど)を実行するアクセラレーターだ。専用アクセラレーターのDSAに処理をオフロードすることで、データ移動パフォーマンスを向上させると同時に、CPUコアの処理負荷が低減される。
メインメモリとして使える広帯域幅メモリを内蔵したXeon® CPU Maxシリーズ
ここまでの説明は、第4世代 インテル® Xeon® スケーラブル・プロセッサーに共通する特徴だ。これらに加えて、“HPCワークロード専用”であるインテル® Xeon® CPU Maxシリーズはさらに大きな特徴を備えている。HBM2eメモリの「内蔵」だ。
通常のプロセッサーはメインメモリを外部に持ち、外部I/O(メモリバス)経由でデータをやり取りする。この処理にはわずかながらもオーバーヘッドが発生する。メインメモリをパッケージに内蔵すれば、このオーバーヘッドも削減できる。
こうした考えから、インテル® Xeon® CPU Maxシリーズでは業界で初めて、最大1TB/sの広帯域なHBM2eメモリを内蔵している。その総容量は64GBであり、1コアあたり1GBを超える大きなものだ。
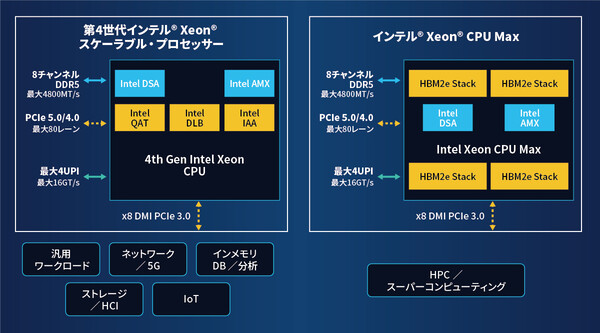
第4世代 インテル® Xeon® スケーラブル・プロセッサー、インテル® Xeon® CPU Maxシリーズに適したワークロードの違い
この内蔵HBM2eメモリは、ワークロードに応じて3つの使い方(モード)ができる。メモリ使用量が合計64GB/1コアあたり2GBに満たないワークロードでは、超高速なメインメモリとして使用できる(HBM Onlyモード)。一方でメモリ使用量がより大きいワークロードの場合は、外部DDRメモリと結合してメインメモリの容量を拡張させたり(HBMフラットモード)、外部DDRメモリ上のデータをキャッシュしてパフォーマンスを向上させたり(HBMキャッシュモード)することが可能だ。
なお、この内蔵メモリを使用する際に「コード変更の必要がない」こともメリットと言えるだろう(HBMフラットモードのみ、修正が必要な場合がある)。既存のHPCソフトウェア資産をそのまま生かして、より高速な処理が実現できるからだ。ちなみにインテル® Xeon® CPU Maxシリーズは、第4世代 インテル® Xeon® スケーラブル・プロセッサーと同じソケット構成を持っており、CPUを変更する場合でもコード変更の必要はない。
* * *
今回は、主にインテル® Xeon® CPU Maxシリーズの特徴を見てきた。“HPC専用”のワークロード特化型プロセッサーとして強い個性を放つこの新製品には、大きな期待が持てる。
ある国立大学では、新たなスーパーコンピューターシステムの構築において、HBM2eメモリ内蔵によるパフォーマンス向上を目的としてインテル® Xeon® CPU Maxシリーズの採用を決めたという。今後もこうした採用事例が続くことになりそうだ。
なお、本記事ではインテル® Xeon® CPU Maxシリーズを“HPC専用”と表現したが、前回紹介した第4世代 インテル® Xeon® スケーラブル・プロセッサーの特徴も合わせ持つため、HPCワークロード以外でも高いパフォーマンスを発揮できる。誤解を生まないように書き添えておく。
6月19日、20日
技術とビジネスをつなぐ「Intel Connection 2023」開催!
参加登録(無料)受付中

「技術とビジネスをつないで新しいことを始めよう」をメインテーマに、業界の垣根や技術者/経営者の枠を超え、企業間の連携を高めてDcXをさらに推進し、日本の次世代を育て、未来を創るカンファレンスイベントです。
2日間、4つの基調講演と8テーマの分科会(AI、DX、サステナビリティー、教育、自治体の取り組み、デバイスソリューション、データ&インフラストラクチャー、イノベーション)、ソリューション紹介展示を行います。ぜひご来場いただき、新たなビジネスを創出する場としてご活用ください。
・開催日時:2023年6月19日(月)、20日(火)09:30~17:30
・会場:東京ミッドタウン ホール A+B(東京・六本木)
・主催:インテル株式会社
・入場料:無料(事前登録制)
(提供:インテル)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
sponsored
AI/データ分析ワークロードを「効率的に」処理できる第4世代 インテル® Xeon® スケーラブル・プロセッサー -
sponsored
第4世代 インテル® Xeon® SPが5G/ネットワークのイノベーションを加速させる - この連載の一覧へ



