




AuroraはMCR-DIMMを採用
ADATAが早くもサンプルを展示
実はMcVeigh氏の説明、Auroraの構成などは最後であり、まずは同社のサーバー製品ロードマップやAI製品のロードマップなどだったのだが、その途中でさらっととんでもない話が出てきた。それが下の画像である。

バッファの分レイテンシーは通常のECC DIMMよりも増えると思われるが、それは致し方ないだろう
この話はインテルが初めてではない。今年3月にシリコンバレーにあるCHM(Computer History Museum)で開催されたMemCon 2023において、現在複数の企業によりMR-DIMM(Multi-Rank DIMM)の仕様策定作業が行なわれており、JEDECに標準化規格として提案されていること、およびそのMR-DIMMにAMDも賛同していることがAMDのRobert Hormuth氏(CVP, Architecture and Strategy, Data Center Solutions Group)によりLinkedInに投稿されていた。
もともとAMDはHB-DIMMという名前で同種の技術を開発しており、これをJEDECに標準化案として提案するにあたり、MR-DIMMに改称したらしい。そして5月にインテルがMCR(Multiplexing Combined Rank) DIMMとしてこれをGranite Rapids世代で正式にサポートすると表明するとともに、こちらもJEDECでの標準化に向けて活動しているとしており、DDR6が出てくるまでの中継ぎとしてMR-DIMMが少なくともサーバー向けには広く利用されそうな雰囲気になってきた。
MR-DIMMの基本的なアイディアは、ランクの多重化である。もともとDIMMの内部の管理単位にランクは広く使われていた。片面実装のDIMMでは1ランク、両面なら2ランク、というケースでは、表面のDIMMと裏面のDIMMでは別々のランクが割り振られており、どちらか片方(指定された側のRank)のみがアクセスされるといった形で利用されていた。ちなみにサーバー向けの大容量のDIMMでは、4ランクや8ランクのものも存在していた。
これを利用するにあたり、例えば連続読み出しであれば通常は下図のようにまずRank #0へのアクセスを行い、次いでRank #1にアクセスを行い、再びRank #0のアクセスを、という具合に交互にアクセスすることになる。
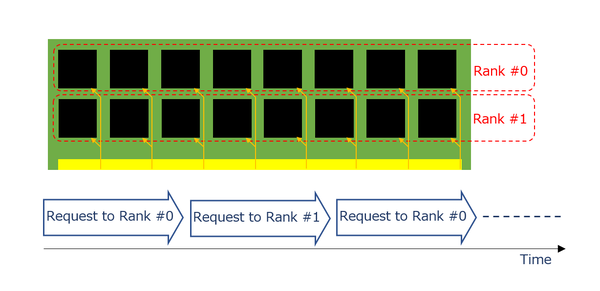
通常の連続読み出し
データバスそのものはRank #0とRank #1で共通であり、どのRank #をアクセスするか? という制御線でRank #0とRank #1を切り替える格好だった。
これに対してMR-DIMMでは、まずDIMMの上にバッファが乗り、ホストからのデータバスはすべて一旦このバッファで受けたあとで、Rank #0向けとRank #1向けが別々に配線される形となる。そしてデータバスには、Rank #0とRank #1へのリクエスト(とその返答)が同時に載る形になる。
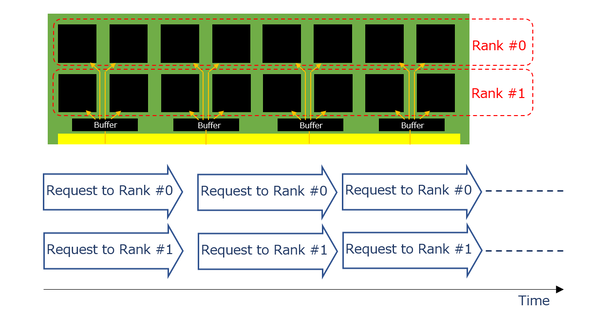
MR-DIMMの連続読み出し
要するにホストとバッファの間は信号速度を倍速とし、バッファと個々のDRAMの間は既存のDDR5の速度とする、という方式だ。これにより以下のことが実現できる。
- 既存のプラットフォームを変更せず、また新たなDRAMチップを開発することなく帯域を倍増できる。
- DIMMあたりの容量を倍増できる。
おそらくはこのMR-DIMMをサポートするプラットフォームでは、1 DIMM/chに制限されることになるだろう。ただすでにAMDのGenoaでは、2ソケットのプラットフォームは1 DIMM/chになっている(現実問題として2 DIMM/chにすると、DIMMスロットの面積が大きくなりすぎてシャーシに収まらない)し、インテルのGranite Rapids世代でDDR5 12chになる模様なので、やはり現実問題として1 DIMM/ch構成になるだろう。それに、MR-DIMMでは容量を倍増できるから、1 DIMM/chでも容量が少なくなることはない。
なぜ倍増させる必要があるかと言えば、現状AMDのGenoaは96コアとDDR5 12chという構成であり、次世代のTurinではおそらくさらにコア数が増える。となると、コアあたりのメモリー帯域を維持するためにはメモリー帯域を引き上げる必要があり、しかもDDR6を待っていられない。
これはインテルも同じで、Granite Rapids世代は最大132コアとされており、Sapphire Rapidsから倍増しているにも関わらず、メモリー帯域はDDR5 8ch→12chで1.5倍にしかなっておらず、現状ですでに帯域不足である。これを補うために帯域をより増やしたいし、DDR6を待ってられないと思うのは当然だろう。
ちなみにこのMR-DIMM、8800MT/秒なのは第1世代で、続いて12800MT/秒の第2世代、17600MT/秒の第3世代も想定されている。この第3世代は2030年台に投入予定で、さすがにこうなるとDDR6と被らないかやや心配になるところだ。
第2世代はDDR5-6400の倍速、第3世代はDDR5-4400の4倍速(つまりRank #0~#3までの同時アクセス)になるだろう。
さてこれがとんでもないのは、今年のCOMPUTEXでADATAがこのMR-DIMMのサンプルを展示したことだ。

ECC付きということで、80bit構成(32bitごとに8bitのECCが付くタイプ)ということでチップ数が巨大に。DRAMチップと端子の間にあるのが、MR-DIMM用のバッファと思われる

説明書き。最高速が8400MT/秒というのは、DRAMチップがDDR5-4200なのか、バッファチップがまだ8800MT/秒で動かないかのどちらか(後者な気がする)だろう
発表こそ今年の5月だが、水面下で開発は進んでおり、もうDIMMベンダーがサンプルを展示するほど完成度が高い、ということの裏返しである。
当然AMDも次のTurinでこのMR-DIMMのサポートを表明するものと思われる。6月13日にAMDは次世代データセンター/AIに関する発表会を開催するので、ここでなにか情報が出てくるかもしれない。
おまけ
第14世代CoreはDDR5-6400をサポート
そのADATAのブースでもう1つ展示されていたのが下の画像。なるほど、第14世代CoreはDDR5-6400をサポートするわけだ。

これを堂々と出しているあたりがなんとも……
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























