




膨大な元画像からキュレーションされたデータセット
ここからは少し専門的な解説になる。
従来の自己教師あり学習では、大量に用意されたデータをそのまま学習させていたが、ウェブからクロールされたデータセットの中には学習には無関係な画像が多く含まれているため効率が悪かった。また、特定の種類の画像が多いと「過学習」と呼ばれる現象が起こる可能性もあった。
25のサードパーティーから集められた12億枚のデータセット
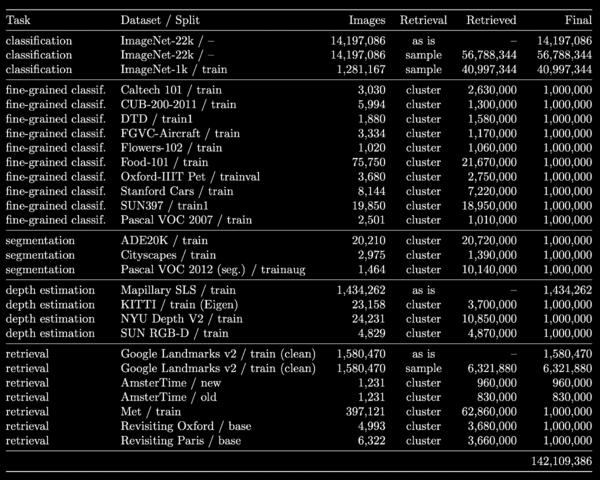
そこでDINOv2では、必要のない画像を取り除き、データセットのバランスを整えるキュレーションと呼ばれる作業を行なった。ただし、すべて手作業で行うことは難しかったため、約25のサードパーティデータセットの中から「種となる画像(seed images)」を手作業で選び、それを元に近い画像を検索することで必要な枚数を確保する手法を採用。これにより、12億枚の元画像のうち、1億4200万枚の画像からなる事前学習用データセットを作成した。
さらに、学習アルゴリズムや実装方法も改良を行なったことで、DINOv2はデータ、モデルサイズ、ハードウェアのスケーリングを実現し、同社比およそ3分の1のメモリ使用量にも関わらず、2倍の速度で動作するようになったという。
蒸留モデルを搭載した強靭な軽量モデル
高性能なモデルを使って推論を実行するには強力なハードウェアが必要となり、実用的な利用が制限されることがある。
この問題を解決するために通常「モデル蒸留(Model Distillation)」という圧縮技術が使用されるが、DINOv2は「自己蒸留(self-distillation)」という手法を採用し、最も性能の高いモデルをかなり小さなモデルに圧縮。わずかな精度の犠牲で、推論コストを大幅に削減している。
その結果、今回公開されるのはViT-g/14(11億パラメータ)とViT-L/16(3億パラメータ)の事前学習済みコードとレシピに加え、大規模なViT-g/14から小さな蒸留モデル(ViT-S/14, ViT-B/14, ViT-L/14)までの事前学習モデルに関するチェックポイントまで含まれている。
LLMと組み合わせることによって広がる未来
今後、研究チームはDINOv2を同じくメタAIが開発した「LLaMA」のような大規模な言語モデルと対話できるような、より大規模で複雑なAIシステムに統合することを計画している。
これにより近い将来のLLaMAを使用したサービスではDINOv2経由で初見の画像からも特徴を正確に抽出することができるため、真にマルチモーダルなLLMが可能になると思われる。
例えば、一枚(または一連)の画像から物語を創造したり、逆に与えられた物語にふさわしい画像を生成したりといったことが考えられる。
マイクロソフト(OpenAI)やグーグルに比べ、AI関連の話題はあまり多くなった印象があるメタだが、この優れた基盤モデルをマネタイズせずオープンソース化したことは、AI開発者コミュニティへの大きな貢献になるだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















