




フラッシュメモリーを使わず
CMOSプロセスだけで実現できる
小型化については実験の結果からも示されている。下の画像はテストチップおよびシミュレーションの結果である。
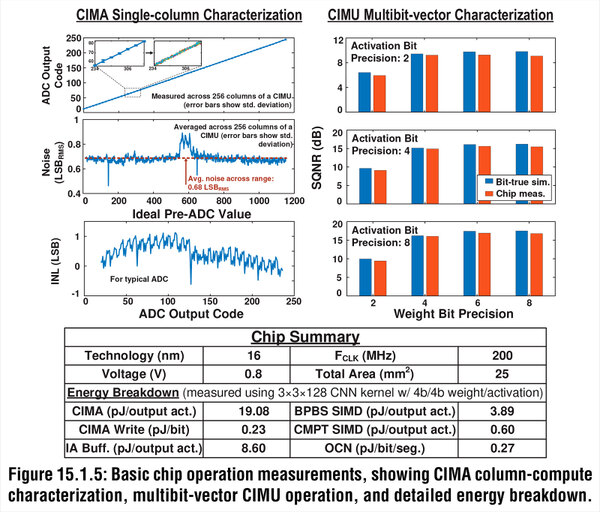
このSQNRの結果を見れば、商品化に際してはもっとコンデンサーの容量(=コンデンサーの占める面積)を微細化しても問題なさそうで、演算/記憶密度をさらに引き上げられそうである
左上は、1つのコンデンサーに入力した電荷とその出力であり、きれいに直線的な関係にあることが示されている。その下の2つはADC(Analog/Digital Conversion)にかける前とかけた後の信号とノイズの関係で、非常にノイズが少ない(=入力した値をそれほど補正をかけずに出力として使える)ことを示している。
右はActivation BitとWeight Bit(アクティベーションと重み、それぞれの精度)とSQNR(Signal-to-Quantization-Noise Ratio:量子化を行なった後の信号とノイズの比率)である。
EnCharge AIの方法では、重みを8bit(つまり256段階)で取った場合でも、SN比が15dB(つまり信号とノイズの比が32倍弱)という、非常に大きなマージンが取れることになる。これはフラッシュベースのCIMではなかなか実現できない数値である。
上の画像の下部の表にもあるように、TSMCの16nmで試作したチップは5mm角とそれほど大きいものではないが、重要なのはこれが組み込みフラッシュを利用しない普通のCMOSプロセスだけで実現できることである。したがって、今回はTSMCの16nmでの試作だが、この先10nm/7nm/5nmと微細化することになんの問題もない。
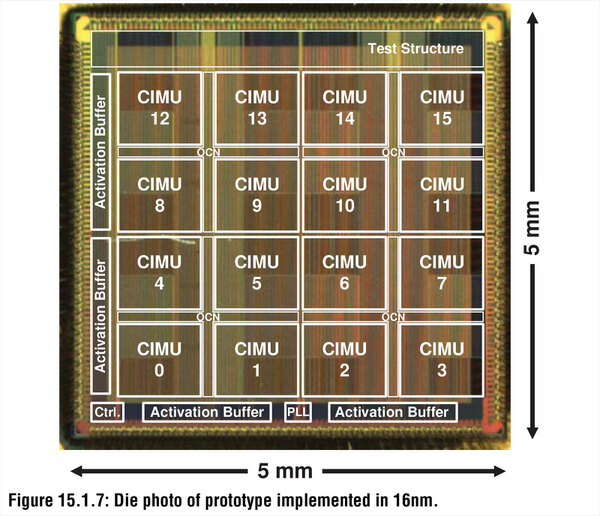
TSMCの16nmで試作したチップ。CIMUのサイズはおおむね1×1mm(もう少し小さいくらい)であることがわかる
強いていうならばコンデンサーの構築に配線層を使う関係で、7nmあたりまでは微細化の効果は大きそうだが、その先は配線層の微細化が止まりかけている関係もあってそれほど効果はなさそうだが、この試作チップでは121TOPS/Wという驚異的な数字を叩き出しており、他の方式と比べても遜色ない構成であることがわかる。
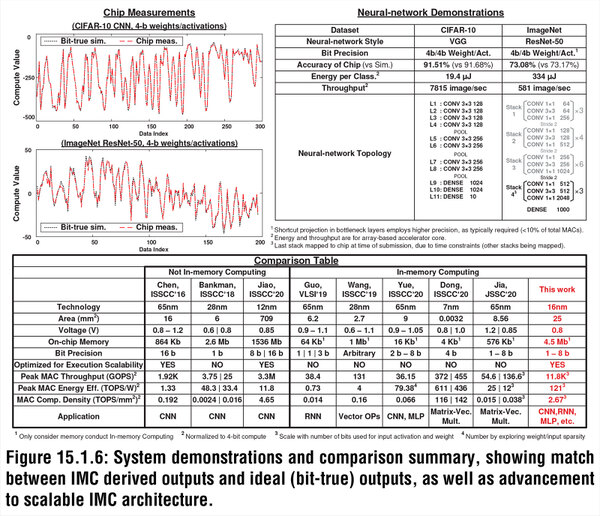
下段の表の赤いのが今回の結果。従来発表されたものと比較しても非常に優秀な数字であることがわかる。また、上段左のグラフで、シミュレーションと実際のチップの振る舞いが高い精度で一致しているのも特徴的である
ここまでの発表はあくまでも研究の枠を出ないものであったが、すでにEnCharge AIは製品化に向けての最初の試作チップを完成させており、製品化に向けて着々と進んでいる。

プロトタイプチップが搭載された評価ボードを手にするVerma教授
この試作チップ、ずいぶん大きなものに見えるのだが、EnCharge AIのサイトに掲載された写真がこの試作チップのものだとすれば、これはPGAパッケージを使っているので極端に大きいのであって、チップそのものは相当小さいように見える。

EnCharge AIのサイトに掲載された写真。一見すると4つのCIMUを組み合わせた塊が16個(つまり全体で64 CIMU)に見えるが、この見立てが正しいかは不明。ずいぶんOCNの面積が大きくなっているようにも思える
ちなみにこのチップは150TOP/Wを超える効率を発揮する予定、とされている。無事に製品化にこぎつけるまでにはまだいろいろ障害はあるだろうが、乗り越えてがんばってほしいところだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























