




今週お届けするのはKinaraなのだが、この会社は少なくとも2022年3月まではDeep Vision, Incという社名であった。ただインターネットアーカイブで調べると、2022年5月以降はKinaraにウェブページがリダイレクトされるようになっている。4月か5月あたりに社名変更をしたらしいが理由は不明である。なにしろ社歴を見ても社名変更の理由どころか、Deep Visionの名前すら出てこない有様である。

創業者はRehan Hameed博士(当初はCEO、現在はCTO)とWajahat Qadeer博士(Chief Architect)の2人。両博士とも、KinaraというかDeep Vision創業前はスタンフォード大学で研究助手を務めており、どうもこの頃に出会ったらしい。
実は両博士は共同でいくつかの論文を出しており、この論文で論じた仕組みを商用化するために作ったのがDeep Visionだったようだ。もっとも最初の論文である“Understanding sources of ineffciency in general-purpose chips”は筆頭著者がHameed博士、共著者がQadeer博士のものだが、これは文字通り汎用プロセッサーの不効率性を分析したもので、この際のターゲットはH.264のエンコードの際の効率を論じたものである。
ただこの後、2013年に出された“Convolution engine: balancing efficiency and flexibility in specialized computing”は、今度は筆頭著者がQadeer博士、共著者がHameed博士になっているが、文字通り畳み込み処理を効率的かつ柔軟に行なうための仕組みについて論じたものであり、これが同社のARA-1チップの基本になっている。
その論文の中身であるが、これもやはりH.264のエンコードを高速化するというテーマである。2013年に発表された論文なので、まさに論文を書いている最中に2012年のILSVRCでトロント大のImageNetが出てきたタイミングであり、まだこの時点ではAIを意識していなかったものと思われる。
そもそもH.264のエンコードで9割以上の作業はMotion Estimation(動き推定)である。これは前フレームの画像と現フレームの画像を比較して、その画面の中(あるいは画面全体)の動きベクトルを計算するものだが、通常は画像ブロック(4×4ピクセルや8×8ピクセルなどが一般的だが、もっと違うサイズのブロックの指定も可能)単位で、フレーム間でどこに動いたかを比較するわけで、比較というのは前画像のあるブロックと同じ(あるいは近い)構成のブロックがどこにあるかを現画像を舐めて推定するという、大変に手間のかかる作業である。
もちろんいろいろ高速化の技法はあるが、高速化と精度の低下がバーターの関係に近いため、あまり大胆な高速化は画質の劣化やデータ量の増大につながる。したがって画質を保ち、データ量を増やさないためには愚直に画像比較を行なうしかない。この画像比較が全体の9割を占めているというわけだ。
で、この画像比較に畳み込みを使うのだが、畳み込みと言うのは例えば下の画像の左側のような処理になるわけで、これを一気に行なえるような「超命令」を利用すれば処理量が減る、というのが論文の骨子である。
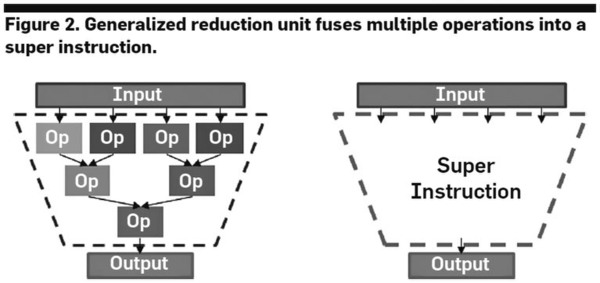
畳み込みの処理。Super Instructionには笑ってしまったが、実際そういう話である
実際には畳み込み「だけ」で動き推定が行えるわけではないが、動き推定の中で畳み込みの処理量がかなり多いのは事実で、これを効率化することで高性能と低消費電力化が図れるとする。
実際に8×8の2次元SAD(Sum of Absolute Difference:差分絶対値和)を計算するための構成が下の画像だ。

8×8で64ピクセルのブロック同士の値の引き算(絶対値)を行ない、その総和を求める。この総和が0に近いほど、似たブロックであると判断できる
ちなみに動き推定というのは、あるブロック同士の比較をして終わるわけではなく、例えばSD映像(720×480)なら極端な話、34万5600回の比較することになる。この際に毎回前画像のブロックと現画像のブロックをロードするのは非効率なので、元画像のブロック(2D Register)と、現画像のブロック(2D Shift Register)のデータは再利用できるように工夫されている。
元画像は8×8ピクセルなのに、現画像は16×8ピクセルになっているのがそれで、この2D SADエンジンでは横8ピクセル分の移動のベクトルを4サイクルで算出できることになる。この2D SAD以外の動作にも対応した畳み込みエンジン(Convolution Engine)と呼ばれるものの全容が下の画像だ。
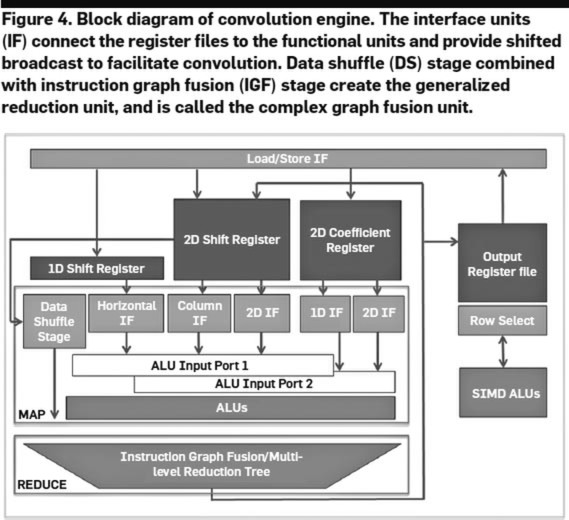
上の画像のままでは本当にSADしかできないが、もっと広範の処理をできるように工夫したのがこちらということになる
SADでいうなら、MAPが8×8で64個のピクセル単位の差の絶対値を計算する部分、REDUCEがその総和を取る部分で、畳み込みなら乗加算をMAPで、その後の活性化やサブサンプリングがREDUCEに当たる部分になる。
実際に論文の中では、(ちょうどこの論文が出たころにCadenceに買収された)CPU IPのベンダーであるTensilicaがリリースしていたシミュレーションプラットフォームを利用してこの畳み込みエンジンを実装した場合の評価をしており、専用のASICに比べれば効率はやや落ちるものの、SIMDを利用した場合に比べると大幅に効率が良かったことを報告している。
この論文が出た頃には第3次AIブームが巻き起こっており、しかもそこで利用されている技術は、両博士が得意としていた畳み込み演算が主体である。であれば当然利用できるはず、と考えたのは不思議でもなんでもない。そこで、AIプロセッサーの構築に向けて立ち上げたのがDeep Visionというわけだ。
ちなみに冒頭で当初のCEOはHameed博士と書いたが、スタートアップ企業のCEOにはさまざまなビジネス上の面倒ごとが降りかかってくる。それもあってか、2015年3月からはAppleでGroup Product Managerを務めていたJason Copeland氏がCEOとして参加した。
同氏は、複数のベンチャーからの出資を受けたり、ビジネスプランの策定やスタンフォード大のStartXというベンチャー支援プログラムへの参加、最初のプロトタイプチップ作成あたりまでに付き合い、2017年1月に離職している。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ


















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












