
2次キャシュを倍増
最後がロード/ストアーユニットである。基本的にはこちらもZen 3のままから変わっていないが、Load Queueが72 Entryから88 Entryに強化されているのが違いとなる。また、L2 Data TLBが2K Entryから3K Entryに強化されている。
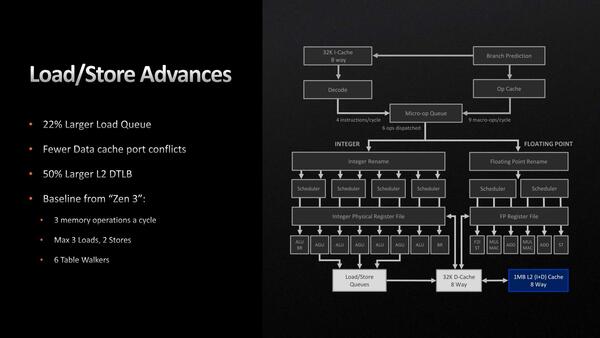
Store Queueの方は64 Entryのまま変更がない
“Fewer Data cache port conflicts”に関しては詳細な説明がなかったが、よりポート同士の競合が少なくなるような工夫が施された模様だ。
パイプライン外部で言えば、L2が512KBから1MBに増量された。単に増量されただけでなく、同時に多くのoutstanding miss(Cache Missが発生し、L2ならL3に、L3ならメモリーにそれぞれCache Fillを要求する動作のこと:これが同時に多発した場合、Cache Fillが解決するまでキャッシュそのもののアクセスが止まることになる)を扱えるようになったとしている。
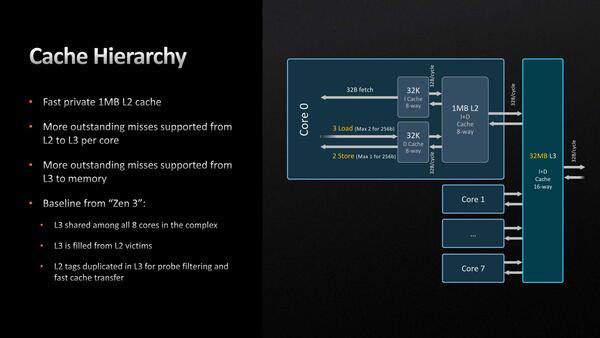
このL3は、将来は3D V-Cache付きモデルで96MBまで増量できるものと考えられる。L2とL3が排他構造なのは変わらず
ちなみにこの代償として
L2 Latency 12サイクル→14サイクル
L3 Latency 46サイクル→50サイクル
と微妙にCache Accessのレイテンシーが増えてしまっているが、そもそもL2を倍増した時点である程度レイテンシーが増えるのは避けられないわけで、このあたりはバーターということになるだろう。
以上簡単にZen 4の内部構造の違いを紹介してきたが、まとめれば「Zen 3の4 x86命令/サイクルのコアの実行効率を、さらに高めた」ということになる。5 x86命令/サイクルはZen 5以降までお預けで、それ以前にまだ4 x86命令/サイクルでやれることがあり、それを全部実装したという感じになっている。
実際IPCの比較で言えば平均して13%程の向上とされるが、そのIPCの増分の内訳が下の画像だ。最大のものはフロントエンドで、ついでロード/ストアー、Branch Predictrionときて、Execution Unitの改良やL2キャッシュの増量などは一応効果がないわけではないが、フロントエンドに比べるとその効果はわずかである。それだけフロントエンド周りの改良が大きかった、というわけだ。
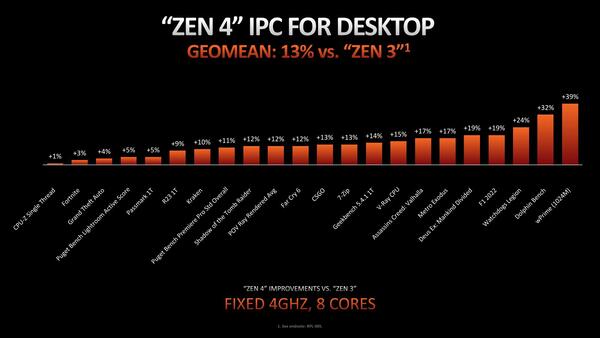
13%の根拠。ものによってはあまり性能が上がらないケースもある一方、4割近くまで向上するものもある
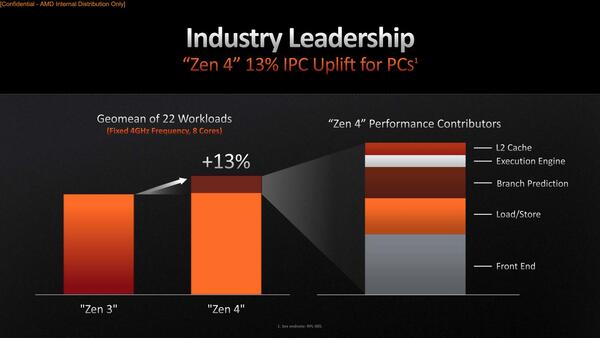
Execution Engineに関して言えばもうFPU周りがほとんどで、あとはALUも若干改良があるようではあるが、大きなものではないとされていた
ちなみにAVX-512周りの性能比較が下の画像だ。ONNX Runtime Performanceで1.3倍~2.5倍とされる。

FP32はAVX512を使わないケース、INT8はAVX512_VNNIを使ったケースとなる
もちろんこれは大きな性能向上ではあるのだが、そもそも元のRyzen 5000シリーズでの性能が低い事を考えると、確かに性能は向上したとは言えどの程度使えるのか、というのは微妙な線だ。まぁそのあたりが判っているから、Zen 5ではXDNAとしてAI Engineを統合することにしたのであろう。
Zen 4世代ではもう1つ大きな違いとして、GPUコアの統合が挙げられる。これはCCDではなくIODの方に統合される形である。

IODの構成。そういえば従来の統合GPUと異なり、「ディスクリートGPUを使っていても、VCN(Video Core Next:動画エンコーダー/デコーダー)を利用できる」という説明があったのだが、試すのを忘れていた。試さねば
その内部だが2CU、つまり1 WGP構成である。要するにRDNA 2の最小構成である。またディスクリートのRDNA 2製品と異なり、以下のようになっている。
- インフィニティ・キャッシュは搭載されない
- レイトレーシング・エンジンも搭載されない

ローエンドのわりにACE(Asynchronous Compute Engine)が4つもあるのがやや不思議ではある
本当にデスクトップの表示には十分だが、これでゲームをやるのは厳しい程度と考えておけば良いだろう。ということで駆け足であるが、まずはZen 4の内部構造をお届けした。まだRyzen 7000シリーズでは説明すべきことがあるのだが、それは別の記事で。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ













