




TF32+という独特なフォーマットをサポート
次がT-coreである。こちらも詳細はあまり明らかになっていないのだが、MMA(行列乗加算)や畳み込みを高速化する、というあたりはNVIDIAのTensor CoreやAMDのMatrix SIMD、インテルのXMXなどと同じもののようだ。
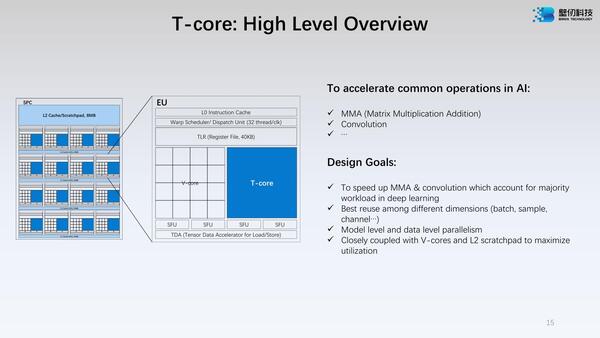
強いて違いを挙げるとすれば、競合製品よりユニット数が少ないというあたりだろうか? といっても16SPC×16EUでダイあたり256個だから十分と言う気もする
このT-coreはMMAを行なえるから、GEMMなどの科学技術演算にも使えることになる。もっとも最大でもFP32だから、科学技術計算といっても使えるところはやや限られることになるが。

これは要するに16個のEUのT-Coreを連携させて動かすことで、効率的にGEMMの演算が可能になるという話である。それを示すのに2.5Dと表現しているあたりはわからなくもないが、少し違う気もする
このT-Coreで特徴的なのは、TF32+という独特なフォーマットをサポートしていることだ。大昔のATIのGPUは内部が24bit構成になっており、これでFPを扱うとFP24になっていたし、最近だとAchronixのFPGAは内部でFP24をサポートしているから全然例がないわけではないが、あまり一般的ではない。

普通はこれはFP24と言わないだろうか?
TF32に比べると仮数部が10bit→15bitに増えているぶん、精度が32倍向上しているとは言っても、そもそも仮数部の精度を上げてもそれほど全体としての精度向上につながらないからこそ昨今のAIプロセッサーは学習でもTF32やBF16などを使うようになっていることを考えると、これのメリットがどこまであるのかははっきりしない。
ただ記事冒頭の画像にもあるように、TF32+を使うとピークパフォーマンスがFP32に比べて倍になっているあたりは、性能と精度のバランスを取る上でサポートした方が良いと判断したのだろうが、このあたりはトレードオフの結果をグラフかなにかで示して欲しかった気もする。
また前ページの2つ目の画像を見ると、EUの一番下にTDA(Tensor Data Accelerator)と呼ばれるユニットが配されているが、その詳細が下の画像だ。
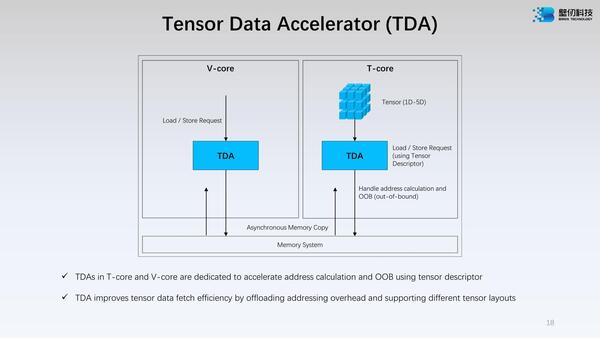
TDAの詳細。この説明だけ読むと、TDAはT-core/V-coreからのリクエストを分析して、ある種のプリフェッチに近い処理まで行なうようにも読めなくもないのだが、実際のところどの程度まで自動的に処理を行なえるのかはやや不明である
V-coreの場合は明示的にcoreからのロード/ストアー命令を受けて動く形だが、T-coreの場合は次の演算が始まる前に自動的にロードが、演算が終わるとストアーがそれぞれ発行されるようで、そのリクエストに応じてアドレス計算とかOut-of-bound Accessの制御などを自動的に行なってくれる仕組みだ。
要するにCPUコアのLSUやAGU(Address Generation Unit)などが行なっている役割だが、通常のLSUやAGUと異なるのは、これがV-coreやT-coreと独立に動くことと、T-coreの場合はTensor Descriptor(どんな形でデータを格納する/格納されるか)を自身で判断することだろうか。
またBR100では、2次キャッシュおよびメモリーに関して、それをUMAで扱うことも、NUMAで扱うこともできるのもやや珍しい。アクセスの効率化を考えれば、個々のSPCは自分のローカルのメモリー(2次キャッシュの一部)を排他的に扱うのが一番良い。
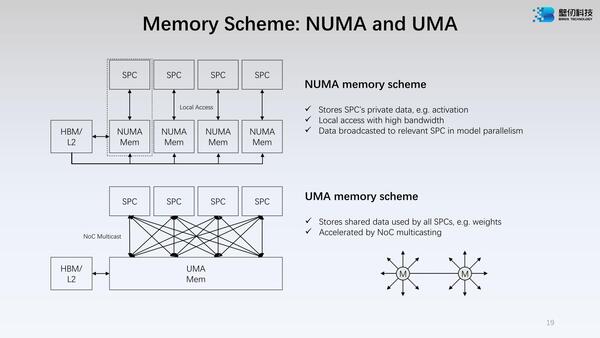
もともと2次キャッシュの一部はスクラッチパッドとして扱うことも可能であり、ここで言うNUMA Mem/UMA Memはそのスクラッチパッド領域を指すと思われる
これだと複数のSPCで処理を分担する際に、一度HBMなり2次キャッシュ経由でデータの転送を行なうことになり、場合によってはむしろ効率が落ちる。そうした場合に、すべての2次キャッシュというかローカルメモリーをUMA的に扱えるようにすれば、むしろ効率が良くなるという話である。
ただこれを混在できるのか(例えば3つのSPCはUMAとして扱い、残りの1つはNUMAのままにできるか)は不明である(なんとなくできなそうな気がする)。
もう1つ、よくわからないのがReduction Engineである。そのReductionの説明が下の画像だ。
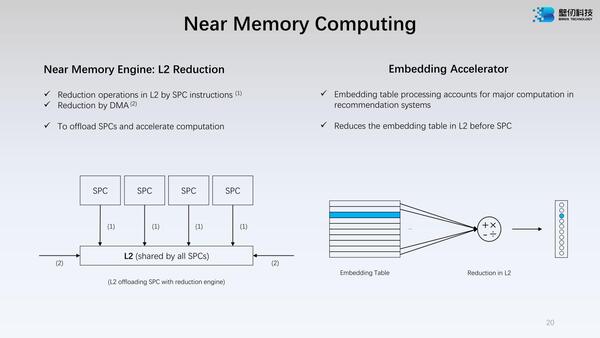
Embedding Acceleratorの方は、テーブルの計算をSPCに渡す前に2次キャッシュ内で済ませてしまうという、Computation Memory的な動作を目指しているように見える
最初は可逆圧縮メカニズムかなにかと思ったのだが、この左側を見る限り、複数のSPCが同一のメモリー領域をアクセスするようなケースでは、単一の2次キャッシュ領域を共有するようにすることでデータの重複持ちを避けるということらしい。
共有2次キャッシュなら当然では? と思うかもしれないが、BR100/104の場合はNUMAモードもあるから、基本SPCごとに2次キャッシュにデータをロードすることになる。
ところがUMAモードの場合は、Reduction Engineが「どこの2次キャッシュにそのデータがあるか」を把握して、重複して持たないような工夫が施されるようだ。またTable Lookupを高速化するアクセラレーターも搭載されているようだ。
なんというか、GPU的な構造を持っている部分もあるが、全体としてみるとGPUというよりはやはりAIプロセッサー的な色合いが非常に濃いもので、ターゲットはやはりAIプロセッサー向けであろう。HPC向けにはあまり向かない構成である。
問題はこれがいくらで販売されるか? というあたりだろうか。NVIDIAのH100やAMDのInstinct MI200/300、あるいはインテルのPonte Vecchioなどに比べると全体的には保守的な構成で、こうしたハイエンドGPGPUにはピーク性能ではおよばないが、その分安ければ“Poorman's DGX”的な位置付けで売れそうには思う。
中小クラウドプロバイダーなどでは、案外導入の余地はありそうに思う。ただフルに性能を発揮しようとすると、BR100/104独特のメカニズムをきちんと使ってやる必要がありそうで、そのあたりに少し難があるかもしれない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























