




IPUは7296スレッドの同時実行が可能なMIMDプロセッサー
下の画像がそのIPUの中身である。1つのIPUには1216のタイルがあり、それぞれのタイルはIPU-Coreと呼ばれるプロセッサーと256KBのSRAMから構成される。
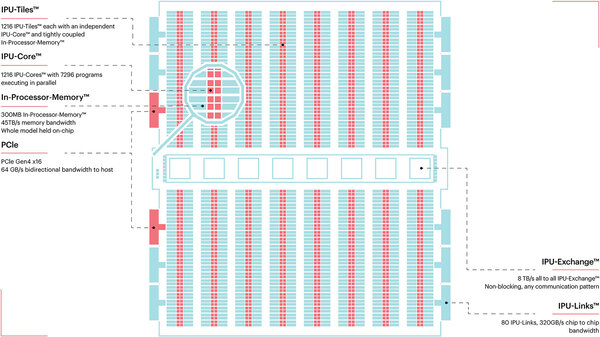
中央のブロックがIPU-Exchangeで、要はIPU-Core同士をつなぐ巨大なファブリックである
IPU-Coreは、同時に6つの実行コンテキストを保持できる。要するに6スレッドのSMT的な動きが可能になっている(厳密な意味でスレッドと言えるかどうかは議論があるところだが)。ということは1216×6=7296スレッドの同時実行が可能、という壮大なMIMDプロセッサーである。
ちなみにIPU-Coreのパイプライン構造などは公開されていない。ただ演算ユニットはかなり強力である。1216プロセッサーの合計処理性能はFP32で31.1TFlops、Mixed Precision(乗算は16bit、加算32bit)だと124.5TFlopsとされる。
IPUそのものは1.6GHz駆動とされるので、1サイクルあたり16Flops/プロセッサーの処理性能となる。つまり同時に16個のFP32演算が可能なわけだ。Mixed Precisionでは64演算ということになる。これは32bit×32bitの乗算器を4×16bit×16bitに構成できる、という話であろう。演算そのものはベクトル化されており、SIMD演算的に実行できるようだ。
これにつながるローカルメモリーはスクラッチパッドとして扱われる。そもそもIPUの場合、共有メモリーとなるものは一切存在せず、各IPU-Coreは自身につながった256KBのローカルメモリーがすべてである。したがって命令もデータも全部ここに収める必要がある。
これで不足する場合は、Exchange Phaseのタイミングで他からデータを持ってくるという動き方になるので、逆にどうやって256KBに収めるかが腕の見せどころではある。ただこうしたMassive Parallelの構成では1つのプロセッサーに長大なプログラムを実行させることは普通あり得ないから、むしろデータをどうやって収めるか、というあたりが最適化のポイントとなる。
ちなみにC2 IPUは単体というよりも2チップ構成で動くことを当初から想定しているようで、この2チップで2400コアあまりのIPU-Coreと608MBのSRAMを搭載するという、超Massive Processor構成となっている。
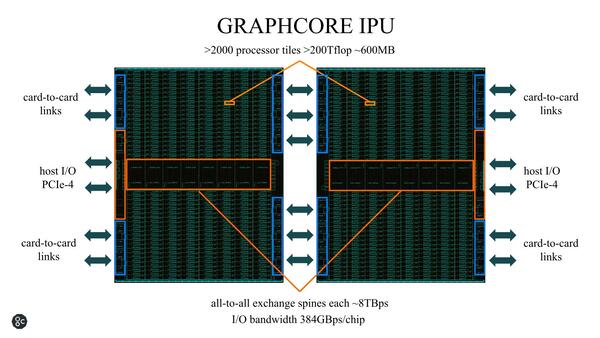
1枚のカードにC2が2つ搭載されるが、このカードを複数接続することを前提に、320GB/秒の帯域を持つIPU-Linkも搭載されており、PCIeとは別にこちらを利用して接続できるようになっている
さてこのC2 IPUの性能は? であるが、GraphCoreが当初発表していたのは、ResNet-50のトレーニングを16000枚/秒で処理するために必要なリソースは以下の通り。
| GraphCore | C2 IPUカード(C2が2つ搭載)×8枚 |
|---|---|
| NVIDIA | Volta V100カード×54枚 |
また2018年からは製品出荷されていたこともあり、いくつかの論文も出ている。例えば“Studying the potential of Graphcore IPUs for applications in Particle Physics”によればGAN(Generative Adversarial Networks)を実行する速度を以下の4つで比較した結果が下の画像だ。
| CPU1 | Intel Xeon Platinum 8168 |
|---|---|
| CPU2 | Intel Xeon E5-2680 v4 |
| GPU | Nvidia TESLA P100 |
| IPU | Graphcore Colossus GC2 |
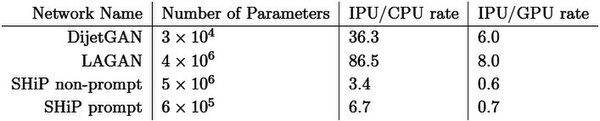
SHiP(The Search for Hidden Particles)experiencceは欧州のCERN(欧州原子核研究機構)における、タウニュートリノの検証を行なう実験計画。ここで利用されているのが下の2つのGAN Networkである
SHiP Prompt/Non-Prompt GANに関してはややGPUに後れを取っているが、CPUに比べれば圧倒的に高速だし、DijetGAN/LAGANなどではGPUと比べて十分に優位性がある、という結果である。
あるいは2020年末に“Hardware-accelerated Simulation-based Inference of Stochastic Epidemiology Models for COVID-19”という、新型コロナウイルスの疫学モデルをシミュレーションで実施したという論文では、C2 Card×2とTesla V100、Xeon Gold 6248×2と比較して圧倒的に高速であるという結果が示されるなど、単にAI以外の用途にも利用できることなどが示されている。
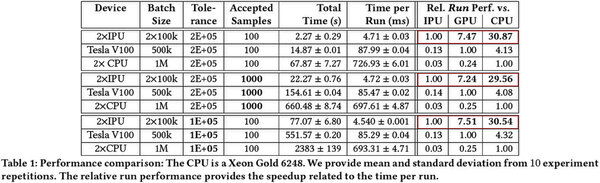
赤枠は筆者が追加。この赤枠部分がGPUないしCPUとの相対性能ということになる
さて、この第1世代IPUはTSMCの16nmで製造されていたわけだが、数回にわたる資金調達のおかげもあり、無事に第2世代IPUを2020年7月に発表した。

Colossus Mk2 GC200 IPU。一見するとMk1とよく似ているが、ダイの脇にあるコンデンサーの配置などが大きく異なる
第1世代のC2ことColossus Mk1 GC2 IPU(第2世代の投入に合わせて名前が変わったようだ)は16nmプロセスで236億個のトランジスタを集積、ダイサイズは700mm2を超えていたが、第2世代のColossus Mk2 GC200 IPUではTSMCの7nmプロセスに移行。ダイサイズは823mm2、トランジスタ数は594億個と、ほぼTSMCで製造できる限界に近いサイズに挑戦している感がある。
ただ内部構造を見ると、Mk1とよく似ている。IPU-Tileの数は若干増えて1427個になり、またタイルあたりのSRAM容量は256KBから624KBに増量されている。この結果、IPUのSRAM容量は900MBに達している。
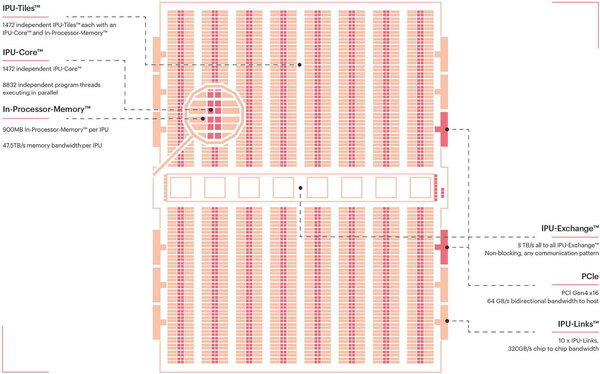
Mk2の内部構成。基本的な構造そのものは同じに見える
その一方で、性能に関しては「実際のアプリケーションの場合でMk1の8倍の性能に達する」としている。ここでのポイントは「同じ演算処理を8倍高速に実行する」とは言ってないことだ。

これはそもそもMk1を2つ搭載したPCIeカード×8 vs Mk2を4つ搭載したM2000×8なので、まずチップの数からして違っているのだが
例えばBERT-Large Trainingであっても、同じ精度で実施しているとは一言も言っていない。Mk2では従来のFP32およびMixed Precision(FP16.32)に加え、FP16.16(乗算・加算ともに16bit)およびFP16.SR(確率的丸め処理付きFP16)を追加しており、データ型としてこちらを使っている可能性もある。実際4×Mk2ではFP16.16で1PFlopsの演算性能と同社は説明しており、Mk2が1つあたり250TFlopsである。これはFP16.32で124.5TFlopsだったMk1の2倍になる。
またMk1では、バッチサイズが大きくなると256KBのSRAMでは足りなくなって性能が低迷する傾向が見えていたが、これがSRAMの大容量化で大きく緩和された可能性もある。
これに加えてMk2世代ではシステムレベルでの強化も行なわれた。Mk1世代はPCIeカードでの提供のみだったが、Mk2世代ではIPUを4つ搭載した1UのブレードサーバーであるIPU-M2000として提供されることになった。

Mk1世代。ものすごい見かけであるが、2スロット厚のPCIeカードである

Mk2世代。中央に4つ並ぶヒートシンクの下にそれぞれColossus Mk2 GC200 IPUが鎮座している
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ


















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






































