




2021年中旬にサンプルを出荷予定の
Tenstorrent Wormhole
連載599回で紹介したTenstorrent、最近では4月22日に、次世代製品にSiFiveのX280プロセッサーを採用することを発表するなど、着々と将来の製品に向けての布石を打っている。
X280そのものは8段のパイプラインを持つDual-Issue/In-OrderのRV64(64bit RISC-V)プロセッサーだが、最大の特徴はRVV(RISC-V Vector Extension)に対応したことだ。このVector Extentionは特に機械学習向けを意識してBF16/FP16・32・64/INT8・16・32・64の各データ型に対応。Vectorサイズは512bitになっており、最大で64演算が1サイクルで可能になっている。
もっとも、Tenstorrentは次世代製品をこのコアをベースにする、というよりは既存のJawbridge/Grayslullともにアプリケーションプロセッサーとして4コア構成のARC CPUを搭載しており、これをこのX280で置き換えるつもりなのではないかと筆者は想像する(まだTenstorrentはX280の使い方を公開していない)。
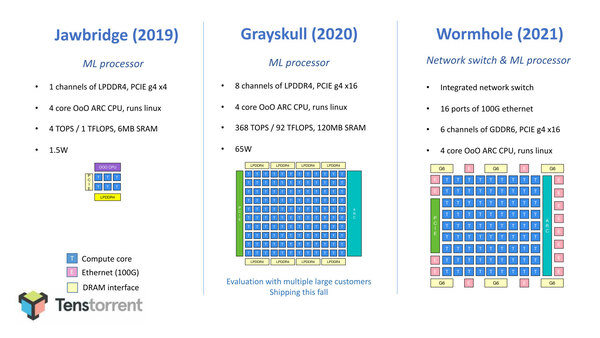
JawbridgeとGrayslullはアプリケーションプロセッサーとして4コア構成のARC CPUを搭載している
それはともかくとしてそのTenstorrent、LSPC 2021では連載599回の最後で触れたWormholeの詳細を公開した。上の画像にもあったが「Jawbridge:6コア(プロトタイプ)」と「Grayskull:120コア」 という構図になっていたが、Wormholeはむしろコアそのものは80に減っている。

いろいろ図を間違えているようで、上の画像ではGraySkullのCompute Coreが80個、こちらのスライドでは120個が記載されているが、実際はWormholeが80個となる。その代わりメモリーI/FはGDDR6×6に増え、PCIeに加えて16ポートの100Gイーサネットを搭載した構造である
なぜコア数が減るかと言えば、以下の理由があるからである。
- 学習向けに、内部メモリーを強化するなどした。
- スケールアップ向けに性能/消費電力比を改善した。
- 同じくスケールアップ向けにI/Fを強化した。
学習向けの場合、推論向けとは桁違いの演算能力が必要になる。これに対しての基本的な発想はCerebrasのWSE/WSE2と同じで「数は力」なので、どれだけスケールさせられるかの勝負となる。これに向けて、1個1個のダイの性能は落ちても、性能/消費電力比を改善させられればむしろ好ましい、という発想である。
基本的な構造は推論向けのJawBridgeやGraySkullと変わらないが、より演算効率を引き上げたり、I/Oを強化したりといった形で洗練されることになった。演算効率の向上については、1個のTensixコアあたりの演算スループットを引き上げたほか、搭載するSIMDエンジンでより複雑な算術/論理演算を行なえるように強化したとしている。またTensixコアに搭載されるSRAMの量も強化したとの話だ。
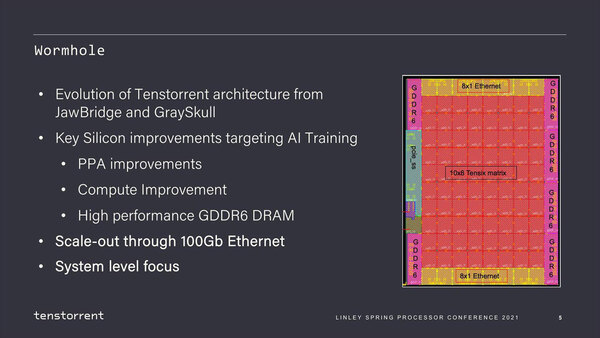
32bit GDDR6/16Gbpsだとするとチャネルあたり64GB/秒。6chで384GB/秒となる。GrayskullはLPDDR4-4266×8とするとチャネル当たり17GB/秒、8chで136.5GB/秒程度で、軽く3倍ほどの帯域に強化された形になる
さて、これ単体では効率を上げたとはいえ絶対的な性能は当然落ちるわけだが、そこで100Gイーサネットを16ポートも搭載していることが効いてくる。フォームファクターとしては75WのPCIeカードと、Wormholeモジュールという2種類の形態が用意されており、このモジュール同士を8×4で相互接続した構成がNebulaとなる。
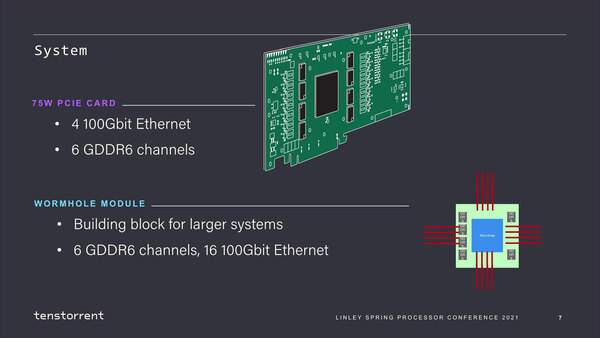
WormholeモジュールのTDPが発表されていないあたりがお察し。さすがに100Wを大きく超えるとは思えないが
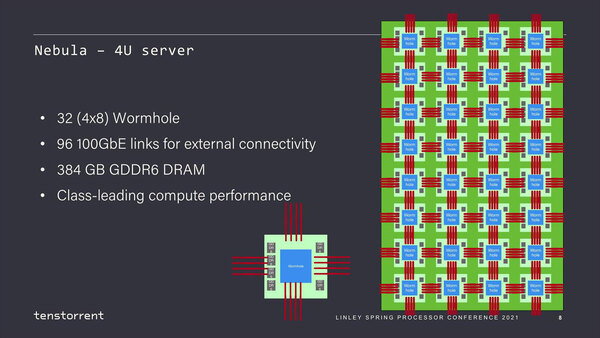
Nebulaの構成。おそらく100Gイーサネットは、物理的に高速に接続できるうえ、PHYのIPも広く提供されており、安価に利用できるという意味で採用されただけで、ここにTCP/IPを通しているわけではないだろう。もちろんPCIeカードの方はTCP/IPでの接続を前提としているはずなので、通せないわけでもないだろう
このまま上端と下端、左端と右端を相互接続すれば2次元トーラス構造になるわけだが、あえて“External connectivity”としているのは、このNeburaを複数接続するのにも利用するためである。
Nebura(それぞれは4Uラックに収まる)を8枚と、さらに管理用と思われる2U EPYCサーバー×4、それとMemory Pool(SSDかなにかだと思うが詳細は今回語られなかった)をまとめて48Uラックに突っ込んだのがGalaxyである。

Galaxyの構成。ほかに、Neburaを4本に抑え、その分Memory Poolを強化するという構成も提案されている
1本のGalaxyラックにはWormholeモジュールが256個搭載され、トータルでは20480個のTensixコアが稼働することになる。この48Uラックの構造を展開したのが下の画像である。
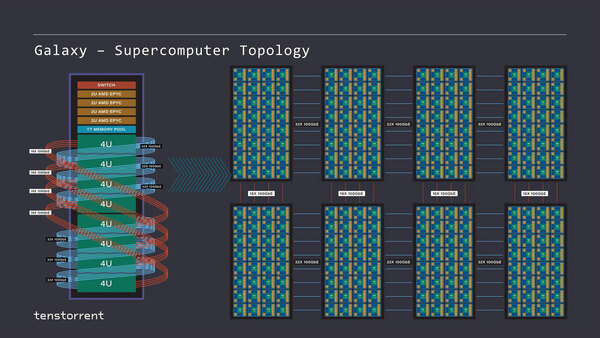
水色が横方向、赤が縦方向のイーサネットである。余談だが、ラック内の配線は100GBASE-CR4あたりを使うと思われる。必要になるトランシーバーモジュールだけでもすごい数(と消費電力)になりそうではある
Nebura内部のWormholeモジュール間の通信に比べると、Nebura間の通信は若干レイテンシーが増えるとは思うのだが、それは20nsが30nsになる程度で、数倍にはならない(レイテンシーで一番大きいのは100GイーサネットのPHYを経由する部分なので、ここはNebura内でもNebura間でも変わらない)と想像されるので、比較的性能は強化しやすいだろう。
Tenstorrentはさらに、スーパーコンピューター向けの2ラック構成と、データセンター向け構成の提案もしている。

理論上は縦方向にさらに広げることで4ラック構成も不可能ではないと思うのだが、現在はソフトウェアの方が2ラック/40960 Tensixコアを最大構成と想定しているようで、これが限界な模様だ
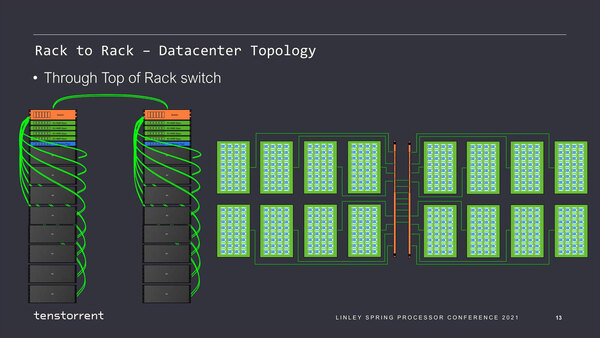
もっとも高性能なスイッチといっても、合計で320本もの100Gイーサネットのルーティングをカバーするのは容易ではない。これだけのポート数だとそれだけでラックを20Uくらい占有しかねないので、現実的ではないだろう
スーパーコンピューター向けは、言ってみればこれ全体で1つの学習を高速に実行する構成に向けたもので、Galaxyの48Uラックの構成を横方向に拡大した形だ。一方のデータセンター向け構成の方は、複数の学習処理を同時に走らせる、例えばクラウドサービスの形で複数の顧客が分け合って使う的な使い方を想定した模様で、こちらはNebura内こそ縦横400Gbpsの相互接続になっているが、Nebura間は100Gのネットワークでつながる疎結合的な構成である。
スーパーコンピューター向けとデータセンター向けでは物理的に配線が異なるので簡単に切り替えることはできないが、ニーズに応じて変更できるというのは良い話である。もちろん高性能なスイッチを入れれば、動的に2つの構成を入れ替えることも可能だが、スイッチを挟んだ瞬間にレイテンシーが増えることは否めないので、スーパーコンピューター向けの構成を希望するユーザーにはスイッチの導入は受け入れられないだろう。
ここでのポイントは、最大40960コアまでほぼ均一のレイテンシーでアクセスできるので、ユーザーはあまり構成を意識する必要がないことだ。強いて言うなら、1つのWormhole内では非常に高速だが、それを超えるNeburaなりGalaxyに関して言えば一定のレイテンシーがかかる。これさえ意識していれば比較的簡単にアプリケーションを最適化できることになる。
このWormhole、現在は最初のサンプルがラボで稼働中という状況である。同社によれば2021年中旬にサンプル出荷を開始するそうで、秋のLinley Processor Conferenceでは動作周波数や性能、消費電力に関してもう少し具体的な数字が出てくるかもしれない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























