




新たな市場に活路を見出すべく
AI分野に進出
さて話がやっとAIに戻ってきた。これに続く製品は、方向性をガラッと変えることになった。2019年5月、Achronixは第3世代のSpeedSter FPGAの構成を発表する。Speedster7tと名付けられた新製品の特徴は以下の通り。
- 機械学習と広帯域ネットワークに特化
- 既存のアーキテクチャーとプログラミング環境を継承
- TSMCの7nm FinFETプロセスを採用
なぜ突然に機械学習が出てきたかと言えば、単なる高性能FPGAというだけではもはや市場が獲得できず、一方で高速通信の市場は確実に存在はするものの競合も多い(なにしろXilinxやAlteraがここを得意としている)。そこで新たな市場としてAI分野に進出しようというわけだ。
そのSpeedSter7tの構成が下の画像だ。基本的にはFPGAなので従来同様のLUTとBRAM(Block RAM)を組み合わせた構成だが、Speedster22iまでの基本だったpicoPIPEと決別し、新たにNoC(Network on Chip)の構成を取ることになった。
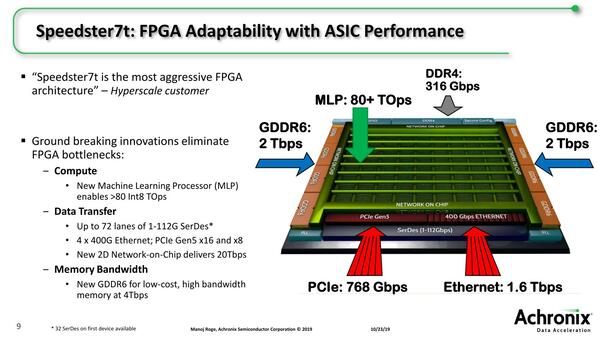
SpeedSter7tの構成。外部にGDDR6を16チャネル接続可能で、これで最大2Tbpsの帯域が確保できるとする。また最大で400G Ethernet×8(or 100G Ethernet×32)、PCIe Gen5を最大2×16接続できるほか、112GのSerDesも搭載する、いろいろお化けスペックである
また新たにMLP(Machine Learning Processor)なる機械学習専用のプロセッサーを複数個実装している。いくつ、というのはモデルによって異なるが、最初に出荷開始した(そして一番MLPの多い)AC7t1500という製品の場合、MLPが実に2560個搭載されている。
このMLPの内部構造が下の画像で、128bit長のSIMD風演算ユニットになっており、Int 8なら1サイクルあたり16個のMAC演算が可能である。つまりMLPあたり32 Op/サイクルで、これが2560個あるから1サイクルあたり最大80K Ops/サイクル。FPGA内部を1GHzで動作させれば、演算性能は80TOpsに達するという計算である。
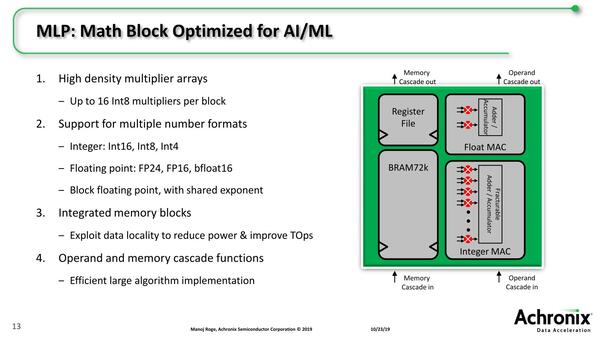
MLPの内部構造。ちなみにINT4なら性能は2倍、INT16なら性能は半分になる。浮動小数点の場合、FP16はINT16と同じく、FP32は未サポートだがFP24だとFP16と同じ処理性能となっている
もちろんFPGAそのものもAI/ML処理に利用できる。MLPは要するに畳み込み(のための乗加算)をひたすら行なうのには適しているが、それ以外の処理は一切考慮しておらず、なのでアクティベーションやプーリング、あるいはなにか特殊な処理が必要な場合はFPGA側で処理する必要がある。
Achronixによれば、TensorFlowやCaffe2、ONNX、Apache tvmといったAI向けフレームワークをサポートしており、比較的容易にAI/MLアプリケーションを移植できるとしている。またサーバーなどでSpeedster7tを利用するためにVectorPath Accelerator Cardを用意するとしている。

先のAccelerator-6Dカードに負けないくらい重装備の拡張カード。実際には2スロット厚のカードとして提供される予定だ
冒頭にも書いたがこのSpeedSter7tは、まずAC7t1500というチップに関しては4月8日よりサンプル出荷を開始しており、今年後半中にすべての機能の検証を完了させ、今年年末に量産を開始予定である。さて、あとは同社の思うように、Speedster7tがAI/MLで性能が出るかどうか、それ次第で同社が今後も生き残れるかどうかが決まってくるように思う。
※お詫びと訂正:会社名の表記に誤りがありました。記事を訂正してお詫びします。(2021年4月20日)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























