ロードマップでわかる!当世プロセッサー事情 第590回
Radeon Instinct MI100が採用するCDNAアーキテクチャーの内部構造 AMD GPUロードマップ
2020年11月23日 12時00分更新

CDNAはRDNAにかなり近いが
SIMDエンジンをHPC向けにチューンしている
個々のCU(CUDA 1.0ではXCUという名前になっている)の構造が下の画像である。1つのXCUに64個の演算ユニットが実装されるという構図はGCNやRDNAと同じであるが、GCNとの比較で言えば以下の違いがある。

XCUの構造。この64個の演算ユニットが16WideのSIMD構成であることそのものは以前と同じ

こうしてみると基本的なコンセプトはRDNAとかなり近いが、SIMDエンジンの内容をHPC向けにした感じである
- FP64/FP32のサイクル当たりの処理性能(Vector FP32/FP64)は同じ(FP64で64Flops/サイクル、FP32で128Flops/サイクル)
- 新たに行列演算を高速化するMatrix Unitと呼ばれる仕組みが入り、これを利用することでFP32だと2倍(256Flops/サイクル)の処理性能になる
- FP16は、GCNだとFP32の2倍(256Flops/サイクル)なのに対し、CDNA 1.0ではこの4倍の1024Flopsサイクルで演算可能
- 新たにBFloat16をサポート。演算性能は512Flops/サイクルになる
XCUはこの演算ユニット4つで構成されるので、1CUあたりFP64で256Flops/サイクル、FP32だと512~1024Flops/サイクル、BFloat16で2048Flops/サイクル、FP16なら4096Flops/サイクルになる計算だ。
フロントエンドを含む全体の構成が下の画像だ。RDNAの構成と比較すると、RDNAがWave32での管理となっており、2つの16-Wideをまとめて32-WideのSIMDとして扱う関係か、Wave Controllerは20 Waveになっているのに対し、CDNAではおそらくGCN同様に64-Waveでのハンドリングしていると思われ、Wave Controllerは10 Waveになっているのが目立つ違いである。Vector Registerの数などはRDNAと共通になっている。
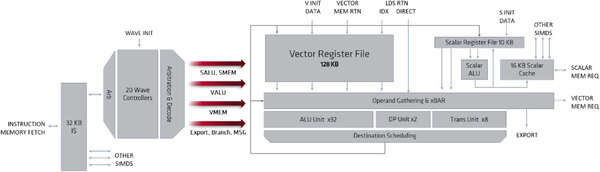
こちらはRDNA(RDNA2ではない)の内部構造。Scalar Registerが10Kあるのが目立つ

RDNAのダイ写真。どういう理由か知らないが、AMD提供のこの画像は妙に解像度が低い

こちらのダイ写真は斜めになり、しかも妙な映像効果付きであるが、高解像度のものに歪み補正をかけたもの。したがって縦横比は正確ではない
さて、先のCDNA 1.0の構造を示す画像によれば、CDNA 1.0はこのXCUを複数個まとめたグループを8つ搭載することになる。Radeon Instinct MI100の仕様によればXCUは120個なので、グループあたり15個のXCUが含まれる計算になるのだが、実際にダイ写真を見ると、16個のXCUが含まれていることがわかる。
つまりハードウェア的には128XCU、8192個のStream Processorが実装されており、このうち120XCU、7680個のStream Processorのみを有効にしているとわかる。

前述のダイ写真の左上を切り出してナンバーを振ってみた
この理由は後述するダイサイズに関係する。CDNA 1.0は過去最大規模のダイサイズであり、それなりに欠陥を含んでも対応できるように、冗長XCUを8つ用意したというあたりであろう。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ













