ロードマップでわかる!当世プロセッサー事情 第588回
Ryzen 5000シリーズはなぜ高速なのか? 秘密はZen 3の内部構造にあり AMD CPUロードマップ
2020年11月09日 12時00分更新

ALU内部の高速化で
レイテンシーとスループットを改善
実は、これ以外にも大きな改善がある。それはALU内部の高速化である。11月6日付で、やっとZen 3に対応したSoftware Optimization Guideがリリースされた。そこで、全命令のレイテンシーおよびスループットを比較したところ、Zen 2で1486命令が定義されている(Zen3では1510命令)のだが、このうち619命令のレイテンシーまたはスループットが変わっていた。
最初は軽い気持ちで一覧をご紹介しようと思ったのだが、さすがに600行のExcelリストを公開すると長くなるので、かいつまんでいくつか紹介しよう(Excelのリストを表にしたものを記事の最後に掲載)。
例えばCRC32命令、Zen2では3 Micro-opに分解され、Latency 3/Throughput 0.33なのが、Zen 3では1 Micro-op/Latency 3 cycle/Throughput 1になっている。
あるいは除算(DIV)。Zen 2が2 Micro-Op/Latency 12~41 cycle/Throughput 0.04~0.058なのが、Zen 3では2 Micro-Op/Latency 9~18/Throughput 0.1~0.25に向上しているといった具合である。
CLCだとZen 2まではMicro codeの実装になっており、Latency 1 cycle/Throughput 4なのが、Zen 3ではLatency 0 cycle/Throughput 6と大幅に高速化されている。
もっとも全部が全部高速化してるわけではなく、例えば(ALUではないが)FMULは1 Micro-op/Latency 5 cycle/Throughput 2が、1 Micro-op/Latency 6/Throughput 1になるといった具合に、レイテンシーが増えたりスループットが減ってたりする命令も含まれているのだが、全体の5分の2ほどの命令に変化があるというのは、ALU(とFPU)の中身のかなりの部分に手が入っているものと考えられる。全体としては以下のようになっている(重複ありなので注意されたい)。
| ALU内部の最適化で、高速になった命令 | ||||||
|---|---|---|---|---|---|---|
| x86から変換後のMicro-Opが減った | 25命令 | |||||
| レイテンシーが削減された | 173命令 | |||||
| スループットが増えた | 286命令 | |||||
単にスケジューラだけではなく、かなりALUの中身まで見直しをかけたと考えて良いだろう。個々の性能改善はわずかであるが、それを積み重ねることでIPCの改善が実現できたと考えられる。
次がFPU。実行ユニットが6に増えた、というのは当たったが、その実装は筆者の想定と異なるものだった。つまり(ADD+MUL)×3となると想定してたのだが、そうではなく(ADD+MUL+STORE)×2、という構成だった。
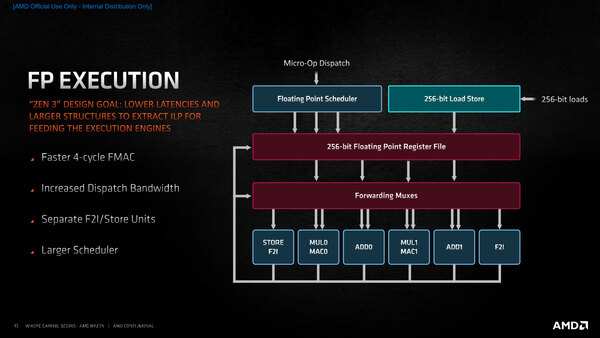
浮動小数点数演算の仕組み。例えばVFADDxxxシリーズの命令は、いずれもLatency 5cycle/Throughput 2からLatency 4cycle/Throughput 2に高速化された。またCVT系はLatency 3~4cycle/Throughpu 1からLatency 3~4cycle/Throughput 1.5~2になっている
Zen 2までの世代の最大の問題は、FP2の非対称構造である。連載333回の表を見ていただくとわかるが、AVXレジスターのロード/セーブは事実上FP2に集中している。これがスループットを上げられない最大の要因であった。
そこでZen 3ではこのAVXレジスターのロード/セーブを新設した“STORE/F2I”に、General Register Operationや一部の特殊命令を“STORE/F2I”に移している。
STOREでは MOVSS xmm1,xmm2 / MOVLPS xmm1,[mem] / MOVSD xmm1,xmm2 /MOVLPD xmm1,[mem] の4つの命令が処理され、一方F2IやSTORE/F2Iでは CVTPI2PS / CVTSI2SS / CVTSD2SS / CVTSS2SD / CVTSI2SD / RCPSS / ROUNDSS / ROUNDSD / RSQRTSS / SQRTSD / SQRTSS といった命令が扱われることになる。
これにより、基本的にはZen 2と大きく変わらない構造のまま、実効性能を引き上げた格好になっている。
スループットとプリフェッチ性能が向上した
ロード/ストアーユニット
最後がロード/ストアーユニットであるが、やや気になる表現があった。
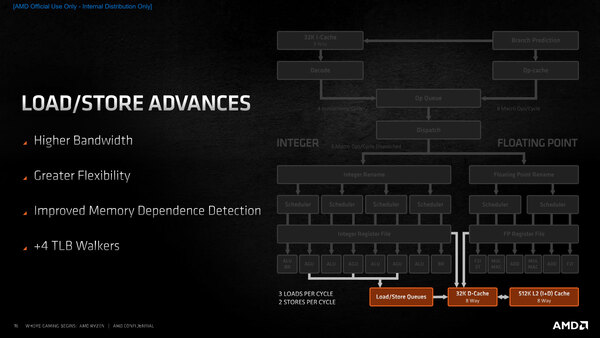
ロード/ストアーの仕組み。Nested Pagingは、特に仮想環境においてPagingを高速化するための技法であるが、こちらも当然Secure化が進んでいる
少し話が飛ぶが、Zen/Zen 2の世代からTLB smashingの機能が搭載されている。Smashingというのは強いて訳せば「エントリーの叩き込み」だろうか。
例えば64bit OSではページサイズを4KBytesではなく1MB/2MBとか、大きいものだと1GBまでサポートする。こうした大きなページサイズは、TLBでサポートしていない(例えば1GB PageはL2 TLBで管理できない)のだが、特定の条件が成立する条件では、2MBのL2 TLBを利用して1GB Pageを管理可能になっている。
この特定の条件下で、より小さいサイズのTLBを使う技法がSmashing(あるいはPage Smashing)であるが、Zen 2まではこれを管理できるのはINVLPGおよびINVLPGA命令のみだった。
Zen 3ではこれがINVLPG、INVPCID、INVLPGBとINVLPGAの4命令に増えたほか、新たにSecure Nested Paging命令としてRMPUPDATE、PVALIDATE、PSMASHとRMPADJUSTの4つを追加している。“+4 TLB Walkers”の意味はたぶんこのSecure Nested Paging命令関連と思われる。
さて、ロード/ストアーユニットの構成が下の画像だ。Zen 2までの構造と比較すると大きくは変わらない(大分省いてある)が、DTLBサイズやStore Queueを増やしたほか、ロード/ストアーのスループットを引き上げたのが大きな相違点である。
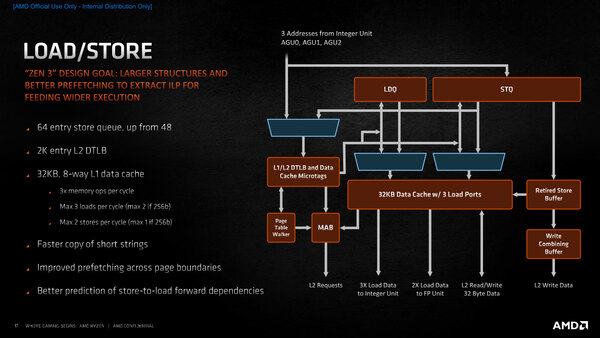
ロード/ストアーユニットの構成。Page Table Walkerが効こうとして独立しているのがわかる。Retired Store Bufferは、以前はStore Commitと表現されていた部分だ
256bit、つまりAVX命令を利用する場合はロード×2、ストアー×1で変わりがないが、128bit(ALUやFPU、SSEまでの命令)ではロード×3、ストアー×2が可能になった。これもIPC向上には大きな効果がありそうだ。
またStore-to-Load(ある命令で書き換えたメモリーの値を、後続する別の命令で参照する)の関係性の推定の向上(きちんとどの値を後続で参照しているかを判断できれば、それをレジスターに格納しておくことで、後継の命令のメモリーロードを行なわずに済む)とか、ページ境界を跨いでのプリフェッチ性能の向上など、細かな改良が積み重ねられているのがわかる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ








