
すでにハッチパイセンの速報が上がっているが、日本時間の10月29日午前1時から、AMDはRadeon 6000シリーズの発表会をオンラインで開催した。この内容はYouTubeでも視聴できるが、この内容を整理して説明したい。
まずは製品ラインナップだ。今回は合計で3製品が発表になった。そのラインナップであるが、おおむね下表のように位置付けられている。
| Radeon 6000シリーズのラインナップと対抗機種 | ||||||
|---|---|---|---|---|---|---|
| ラインナップ | 対抗機種 | |||||
| Radeon RX 6900 XT | GeForce RTX 3090対抗 | |||||
| Radeon RX 6800 XT | GeForce RTX 3080対抗 | |||||
| Radeon RX 6800 | GeForce RTX 2080 Ti/GeForce RTX 3070対抗 | |||||
GeForce RTX 3070についてはKTU氏の熱の入ったレポートがすでに掲載されているが、おおむねGeForce RTX 2080 Tiと同程度以上という結論であり、筆者がテストした結果もだいたい同じである。このあたりの層をRadeon RX 6800で狙おうというわけだ。
初代NaviのCU数を増やしただけではなく
内部構造を大幅に見直したBig Navi
ではBig NaviことRDNA2チップについて説明しよう。大写しとなったこちらのパッケージは、良く見るとCU数が72個で、要するにRadeon RX 6800XTのものである。ダイそのものはCUが80個であるのは、しばしば示されている通りだ。

チップを示すLisa Su CEO。さすがにこれをアップにしても暗すぎてなんだかわからない

大写しとなったチップ。しかしこう、真ん中で分けると簡単に2つに分割できる構造になっているのがある意味わかりやすい

Su CEOの背後の画像を見ると、ちゃんと80CUになっている
そのBig Naviは単に初代NaviのCU数を増やしただけではなく、内部構造を大幅に見直したとする。現時点では、それが具体的にどういう形になったかの詳細は明かされていない。ただ下の画像にあるように、3つがCUの特徴として挙げられている。
- 広範囲できめ細かなClock Gatingを実施
- 積極的なパイプラインのバランス取り直し
- データの移動効率改善を目的としたデータパスの再設計

つまりCUの論理的な構造そのものは初代NAVIと同じで、ただしより省電力化と高速動作対応を図ることで、より高い動作周波数での駆動が可能になったということだ
一方Big Naviで新しく追加されたのが、Infinity Cacheである。初代Naviは128KB/16wayのL1+4MB 16wayのL2という構成であったが、ここにおそらくL3の形で追加される構造と思われる。これにより、384bit幅のGDDR6そのままと比較して、実効バス幅を2.17倍にしながら、消費電力は0.9倍に抑えられたとする。

Infinity Cache。こういう使い方をするということは、L3はプログラムからは透過的に存在し、GPU自身がメモリーのプリフェッチやライトバックのために利用する領域として使われると思われる
384bit幅が唐突に出てきたのは、おそらくBig Naviの構成では普通に考えると256bit幅では全然帯域が足りず、384bitでもまだ不足していると考えているためだろう。かといって512bitはコストも上がるし消費電力も上がる。ところが256bit幅+大容量L3キャッシュの搭載でこれをカバーできた、というわけだ。
性能について言えば、動作周波数を30%引き上げできたとしている。実際問題としてはRadeon RX 5700XTが40CU/1605MHz(ベースクロック)で、Radeon RX 6800XTが72CU/2015MHzだから、動作周波数が1.26倍、CU数が1.8倍で、消費電力は本来なら2.25倍に膨れ上がっていないとおかしい。
これを同じ300W枠内に収めつつ、動作周波数を2GHzオーバーまで引っ張り上げられたのは、先のInfinity Cacheで示した省電力化と高速動作化が効果的に作用したということだろう。ちなみに性能/消費電力比ではNAVI世代から54%の改善とされている。
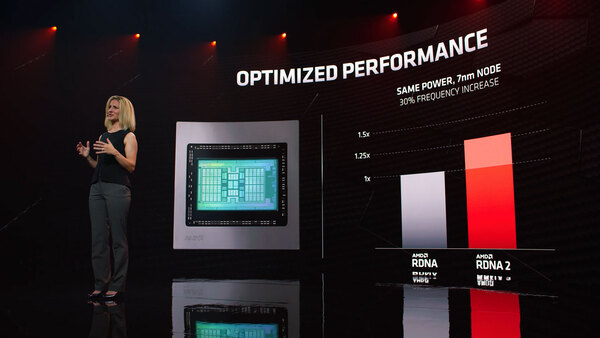
動作周波数を30%引き上げたが、プロセス自身は完全に同じTSMCのN7である。つまり省電力化はAMDの設計だけで実現した形だ

性能/消費電力比はNAVI世代から54%の改善。回路の高速化と省電力化、Infinity Cacheの搭載の3要素がそれぞれ同程度の貢献を果たしたとする
加えて新たにDirectX RayTracingやVariable Rate Shading(VRS)、Mesh Shader、Sampler Feedbackなどにも対応した。

DirectStorage APIへの対応も表明された

Variable ShadingなどはDX12 Ultimateにも含まれる機能である
VRSはすでにDirectX 12に実装されているが、それ以外はDirectX 12 Ultimateでのサポートになる。このあたりの新技術の概略はジサトライッペイ氏の記事がわかりやすい。この辺のサポートはNVIDIAが先行していたが、やっとAMDもこれに追いついた形だ。
なお、従来からFidelityFXとして提供されてきた機能は引き続き提供される。また、Radeon RX 6000シリーズというかRDNA 2に続くものとしてRDNA 3の開発が行なわれていることも明らかにされた。

RDNA 3は“Advanced node”とあり、おそらく5nmを利用すると見られる
ところでカードの話に移る前に、Big Naviのダイでもう1つ。先の大写しとなったチップの画像を見てもわかるが、現在の構成は半分のサイズにしやすいように設計されているように思う。ということで試しに切り貼りしてみたのが下の図だ。

Big Naviを半分にしたダイ。コード名は不明なので、とりあえず“Not so big Navi”としてみた
半分とは言わないが、6割程度のダイサイズで完結しそうである。このあたりは、よりバリュー向けのRadeon RX 5600などに向けたラインナップに出てきそうな気がする。たぶんこちらは相当低コストで収まりそうだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ













