

同じ顔は存在しないが、システムはだまされる可能性がある
顔認識システムは、一昔前まで、SFの世界のような未来のシステムだった。しかし今では、スマートフォンにも搭載されるほど、ポピュラーなものになってきている。
たとえばスマートフォンのロック解除に利用するのであれば、パスワードなどと違い、顔認識は「本人の顔」でしか解除できないとされているため、セキュリティとしては強固なものとなる。監視カメラに導入された例があるほか、チケットの転売防止などにも利用されている。
しかし、完全なセキュリティというわけではない。古典的な手法でいえば、よくできた写真(画像)、3Dのマスクなどで、顔認識システムは突破できる可能性がある。これらは顔認識の精度が上がれば淘汰されていくかもしれない手口ではあるものの、可能性としては考慮しておくべきだろう。
また、誤認識の可能性もあり、そのことに懸念を示す声もある。2020年6月、アメリカのデトロイト州で、顔認識技術の誤検知によって、無実の黒人男性が逮捕された事件を知っている人もいるだろう(Wrongfully Accused by an Algorithm - The New York Times)。
同月には、IBMが顔認識事業から撤退することを宣言した(IBM CEO's Letter to Congress on Racial Justice Reform)。顔認識を実施するAIによって、人種プロファイリングや人種に関する偏見が起こったことを踏まえ、法執行機関によるシステム使用に人道的な懸念が生じた結果という。
システムが誤認識するという可能性を脆弱性だと考えれば、意図的に誤動作させる手口も考えられる。たとえば、パスポートの照会には顔の認識が必要な場合でも、ニセの画像を作成し、認証システムに誤認識させ、明らかな別人をシステム上で「同一人物」だと思わせるような方法だ。
昨今は、AIの進化によって、テクノロジーの専門家でなくても精巧なディープフェイク(人工知能にもとづく人物画像合成などの技術)の作成が可能になっている。今後は、サイバー攻撃者が顔認識システムを回避するために、ディープフェイクを利用し、人間もシステムも見分けられない「ニセの顔」を作成するおそれもある。世界に同じ顔の人間は存在しなくても、システムをあざむくための方法はありえるのだ。
新しい技術、日々進歩する技術に対しては、過信することなく、起こりうるセキュリティリスクを理解することが重要だ。「パスワードより安全に違いない」といったような思い込みは危険かもしれない。
今回は、顔認識システムが人間に比べ、顔を誤認識するリスクが高いのかどうかについて検証した、McAfee Blogの「ドッペル・ゲンガー 顔認識システムの攻略」を紹介しよう。(せきゅラボ)
※以下はMcAfee Blogからの転載となります。
ドッペル・ゲンガー 顔認識システムの攻略:McAfee Blog

この記事へのキャサリン・ファン博士(Dr. Catherine Huang)、マカフィーAdvanced Analytics Teamの協力に感謝します。
目次
事実に”面と”向きあう
パスポート検証のためのリアルタイムな顔認識
システム突破の戦略
CycleGANとは
Face NetとInception ResNet V1について
トレーニング
ホワイトボックスとグレーボックスへの適用
実際の検証例
この研究から学べること
事実に”面と”向きあう
世界には76億もの人間がいます。なんて膨大な数なのでしょうか。事実、世界中の人が皆赤道上に肩を並べて立ったとしたら、地球86周分以上の長さにもなるのです!現在地球上に存在する人間ですら、こんなに多いのです。しかし、ここに歴史上の全ての人間を加えたとしても、全く同じ2つの顔が見つかることはありません。実際、記録にある最も似ている顔(双子を含まない)同士を比べても、いくつもの違いを簡単に見つけることができます。人間の顔がそんなに多様だなんて、まるでありえないことのように思えるのではないでしょうか。2つの目、鼻、口、耳、眉毛、そして髭などがある人もいるかもしれませんが、これだけの要素でそんなに多様性を持つことが可能なのでしょうか?誰もが、血が繋がっていないのにそっくりな人たちを見つけたことがあるはずです。実は、人間の顔はこれ以外にも、私たちがしばしば考えるよりずっと多くの微細な要素で成り立っているのです。額の大きさ、顎の形状、耳の位置、鼻の構造、そして他にも数千以上の非常に細かい部分によって構築されています。
このことが、マカフィーや脆弱性調査にどんな関連があるのでしょうか?このレポートでは、McAfee Advanced Threat Research (ATR)がデータサイエンスとセキュリティに関して行ったリサーチを紹介します。具体的には、顔認識システムが人間に比べ、顔を誤認識するリスクが高いのかどうかについて検証しました。
下の4つの画像を注意深く見てください。これらのうちどれが偽物で、どれが本物の人物写真なのかわかりますか?

StyleGAN画像
答えを聞いたらびっくりするかもしれません。4つの画像はすべて偽物なのです。しかも、複数の人の顔の部分を重ね合わせたのではなく、100%コンピュータで生成された顔なのです。StyleGANとして知られるエキスパートシステムによって、これらの画像を含む数百万以上もの「顔」が、(リアルさはさまざまですが)一から生成されました。
この驚くべきテクノロジーは、データサイエンス、そしてかつてないほど高速かつ安価に動作する新興テクノロジーの双方において革命です。これにより、データサイエンスと画像生成・認識における目覚ましい革新が可能となり、リアルタイムまたはほぼリアルタイムでの動作実行が実現しました。この技術は、特に顔認識の分野などにおいて実用されています。簡単に言えば、コンピュータシステムにおいて、2つの画像やメディアが同一人物を表しているかを判断する能力のことです。最も初期のコンピュータ顔認識技術は1960年代に遡ります。しかし最近まで、費用対効果が低い、誤認識が多い、遅すぎて非効率的なため実用は難しいなどの問題がありました。
人工知能(AI)と機械学習(ML)における技術の大きな躍進により、顔認識に数々の新しい実用法が生み出されたのです。まず第一に、顔認識は信頼性の高い認証システムとなります。この特に優れた例として、iPhoneが挙げられます。2017年のiPhone X以降、顔認識は、モバイルデバイスでユーザーを認証するための新しい事実上のスタンダード機能となりました。Appleは、対象となる顔をマッピングするために深度などの高度な機能を使用していますが、他の多くのモバイルデバイスでは、対象の顔の特徴に基づいた、より標準的な方法を使用しています。人間が見てもわかるような、目の配置、鼻の幅やその他の特徴の組み合わせによって単一のユーザーを正確に識別するのです。このようなより単純で標準的な方法は、3D カメラキャプチャなどの高度な機能に比べると、セキュリティに限界がある可能性があります。より高度なシステムを採用する意義は結局、ここにあります。深度情報という複雑さが増せば、ピクセルの操作による攻撃は不可能になるのです。
顔認識システムの実用例としてはさらに、法執行機関での導入が挙げられます。ロンドンのメトロポリタン警察は2019年に、犯罪者や行方不明者の識別を自動化し、警察の業務を補佐するために設計されたカメラのネットワークの導入を発表しました。広く物議を醸したこの試みは、英国だけに留まりません。他の主要都市でも、一般市民の同意の有無にかかわらず、様々な顔認識システムの実験的、あるいは本格的な運用が行われてきました。中国では、多くの列車やバスシステムが顔認識を利用して、乗り降りの際に乗客を識別・認証しています。また、同様のテクノロジーを導入したショッピングセンターや学校も、全国で増え続けています。
より最近では、IBMが顔認識事業から撤退することを宣言しました。これは、顔認識を実施するAIによって、繰り返し人種プロファイリングや人種に関する偏見が起こったことを踏まえ、法執行機関によるシステム使用に人道的な懸念が生じた結果でした。この決定は、当局が誤った顔認識結果に基づき、ロバート・ウィリアムズ氏という黒人男性の不当な逮捕に至った有名な「誤検知」事件などに基づいています。事件は、顔認識技術に直接起因する、米国最初の不当逮捕として知られています。
もちろん、顔認識にはいくつか明らかな利点もあります。この最近の記事は、中国で、何年も前に誘拐された被害者を顔認識により探し出し、家族が再会するに至った例を詳説しています。しかしながら、顔認識システムはプライバシーに関する重大な懸念を抱え、非常に意見の分裂する問題であり、弱点を軽減するためには、さらなる大幅な開発が必要となる可能性があります。
パスポート検証のためのリアルタイムな顔認識
次に紹介する顔認識の実用例は、あなたが思うよりも生活に身近なところにあるかもしれません。米国内の多くの空港を含む複数の空港で、人間によるパスポートや身元の確認を補佐、または代替する目的で顔認識システムが導入されています。私も実際に、2019年にアトランタ空港で体験することができました。システムは完成には程遠いものでしたが、引き続き全国で展開されていくでしょう。事実、新型コロナウイルス感染症(COVID-19)により移動機関における感染軽減への必要性が高まったことから、生体認証などのタッチレスソリューションは前例にないほど迅速な導入が進められています。これは責任の観点からはもとより、航空会社や空港の収益性の観点からも行われています。旅行の感染リスクが低いことが納得できなければ、多くの旅行者は必要に迫られない限り、安全性がより確立されるまで移動を控えることを選択するでしょう。この記事は、まだ始まったばかりのパスポート顔認識の市場にコロナが及ぼしている影響について論じています。デルタ航空とユナイテッド航空の新空港における顔認識技術の急速な使用拡大、そして世界各国における試運用と実際の導入について、具体的に取り上げています。より多くの空港において顔認識システムを利用する試みによって、物理的な接触とそれに伴う感染を減少させることはできるかもしれません。しかし、顔認識システムという新しい標的の攻撃対象領域(アタック・サーフェス)が急激に増えるという副作用もあります。
顔認識による出入国管理の概念は非常にシンプルです。まず、カメラがあなたの顔のライブ動画や写真を撮影します。次に、それを検証サービスが、パスポートや国土安全保障省のデータベースなどに既に保存されているあなたの写真と比較するのです。空港にてその場で撮影された写真は、比較対象となる写真と同様なフォーマット(画像サイズやタイプなど)になるよう処理された後分析されます。そして画像が一致となった場合に、パスポート所持者の認証が完了するのです。一致しない場合は、搭乗券や身分証明書など、他の情報が人間のオペレーターによって確認されます。
脆弱性の研究者として、私たちは意図された運用方法だけでなく、見落とされた部分も含めて、システムの仕組みを検証できなければなりません。発展を遂げる顔認識のテクノロジーは、極めて重要で責任の重い選択をもたらします。ですから、私たちは顔認識の基盤となるシステムの弱点を利用して、標的となる顔認識システムを回避することが可能なのかを検証したのです。具体的には、「敵対的な(アドバーサリアル)画像」をパスポート形式で作成し、ターゲットとなる個人として誤認識されるかを検証しました。(余談ですが、これに関連するシステム突破の試みとして、画像認識システムに対し、デジタルメディアと物理メディアの両方を使用した攻撃を行った実績があります。一部のテスラ車両に搭載されているMobileEyeカメラに関して発表した研究が一例です。)
ここで想定される攻撃シナリオは簡単です。ここで人物Aとする攻撃者は、「搭乗禁止リスト」に入っています。彼の空港での写真や動画が政府機関に保存されているパスポートの画像と一致すれば、すぐに搭乗を拒否され、逮捕される可能性があります。ここでは、Aはパスポートの写真を提出したことはないと仮定します。共犯者である人物B(別名スティーブ)は、人物A(別名ジェシー)に協力し、このシステムを突破する手助けをしています。ジェシーはモデルハッキングの専門家であり、自身で構築したシステムを使ってスティーブの偽の画像を生成します(これについては後により詳しく説明します)。偽物の(敵対的な)スティーブの画像は、パスポート写真として政府に提出された時点ではスティーブのように見え、しかし認証システムでは、ジェシーとして誤認識される必要があります。パスポートの認証システムが、空港で撮影されたジェシーの写真を偽の画像と同一人物として認識する限り、ジェシーは顔認識を回避することができます。
ありえないような話でしょうか?ドイツ政府はそうは思わないようです。ドイツの最近の政策には、加工された写真やコンピュータによって生成された写真をはっきりと禁止する表現が含まれています。このリンクの記事で紹介されている手法は私たちの研究とも密接に関連していますが、アプローチ、テクニック、そして成果物そのものは大きく異なります。例えば、フェイスモーフィングの概念はもはや新しいアイデアではありません。しかし、私たちの研究では、より原始的な「加重平均をとる」フェイスモーフィングアプローチとは全く種類の異なる、より高度なディープラーニングをベースとしたモーフィング手法を使用しています。
マカフィーATR 研究員でインターンのジェシー・チックは、6 か月間にわたり、最先端の機械学習アルゴリズムを研究し、業界論文を読んで研究に取り入れ、マカフィーのAdvanced Analyticsチームとの緊密な協力体制によって、顔認識システムを打破する斬新なアプローチを開発しました。今日までに、研究はホワイトボックスとグレーボックスにおける攻撃まで進行し、大きな成功を収めています。これを元に、他の研究者たちと協同してブラックボックスでの攻撃に関する調査を進め、研究結果をパスポート検証システムなどの現実世界の標的に活かして、セキュリティ強化に繋げることを期待しています。
システム突破の戦略
GANという用語は、データサイエンスの分野でますます認知度が高まっています。これは、Generative Adversarial Network(敵対的生成ネットワーク)の略であり、1つ以上の「生成器(Generator)」と1つ以上の「識別器(Discriminator)」の協同による斬新なシステム概念を表します。このレポートはデータサイエンスの論文ではありませんのでGANについて詳しく説明することはしませんが、それでもこの概念を高いレベルで理解することは有益です。GANは、美術品の鑑定士と偽造者の組み合わせに喩えて考えることができます。美術鑑定士は、芸術作品が本物か偽造か、作品がどのような品質であるかを見極めることができなければなりません。もちろん、偽造者は鑑定士を欺くために、できるだけオリジナルに似た偽造品を作成しようとします。あるときは偽造者が鑑定士を出し抜くかもしれませんし、またあるときは逆かもしれません。このやりとりが続くことによって、最終的には双方がお互いを高め、手法を広げ磨くことになるのです。ここでは、偽造者が「生成器」、鑑定士が「識別器」となります。この美術品のシナリオは、作品を生成する側と識別する側が敵対しながらも、結局はお互いの向上のため協同することになっているという点でGANに似ています。GANでは例えば、生成器が顔の画像を作成し、識別器は、作成された画像が実際に顔のように見えるのか、それとも他のもののように見えるのかなどを判断します。識別器が出力された画像に満足しない場合は拒否となり、プロセスは最初からやり直しになります。GANのトレーニングフェーズでは、生成器の出力画像が「基準を満たす」十分な品質だと識別器が認めるまで、このプロセスが何度でも繰り返されます。
先ほど見た、この手法の実装の1つであるStyleGANでは、まさにこのような機能を使用して、最初に紹介した、本物の人間と見紛うような顔を生成しています。実際、私たちの研究チームでもStyleGANの検証を行いました。しかし、この研究ではリアルな顔を生成するだけでなく、顔認証をするためのさらなるステップを簡単に実装できる必要があるため、適さないとの判断に至りました。より具体的に言えば、StyleGANの洗練されたニッチなアーキテクチャは、巧妙なフェイスモーフィングによる攻撃を検証するという本研究の目的のためにうまく活用することは非常に困難だと考えたのです。このため、CycleGANと呼ばれる比較的新しく、しかし強力なGANフレームワークを使用することを選択しました。
CycleGANとは
CycleGANは、2017年に論文で発表されたGANフレームワークです。このシステムは、2つの生成器と2つの識別器によるGANの手法を使用しており、簡単に言ってしまえば、GANを使用して1つの画像を別の画像に変換する働きをします。

CycleGANによって馬に変換されたシマウマの画像
CycleGANのインフラストラクチャには、小さなことのようで実は重要な特色がいくつかあります。これらについて詳しくは説明しませんが、一つ大切なのは、CycleGANが画像の変換のために、より高レベルな特徴を利用するという点です。StyleGANがランダムな「ノイズ」や「ピクセル」を使用して画像を変換するのに対し、CycleGANは画像のより重要な特徴(頭の形状、目の配置、体のサイズなど)を変換に使用します。論文ではシステムの強みとして特には触れられていないものの、この特性は、人間の顔の変換に非常にうまく機能します。
Face NetとInception ResNet V1について
CycleGANは、GANモデルの用途としては斬新ですが、画像の変換システムとしてはこれまでも何度も使われてきています。顔認識の目的で使用するためには、画像検証システムを追加して、モデルを拡張する必要がありました。そこで登場するのがFaceNetです。私たちのモデルには、リアルで正確な敵対的画像を生成するだけでなく、その画像をさらに対象の個人として認証する機能が必要でした。これについては詳しく後述します。FaceNetは、2015年にグーグルによって開発された顔認識アーキテクチャであり、おそらく今日でも、顔を正確に分析する能力において最先端でしょう。このシステムでは、顔の埋め込みと呼ばれる概念を使用して、1つの次元内において2つの顔がどれだけ異なるか、その距離を数学的に算出します。プログラマーや数学に詳しい読者向けに言うと、正確には512次元空間が使用され、各埋め込みは512次元のリストまたはベクトルとなっています。一般読者は、顔の高レベルな特徴の類似度が低いほど、顔埋め込みの値の差も大きくなると理解してください。逆に、顔の特徴が似ているほど、埋め込みの値も近くなります。この概念は、私たちが求める顔認識の目的に最適です。例えば、FaceNetは個々のピクセルではなく、顔のより高レベルな特徴に対して機能するわけです。これは、従来多く使われてきたFGSM(Fast Gradient Sign Method)やJSMA(Jacobian-based Saliency Map Attack)などのより「初歩的な」敵対的画像生成と、私たちの研究モデルを大きく区別するポイントです。人間にも見てとれるような顔の特徴のレベルで機能する攻撃を生み出すという点で、この研究は新境地を開くことになります。
FaceNetが広く選ばれている理由の1つに、何億もの顔画像によるデータセットによって事前訓練済みのモデルを採用しているという点が挙げられます。この訓練は、知名度の高い学術・業界標準のデータセットを使用して実施されており、結果は容易に比較することができます。さらに、FaceNetはLFW(Labeled Faces in the Wild)と呼ばれる基準のデータセットからランダムに出力された13,000の顔画像群に対して実行された際、非常に高い精度(99.63%)を達成したことが公開されています。マカフィーによる検証では、精度95%に近い結果が出ました。
この研究では、アーキテクチャを理解するためにまずホワイトボックスから始める必要があります。そのため私たちは、最終的にCycleGANと、Inception ResNetバージョン1(V1)として知られるオープンソースのFaceNetのバリアントアーキテクチャを組み合わせるという方法を選択しました。ResNetの類の深層ニューラルネットワークは、畳み込みと呼ばれる学習済みフィルタを使用して、視覚データから高レベルの情報を抽出します。言い換えるなら、顔認識におけるディープラーニングの役割は、画像領域、すなわち対象者の個人的な特徴から、抽象的な特徴をベクトル領域(埋め込み)に変換し、数学的に推論できるようにすることにあるのです。同じ人物を描写する2つの画像の出力間の「距離」は、出力空間の同様な領域にマッピングされ、異なる人物を描写する2つの画像では、大きく異なる領域にマッピングされる必要があります。本研究の攻撃の成否は、これらの顔の埋め込み間の距離を上手く操作できるかどうかにかかっています。分かりやすく言うと、FaceNetは、データの前処理、Inception ResNet V1、そして学習済みの距離のしきい値によるデータ分離により構成されるパイプラインです。
トレーニング
最も多くのデータを持つ者が勝つ。これは機械学習においては特に重要です。私たちの場合は、攻撃生成モデルを正確にトレーニングするのに十分な大きさのデータセットは必要でも、他の多くのケースに比べると小さくて済むと考えました。これはなぜなら、私たちの目的はただ単に、下に示された人物A(ジェシー)と人物B(スティーブ)の2人だけを対象に、FaceNetに入力したときに生成される2つの顔埋め込みの間の「距離」を最小化し、かつどちらの方向にも誤分類されるような画像操作を行うことにあったからです。言い換えれば、ジェシーはパスポート写真ではジェシー自身として見え、しかしシステム上ではスティーブとして分類される(逆もまた然り)必要がありました。顔の埋め込みと視覚化については、後に詳しく説明します。
トレーニングは、動画から静止画としてキャプチャされた、2人のうちそれぞれ1500の画像群により行われました。トレーニングデータをより豊富にし、また有効なパスポート写真を撮ろうとする人物を正確に再現するよう、様々な表情や顔の動きを含めた画像で構成されています。

人物A画像(ジェシー、左)と人物B画像(スティーブ、右)
データが用意できたところで、研究チームはCycleGANとFaceNetからなるアーキテクチャを導入し、モデルの訓練を開始しました。
下の画像からわかるように、生成器からの初期出力は非常に粗いものです。これらは確かになんとなく人間のように見えますが、容易には識別できず、また「アーティファクト」と呼ばれる明らかな摂動があります。

生成された人物A(左)と生成された人物B(右)
しかし、何十ものサイクル、エポックにわたるトレーニングを進めるにつれて、いくつかのことが見て取れるようになりました。人物Aと人物Bの顔の特徴をブレンドしながらも、歪みが少なくなっていき、結果、(ちょっと怖いですが)次のような画像ができあがったのです。

両方の人物の特徴が混ざり合わさった顔
トレーニングのエポックがさらに進んでいくと、識別器は生成器の出力画像に、より満足し始めます。まだまだ歪みはありますが、画像はだんだんと人物Bのように見え始めています。
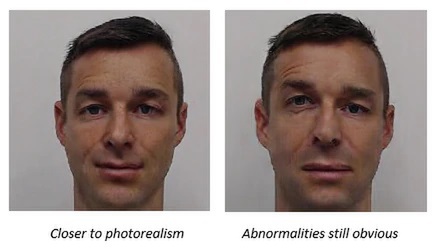
本物の人物写真により近い画像(左)と歪みがまだ明らかな画像(右)
数百の訓練エポックを終えたところで、有効なパスポート写真として認められるという私たちの目的に見合うような画像の候補が生成されました。

人物Bの偽画像
このトレーニングプロセスを繰り返すたびに、結果は体系的に顔認識ニューラルネットワークに送られ、人物Aまたは人物Bに分類されています。このことは重要です。なぜなら、もう1人の人物の画像として「適切に誤分類」されない画像は、今回の検証の目的を満たさないため拒否する必要があるからです。GANと他のニューラルネットワークをこのように緊密に連携させ反復させるアプローチをとった研究プロジェクトは非常に少なく、本研究はこの点においても斬新です。
上の写真でわかるように、この時点で生成されている顔の画像はとてもリアルで、人間が見てもコンピュータ生成ではないと信じるレベルに達しつつあります。ここで、このシステムが実際にどのように機能しているのかを明らかにするため、少し舞台裏を覗いて、いくつか顔埋め込みの視覚化を見てみましょう。
顔の埋め込みをより深く理解するため、以下の画像を利用して概念を視覚化してみます。下に示されているのは、トレーニングに使用されたものと生成されたもの、つまり元のデータセットに含まれていた本物の人物画像と、生成された偽の(敵対的な)画像です。

モデル画像(トレーニング– Real_AおよびReal_B)と生成された画像(Fake_BおよびFake_A)
これらの画像は、今回のモデルによる1エポックにおけるものすぎません。既にかなりリアルな偽画像を生成していることからもわかるように、より後の方のエポックからの抜粋です。
これらの画像を数学的な埋め込みとして表示するには、多次元空間において、画像を表す視覚化イメージを作成します。これを回転することで、1つの次元における距離を見てとることができます。片側に「Real_A」と「Fake_B」のクラスタがあり、もう一方に「Real_B」と「Fake_A」のクラスタが別に存在するのを簡単に見てとることができます。ここから、このモデルが共犯者の偽の画像と、攻撃者の本物の画像を同一人物として誤分類することがわかり、私たちの目的が達成されたことになります。これは理想的な攻撃シナリオです。
ホワイトボックスとグレーボックスへの適用
機械学習では多くの場合、モデルは効果的に訓練され、また、将来的な応用において結果を再現および複製できる必要があります。例えば、食品画像分類器について考えてみましょう。画像に表示される食品の種類を正しく識別してラベル付けするシステムのことです。食品画像分類器は、膨大なトレーニングによって、フライドポテトとカニの脚を区別することができるようになります。しかしそれだけでなく、初めて見る食品の画像でも高い精度で分類を再現できなければなりません。私たちのモデルは、2人(敵対者と共犯者)だけを対象に特別に訓練され、分類もトレーニング中に事前に行われるという点で多少異なります。つまり、攻撃者のリアルな偽画像を生成して、それが共犯者として分類されれば、そこでモデルの仕事は完了するのです。ここで重要な注意点として、本研究のモデルは、本番環境で使用される顔認識と同様に、人物を正しく認識・区別するために確実に機能しなければならないということがあります。
これは、転移性の概念に基づいています。開発段階で選択されたモデルや機能(モデルのコード、内部状態と事前訓練のパラメータに関する全ての情報が明らかなホワイトボックス)が、現実世界のモデルや機能(コードや分類子の不明なブラックボックス)と十分似ていさえすれば、基盤となるモデルアーキテクチャが大きく異なっていても、攻撃は確実に転移するのです。これは多くの人にとってまるで信じられないような概念です。モデルが「敵対的な入力」をどのように分類するかを予測するためには、攻撃者はすべての機能、コードの一行一行、そしてすべての出入力を理解する必要があるのではないか、そう思っても不思議はないでしょう。結局のところ、古典的なソフトウェアセキュリティはほとんどがそのようにして機能しているのです。攻撃者は、コードの直接読み取り、あるいはリバースエンジニアリングによって、バグを引き起こす的確な入力を見つけ出します。しかし、モデルハッキング(しばしば敵対的機械学習と呼ばれる)を使用すると、ラボで開発した攻撃を、ブラックボックスシステムに転移することが可能となるのです。ただし、この作業では、ホワイトボックスとグレーボックスの攻撃が行われ、将来の作業では顔認識に対するブラックボックス攻撃に焦点が当てられる可能性があります。
前述したように、ホワイトボックス攻撃は、研究者自身がモデルを構築したか、オープンソースアーキテクチャを使用しているかのどちらかの理由により、基礎となるモデルの情報が全てわかった上で開発された攻撃手法です。私たちの場合は両方が当てはまります。今回の検証に最適な先述の組み合わせを特定するため、CycleGANをさまざまなオープンソースの顔認識モデルに統合して検証を行ったためです。グーグルによる実際のFaceNetはプロプライエタリですが、研究者たちによって非常に似た機能を持つオープンソースのフレームワークが再現モデルとして開発されています。本研究で使用したInception ResNet V1もその一つです。これらの再現モデルはホワイトボックスとブラックボックスの中間あたりにありますので、「グレーボックス」と呼ぶことにします。
上記の概念を理論から現実世界に移すには、パスポートスキャナの役割を果たす物理システムを実装する必要があります。実際の標的であるパスポート検証システムは使用できませんので、ここでは自宅やオフィスのデスクトップに外部装備されているようなRGBカメラを使います。このようなカメラは基本的には、パスポート検証システムのカメラと同じような技術を採用しているはずです。パスポートシステムのカメラがどのように機能するのかはある程度憶測にたよるしかないので、可能な限りの代替品で良しとします。検証ではまず、動画から個々のフレーム全てをプログラムによってキャプチャし、検証の間メモリに保存しておきます。その後、いくつかの画像変換を適用し、キャプチャされた画像をパスポート写真となるような小さなサイズと適切な解像度に加工します。最後に、各フレームを、私たちが開発した学習済みのモデルに入力し、画像にある特定の顔が人物A(攻撃者)か人物B(共犯者)かを判断させます。モデルは、体勢や体位、ヘアスタイルなどが変化してもなお誤分類を引き起こすよう、両方の人物に関する多数かつ多様な画像で十分に訓練されています。この攻撃方法では、攻撃者と共犯者が連携しており、学習済みのデータセット内の元の画像とできるだけ似せて見せようと試みる可能性が高いでしょう。これにより、誤分類はさらに確実となります。
実際の検証例
次のデモ動画は、グレーボックスモデルを使用した攻撃の実際の検証の様子です。この動画の3人の登場人物を紹介しましょう。3つのテスト全てにおいて、スティーブは攻撃者、サムはランダムテスト用の人物、ジェシーは共犯者です。1つ目の動画はポジティブテストです。
ポジティブテスト:
このテストでは、画面右に示された、スティーブ(攻撃者の役)の実物・非生成画像を使用します。まず、私たちのランダムテスト対象(サム)が「パスポート検証カメラ」の前に立ち、その場でスティーブの実物の画像と比較されます。無論、異なる人物として分類されます。次に、スティーブがカメラの前に立ち、モデルは、非加工画像のデータセットにある実物の写真に基づいて、彼を正しく識別します。これにより、システムがスティーブをスティーブとして正しく識別できることが証明されます。
ネガティブテスト:
次に、ネガティブテストです。ここでは、システムがジェシーの実物の写真に対してサムをテストします。予想通り、彼は同一人物でないとして正しく分類されています。その後、スティーブがシステムの前に立ち、ここでもジェシーではないと正しく分類されることが確認されます。これによって、モデルが非敵対的な状況において、人物を正確に区別できることが示されました。
敵対テスト:
最後に、3番目の動画では、サムが私たちのモデルによって生成された敵対的、つまり偽のジェシーの画像に対して分析されます。サムは、誤分類を引き起こすように設計されたCycleGANのトレーニングの一部ではなかったので、ここでも再び異なる人物として正しく分類されています。最後に、攻撃者のスティーブがライブカメラの前に立つと、ジェシー(共犯者役)として正しく誤分類されます。モデルは、ジェシーまたはスティーブのどちらが敵対的画像となっても正しく誤分類するように訓練されています。ここでは、偽/敵対的画像にジェシーを選択しています。
このシナリオでパスポートスキャナが人間に完全に置き換わったとしたら、システムはたったいま、攻撃者がパスポートデータベースに保存されている共犯者と同一人物であると認証してしまったことになるのです。共犯者は搭乗禁止リストには登録されておらず、他の制限もありません。ですから、攻撃者はこの重要な検証ステップを回避して飛行機に乗ることができます。人間であれば、共犯者と攻撃者を間違えることはないのではないでしょうか。しかし、この研究は、人間による認証といった多重なセキュリティ対策なしで、AIやMLのみに依存することに伴う固有のリスクを示しています。
ポジティブテスト動画 — 人物をその人自身として認識する能力を確認
ネガティブテスト動画 — 異なる人物を区別する能力を確認
敵対テスト動画 — 敵対的画像による誤分類を確認
この研究から学べること
個人の認証や検証を生体認証技術に依存する例は増え続けており、多くの場合において、パスワードやその他のより信頼性の低い認証方法に事実上取って変わろうとしています。しかし、顔認識モデルの内部構造は十分に理解が進んでおらず、モデル特有なセキュリティ上の弱点を考慮せずに自動システムや機械学習に頼ることは、サイバー犯罪者に自動パスポート管理などの重要なシステムをすり抜ける能力を与えることにも繋がるのです。私たちの知る限り、モデルハッキングと顔認識を応用したアプローチはこの研究が初となります。データサイエンスとセキュリティ調査の力を活用することで、私たちは顔認識といった重要なシステムの販売者や運用者と緊密に連携し、セキュリティをゼロから設計して、これらのシステムの脆弱性を補強する所存です。今必要とされているのは、敵対的サンプルの存在下において機械学習システムの信頼性をしっかりと推論する上での基準を設定することでしょう。このような基準は、暗号手法、プロトコル、無線周波数などを含むコンピュータセキュリティの多くの市場に存在します。認証などの重大な役割をブラックボックスに任せ続けるのであれば、敵対的な状況下においての回復力(レジリエンシー)とパフォーマンスの許容範囲を定めた枠組みを用意する必要があるでしょう。
※本ページの内容は2020年8月5日(US時間)更新の以下のMcAfee Blogの内容です。
原文:Dopple-ganging up on Facial Recognition Systems
著者:Steve Povolny
共著:ジェシー・チック(Jesse Chick)、OSU(オレゴン州立大学)4年生、元マカフィー インターン/初等研究員
※本記事はアスキーとマカフィーのコラボレーションサイト「せきゅラボ」への掲載用に過去のMcAfee Blogの人気エントリーを編集して紹介する記事です。

■関連サイト
本記事はアフィリエイトプログラムによる収益を得ている場合があります



