




Lake Crestの後継となる
深層学習用プロセッサーSpring Crest
さてそのSpring CrestことNNP-Tは、2つのTensor Coreを組み合わせたTensor Core Cluster(TPC)を24個搭載。PCI ExpressもGen4としたほか、メモリーを2.5MBに増やしている。製造プロセスはTSMCの16FF+を利用、ダイサイズは680mm2とされる。
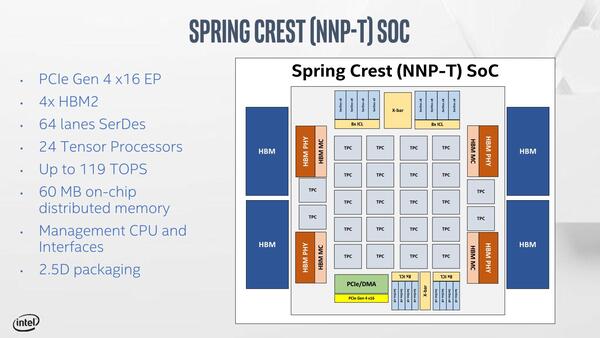
Spring CrestことNNP-Tの概要。実質的にはコアの数がLake Crestの4倍になった計算である

HSIOはHigh Speed I/Oで、外部リンクをこれでまかなうと思われる
下の画像はTPCの内部構造で、2つのTensor Processorとローカルメモリー、Convolution Engineなどを共有する構造になっている。
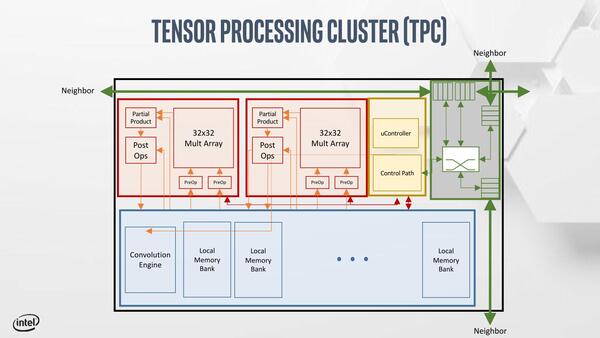
TPCの内部構造。Local Memory Blockは複数バンクに分割されているようだが、サイズなどは不明
個々のTensor ProcessorはBFloat16の演算ユニットを32×32個アレイ状に配した構成で、1サイクルあたり2048演算(乗算+加算)が可能である。

Tensor Processorの構成。BFloat16のユニットを2つ組み合わせてFP32もサポートできる模様。当然その場合性能は半減する
1TPCあたりなら1サイクルあたり4096演算。これが24個で、1.1GHz駆動ということで 1.1GHz×24×4096=108.1344TOPsとなる。
さらに、TPCの共有部にはConvolution Engineが専用に搭載されており、これは上の画像のCompute Unitとは並行して稼働するようなので、これの処理分も含めると119TOpsという数字になるのだと思われる。
なおそれぞれのTPCは2Dメッシュ構成での接続になっており、すべての周辺機器やI/Oに均一にアクセス可能になっている。
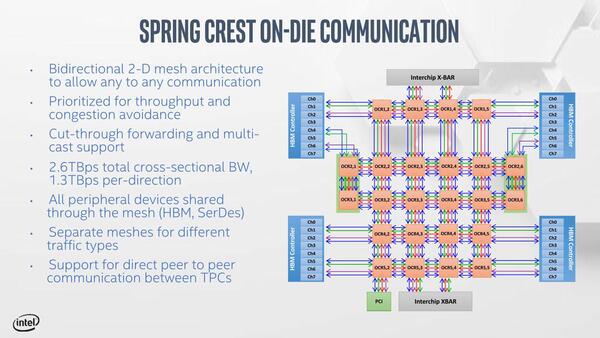
ここでRing Busではなく本当にBi-DirectionalなLinkを使っているあたりで、インテルではなくNervanaの設計だなという気がする
またスケーラビリティーにも配慮されており、最大1024ノードまでの接続が可能とされる。ちなみに性能の一端も公開された。

これは、3枚目の画像に出てくるような評価ボード8枚を1つのシャーシに入れることを前提にした模式図と思われる。ちなみに1つのシャーシ内に8ノードで、これ全体だと32ノードという計算になると思われる

NNP-Tの性能。サイズに応じて学習の効率が変わるが、小さくても大きくてもなかなか性能が出ないので、HBMの容量をにらみながらサイズを決める必要があるという話。ちなみにピークでも57.4%というのは、もう少しなんとかならなかったものか?

Convolutionの効率。こちらは専用ユニットを設けていることもあってか、どのケースでもそれなりに効率が高い
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















