




クラスター単位で処理を実行する極端な構造
汎用性がないため独自にソフトウェアを供給
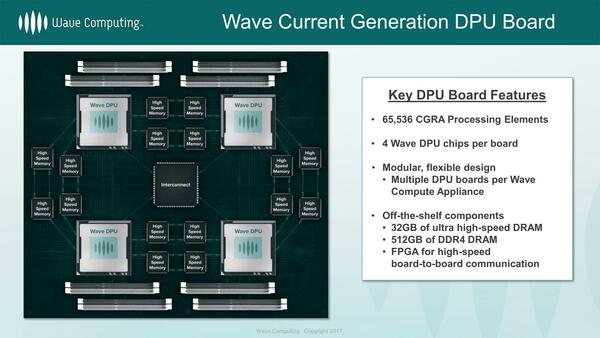
このDFPは単体で使うのではなく、1枚のカードに4つ搭載し、相互をインターコネクトでつなぐという形態になっていた。
先の画像と見比べると、チップ間のインターコネクトはPCIe Gen3 x16になるのだが、遅すぎる気がしなくもない(あとFPGAで構成する必要もない)。実は先の画像ではDFP同士のインターコネクトが省かれてるだけなのかもしれない
ここで注目すべきは「High Speed Memory」で、これはおそらくHMCのことである。要するにHMC同士も相互接続するというかなり無茶な構成であり、確かにHBMでは実現できなかっただろう。
この1枚のボードで、32GBのHMCと512GB DDR4を搭載し、ピーク演算性能724Topsというお化けプロセッサーが実現できるわけだ。NVIDIAのTesla V100が125TFlops(=125Tops)でメモリーは32GBでしかないから、Tesla V100の数倍の性能ということになる。
Wave Computingでは、このカードを複数枚装着した3Uのラックサーバーなども想定していたが、実機が存在したかどうかは不明である。
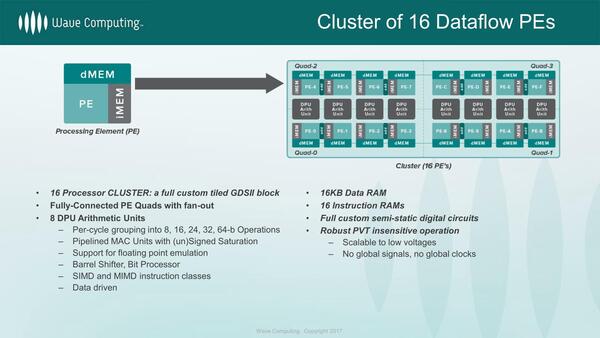
もう少し内部構造を説明しよう。PE(Processor Element)の構成が下の画像である。命令は256個で、しかもCircular Bufferというのは、同じ処理をひたすら繰り返す前提である。DSPにあるZero Overhead loopの機能をもっと極端に実装した格好だ。

PEの構成。4つのPEはお互いに密につながっているが、これが演算の最小単位ではない
演算器は、図の中の黒い矢印のルートは高速に処理が可能な仕組みになっており、他のPEとデータをやり取りしながらだと多少遅くなると思われる。
このPEが16個と、その間に挟まるDPC Arithmetic Unit×8で、1つのクラスターを構成する。DPC Arithmetic Unitは完全に非同期で、データをここに送り込んだ瞬間に演算をスタートし、終わると終了するというデータドリブン方式で駆動される。演算の最大単位は64bitで、これを8/16/24/32bitに分割することも可能とされる。
24bitというデータ長、昔はちょくちょく見かけた(6bitマシンのDouble Wordが24bit)が最近はまったく見かけない。どういう意図でこれをサポートしたのか不明である
余談だが、先に181Topsという数字があった。これが1万6384個のPEと8192個のDPU Arithmetic Unitで同時に処理した数字で、かつDPU Arithmetic Unitは8bit×8の演算だと仮定すると、1サイクルあたり81920Opになるので、動作周波数は2.2GHzあたりになる計算だ。TSMCの16FF+ならなんとかなる、という数字な気がする。
そしてこのクラスターを単位に、処理の受け渡しをする仕組みになる。つまりあるクラスターで畳み込みをしたら、次のクラスターで活性化を行う、という具合にするわけだ。
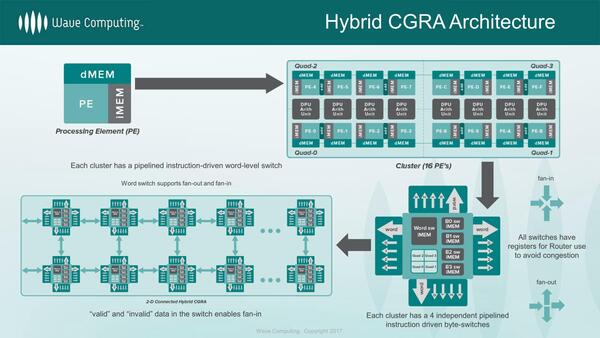
PE単位ではプログラミングも大変であり、クラスター単位で管理することで適度な抽象化を狙ったのだろう
ちなみにクラスターそのものは演算しかしないので、データの移動はDMAユニットが行なうことになる。逆に言えばDMAユニットとクラスターが同時に動くことで、演算とデータ移動を同時に実行できる仕組みだ。
この用途のために、クラスター(というよりPEの塊)の周囲を、32個のDMAエンジン(AXI 0~AXI 31)が囲み、その外側にAXI4のインターコネクトが広がるという、これもこれで極端な構造になっているわけだ。1つのDMAエンジンには最大64個のクラスターを接続可能である。これは可変にもできるようだ。
ここまで特異な構造では、当然通常のフレームワークはそのままでは動作しないので、WaveFlow Agent LibraryやWaveFlow Session Manager/WaveFlow Execute Engineと呼ばれるソフトウェア(や、WaveFlow SDK)がWave Computingより提供された。
これを利用して既存のフレームワークをDFPで動く形に変換して処理することになるのだが、では性能は? というのが下の画像である。

2015年ごろなら驚異的な性能としてもよかっただろうが、2017年では……
これだけでは数字がどの程度速いのかよくわからないかもしれないが、例えばAlexNetの例で言えば、元の論文によれば2枚のGeForce GTX 580を使って学習に5~6日かかっていたのが40分で完了しており、GeForce GTX 580比で400倍ほど高速ということになる。
GoogleNetの場合で言えば、GeForce GTX 1080がおおむね200枚/秒の学習速度とされており、コンテスト規定の120万枚の処理に要する時間は6000秒ほど。つまり1時間40分ほどでしかない。要するにDPU(Data Processing Unit)の性能はGeForce GTX 1080程度だった、という見方もできる。
いろいろ策を講じたわりにはあまり性能が出ない、というのがWave ComputingのDFPの評価ということになる。
もっともこのあたりはいろいろ検討の余地はあり、実際発表の際には第2世代に関する話もちらちら入れていたこともあって、ファンド筋からの評価は良く、追加投資も行なわれたようだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























