




AIの大まかな話は前回説明した通りだが、もう少し細かく「なにをやっているか」を今回説明したい。
やや古い話であるが、GTC 2015においてFacebookのRob Fergus氏が“Visual Object Recognition Using Deep Convolutional Neural Networks”というトレーニングコースを実施しており、現在もGTC オンデマンドで視聴できる。
25分ほどの短いセッションで、英語も平易なのでわかりやすいが、こちらのスライドをもとに、そもそもConvolutional Neural Networkではどんな計算処理が必要かを細かく説明していこう。
コンピューターに文字や画像を認識させる
畳み込みニューラルネットワーク
そもそも畳み込みを使うConvolutional Neural Networkを最初に提唱したのは、Facebookに在籍しているYann LeCun氏らによる“Backpropagation Applied to Handwritten Zip Code Recognition”という1989年の論文である。
これは手書きの郵便番号を認識するシステムで、0~9の数字が認識できればいいわけだが、これの認識に下の画像の下側のようなネットワークを考案した。

郵便番号を認識するシステム。右上がYann LeCun氏。これは氏がまだAT&Tのベル研究所にいた時のものである
このネットワークは学習の完了後に1%程度のエラー率で手書きの数字を認識でき、またAT&TのDSP-32Cという汎用DSP(性能はピークで25MFlops)に実装したところ、毎秒30回の認識できたとする。アメリカの場合は郵便番号が5桁なので、つまり毎秒6つの郵便番号を認識できることになる。
前回紹介したAlexNetに比べるとだいぶシンプルではあるが、10種類の文字の認識程度であればこれでも十分、という話である。
LeCun氏のネットワークの場合、まず畳み込みを2回繰り返し、その後で3層の全結合が行なわれる。意味合い的には、最初の2層の畳み込み層で、入力画像をいわば部品に分解、続く3層でその部品の結果を組み合わせて最終的な判断をする形になる。
画像を調べて特徴を抽出する
「畳み込み」
そこでまずは畳み込み層の説明をしよう。ここは畳み込み→非線形関数→サブサンプリングという3つの作業からなる。
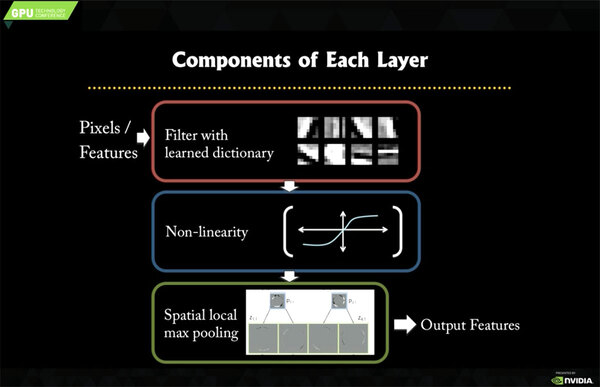
非線形関数(Non-linearity)は、活性化関数と呼ぶことも多い。前回触れたニューロンの「発火」にあたる処理である
さてその畳み込み、確か高校までの数学には出てこなかった「気がする」(なにしろ高校卒業なんてもう40年近く前なので……)。おそらく大学の教養課程の数学で学んだか、物理数学の時間だったかもしれないと思うのだが。
数学的に言えば、2つの関数の重ね合わせのことを畳み込みと表現する。ただここで数式を並べても意味がないので実例で説明したい。
下の画像は、入力画像(左側)とフィルター(Inputの右下:Kernelとも呼ばれる)の畳み込みを行なった出力(Feature Map)を示したものだ。

このフィルターそのものは、学習フェーズで自動的に生成される。というより、このフィルターを生成するために学習というステージが発生する
ここでどんな処理をしているかというのが下図である。要するに左上から右下まで、フィルターの位置を少しずつずらしながら、入力画像とフィルターを重ね合わせ、合計値をFeature Mapとして出力する形になる。

畳み込みの仕組み
図の例で言えば、Feature Mapの1ピクセルを出力するのに乗算と加算がそれぞれ9回必要になるので、1枚(図の例なら6×6pixel)を生成するのに324回の乗算と加算が必要になる計算だ(*1)。
(*1) ここの例ではFeature Mapのサイズを入力画像より小さい6×6にしているが、精度を上げるために同じ8×8にするといったことも当然可能である。この場合は計算回数が576回に増えることになる。
ちなみにフィルターは1種類ではない。したがって、複数のフィルターを掛け、複数のFeature Mapを生成する必要がある。

異なるフィルターを掛けると、当然Feature Mapの出力も変わってくる
下の画像は2012年のAlexNetで利用されたもので、合計96種類のフィルターが利用された。
- 入力画像は224×224pixel×24bit(RGB)
- フィルターは11×11pixel×24bit(RGB)

AlexNetの場合、2枚のGPUを使って学習しており、上半分がGPU #1、下半分がGPU #2により生成されたそうだ
このAlexNetの場合、1枚のFeature Mapを生成するのに必要な計算数は1662万3948回。しかもフィルターは96種類あるので、15億9589万9008回の乗算と加算が必要ということになる。
もうこのあたりで、だいぶ桁が大きくなっている。ちなみにこれはあくまで1層分である。冒頭のLeCun氏のネットワークでも畳み込みは2層、AlexNetでは5層もあるので、それは計算量が多いわけだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























