



21.5cm角の独自開発半導体に40万コア+18GBメモリ搭載、既存の機械学習システムを超高速化
TED、深層学習専用アクセラレーターマシン「CS-1」受注開始
2019年12月20日 07時00分更新

東京エレクトロン デバイス(TED)は2019年12月19日、米国セレブラス・システムズとの販売代理店契約締結を発表し、同日よりセレブラスが開発するディープラーニング(深層学習)高速化システム「CS-1」の受注を開始した。

セレブラス・システムズ(Cerebras Systems)の「CS-1」筐体。15Uサイズ、内部循環冷却液を用いた空冷方式で、一般的なデータセンターにも設置できる
CS-1は、ディープラーニング専用に設計された大型半導体「Wafer-Scale Engine」を内蔵し、ディープラーニングのトレーニング処理を大幅に高速化するシステム。同日の記者発表会にはTEDのほか、セレブラス 共同創設者兼CTOや製品管理ディレクターも出席し、ディープラーニングにまつわる課題やCS-1の特徴、販売ターゲット領域などを説明した。

米セレブラス・システムズ プロダクトマネジメントディレクターのアンディ・ホック(Andy Hock)氏。手にしているのが同社開発のディープラーニング専用半導体「Wafer Scale Engine」。21.5cm角という“世界最大の半導体チップ”だ

セレブラス・システムズ 共同創設者兼CTOのギャリー・ラウターバック(Gary Lauterbach)氏

東京エレクトロン デバイス 執行役員 CN BU 副BUGMの上善良直氏
ディープラーニング処理専用、40万コア搭載の巨大チップを開発
セレブラスは2016年に設立された、シリコンバレーに拠点を置くコンピューターシステム開発のスタートアップだ。半導体チップやコンピューターシステムのエキスパートが集まってスタートし、「これまでのコンピュートを完全に刷新する」ことをミッションにしていると、共同創設者兼CTOのギャリー・ラウターバック氏は説明する。現在は200名以上のソフトウェア/ハードウェアエンジニア、機械学習の研究者を抱える規模になっている。
ラウターバック氏は、AIには大きな可能性があるものの、今日ではまだ「コンピュートの能力が足かせ(制約)となって」可能性が発揮されていない、と指摘する。たとえばディープラーニングにおいては、モデルを大規模化させれば(階層を増やせば)判断精度を高める(複雑な判断を正確に行う)ことができるが、それに伴ってトレーニングにかかる時間も大きくなる。数日、数週間、数カ月かかるようなケースもある。
そこでセレブラスは、CPUやGPUといった従来の汎用プロセッサではなく、ディープラーニング処理に特化した専用エンジンを設計開発するという新たなアプローチを試みた。この専用エンジンがWafer-Scale Engine(WSE)だ。
その名のとおり、WSEは直径300mm(12インチ)のシリコンウェハから取れる最大サイズの“チップ”である。通常のプロセッサ製造は1枚のウェハを多数に分割するが、WSEの場合は1枚のウェハから1個だけというわけだ。ここに16nmプロセスで1.2兆個のトランジスタを搭載し、ディープラーニングに特化した40万のコア(疎線形代数演算コア)と18GBのSRAMオンチップメモリを構成している。メモリ帯域は9.6PBps(9.6ペタバイト/秒)コア間のインターコネクトは「Swarm」と呼ばれる2次元メッシュ構造のファブリックで、100Pbps(100ペタビット/秒)の大容量を実現している。

「Wafer-Scale Engine(WSE)」の概要。写真右下のチップは、現在の市場で最大のGPU(NVIDIA V100)チップ
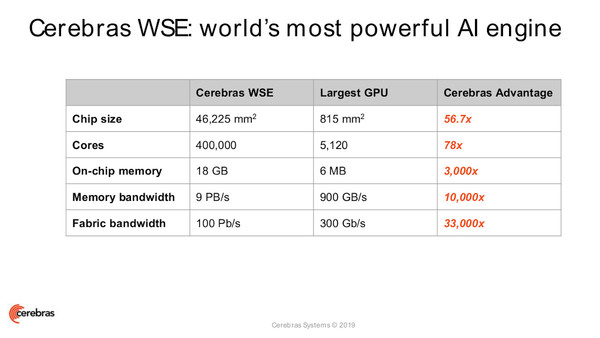
WSEと、現在よく利用されているGPUとのスペック比較
Cerebras CS-1は、このWSEを1つ組み込んだシステムである。筐体は15Uラックサイズ、最大消費電力は20KW、内部循環冷却液を用いた空冷システムで、一般的なデータセンターに設置できる設計だ。実際には外部の標準的なサーバーとネットワーク接続し、AIワークロードのうちディープラーニング処理だけを専門に行うアクセラレーターの位置付けだ。ネットワークインタフェースは100GbE×12(つまり1.2Tbps)の容量を備える。
ワークロードのアクセラレーターとしてCS-1/WSEを利用するためのソフトウェア「Cerebras Software Platform」も用意されている。これは「TensorFlow」「PyTorch」「MXNet」など主要な機械学習フレームワークに対応したライブラリやコンパイラを備えており、既存のAIワークロードを大きく変更することなく処理を高速化できる仕組みだ。

主要な機械学習フレームワークとCS-1を統合するソフトウェア「Cerebras Software Platform」も提供している。WSEを分割して使い、複数層のトレーニングを並列処理させたり、マルチテナントの活用も可能だと説明した
セレブラスでは、すでに米国で複数の顧客にCS-1を納入開始しており、TensorFlowを含むワークロードを実運用しているケースもあるという。セレブラスの製品管理ディレクターであるアンディ・ホック氏は、そこでは「100倍から1000倍の処理速度向上を確認している」としたが、まだそうした顧客とのチューニングを進めている段階であり、パフォーマンスのベンチマーク数値については公開していないと述べた。
大規模なディープラーニングモデル開発における課題を解消する
ホック氏は、CS-1の導入により考えられるメリットを説明した。たとえば、これまで処理に数カ月かかっていたトレーニングを数千倍高速化し、数時間、数分レベルまで短縮することで、さまざまなアイデアを繰り返し試せるようになる。あるいは、従来よりも1000倍大規模な教師データを用いてトレーニングを行い、より精度の高いモデルが生成できる。そのほか推論処理の高速化、より深い層/幅広い層を持つモデルの開発なども実現可能になると語る。
TED 執行役員の上善良直氏も、CS-1の提供によって、顧客におけるより高度なディープラーニング活用が進むだろうと、同製品への期待を語った。
「たとえば2年ほど前、自動運転の開発に携わる顧客に話を聞いたところ、道路を道路と認識させるためには高精度な教師データを用いる必要があり、当時のGPUクラスタでは『トレーニングに1年ほどかかる』と言われた。これが1000倍高速化すれば、その1年が数日に短縮され、そのぶんモデルの精度も高まることになる。逆に言えば、CS-1のようなシステムがなければ、そういうことはできないということだ」(上善氏)


TEDではセレブラスの将来性に目を付け2017年に覚書を締結、製品出荷に至るまでをサポートしてきたという。顧客企業にはトータルな提案/サポートを図る
CS-1のターゲット顧客としては、まずは現状でディープラーニング向けに大規模なGPUクラスタを設置しているような学術/研究機関、Web/インターネット企業、製造業、小売業などになる。TEDでは、CS-1とその周辺を取り巻く低遅延ネットワーク、サーバーも含めて提供していく方針だ。CS-1の価格は個別見積もりだが、上善氏は「数億円のオーダー」だと説明した。
またTEDでは、東京の拠点内にCS-1デモ機を設置した「TED AI Lab(仮称)」を2020年上旬に開設する計画だ。ここでは顧客データを用いたオンサイト/リモートのPOC(実証実験)を有償サービスとして提供するほか、導入コンサルティングや各種サポートも提供していく。また上善氏は、将来的には「時間貸し」のような、CS-1をサービス型で提供するビジネスも検討していきたいと語った。TEDでは、3年間で100億円の売上を目標としている。

CS-1のデモ機を設置した「TED AI Lab(仮称)」開設も計画している
本記事はアフィリエイトプログラムによる収益を得ている場合があります



