



クラウド上でHANA+各種データストア接続+データパイプライン、「SAPPHIRE NOW 2019」レポート
「SAP HANA Cloud Services」発表、HANAをあらゆるデータへの入口に
2019年05月15日 07時00分更新

独SAPは、2019年5月7日から9日まで米国で開催したプライベートイベント「SAPPHIRE NOW 2019」において、インメモリ技術を利用した「SAP HANA」データベースをクラウドサービスとして提供する「SAP HANA Cloud Services」を発表した。HANAを考案した同社の共同創業者で現在スーパーアドバイザリボードのチェアマンを務めるハッソ・プラットナー氏は、これまでのHANAの進化を振り返りつつ、最新のHANA Cloud Servicesを紹介した。

SAPPHIRE NOW 2019で発表された「SAP HANA Cloud Services」

SAP 共同創業者で現在はスーパーアドバイザリボードチェアマンのハッソ・プラットナー(Hasso Plattner)氏
10年以上前に構想したインメモリ化のアイデアが「勝利した」と宣言
2日目の基調講演のステージに立ったプラットナー氏はまず、HANAの進化がどういう段階に来ているのかを説明した。
処理速度の上がらないデータベースが“リアルタイムエンタープライズ”実現のネックになっているという問題意識からその処理をインメモリ化する構想を抱いたプラットナー氏は、2006年、自身の研究機関であるHasso Platter Instituteにおいて研究開発をスタートした。4年後の2010年に製品化されたHANAは、現在までに5万ライセンスを販売している。最大規模の実装としては単一ノードで48TBメモリ、スケールアウトシステムで72TBメモリ、1日1億件のトランザクションを処理する顧客もあるという。
このHANAインメモリデータベースプラットフォーム上に構築されたERP「S/4 HANA」も顧客数は1万1000以上に及んでおり、製造業におけるMRP(Material Requirements Planning)処理は20倍以上高速に、データベース容量の圧縮率は7倍を実現しているという。

プラットナー氏は「40年前のエンタープライズコンピューティングにおける複雑性は、事前のアグリゲーション(データ統合処理)にあった」と述べ、HANAがもたらす「ほぼレスポンスタイムゼロ」のデータベース環境によって事前のアグリゲーションが不要になり、複雑性を解消できていると語る。
現在では、HANAプラットフォームによって「ほぼどのようなシステムでもDRAM(メモリ上)で動かすことができる」ようになり、10年以上前に構想した自身のアイデアは「勝利したと宣言してよいだろう」と胸を張る。
ちなみにIDCのデータによると、HANAがローンチされた2010年時点の世界総データ量は2000EB(エクサバイト)、現在は4万EBと20倍に増えており、さらに2025年には87.5倍の17万5000EBまで増大する予測だ。これについてはプラットナー氏も「わたしの予想は間違っていた」と認める。4万EBのうち、SAP ERPのデータ量が占めるのはわずか「0.000002EB」であり、「世界の中心は業務アプリケーションシステムにあると思っていたが、現実にはERPシステムはほとんど“見えない”。CRMがERPの成長を超えている」と語った。
「HANAをあらゆるデータへの単一のゲートウェイにする」クラウドサービス
プラットナー氏は、こうして進化を遂げてきたHANAを「SAPの業務アプリケーションだけに閉じ込めておくのはもったいない」と語る。そこでSAPが取り組んだHANAの新境地が、今回発表されたHANA Cloud Servicesである。その名のとおり、これはHANAデータベースをクラウドサービスとして提供するものであり、新たなデータモデルや処理タイプなどへの対応も進めた。
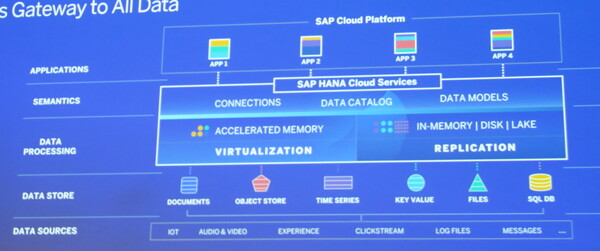
SAP HANA Cloud Servicesのアーキテクチャ。「SAP Cloud Platform」上のアプリケーションからさまざまなデータソース/データストアへのシームレスなアクセスを可能にする
HANA Cloud Servicesの開発を主導したSAP HANA & Analytics担当SVPのゲリット・カズマイアー氏は、HANA Cloud Servicesは「あらゆるデータへの単一のゲートウェイ」だと表現した。構造化データ/非構造化データ/オブジェクトデータに対応しているが、データ仮想化やレプリケーションの技術によって、データストアからデータを移動することなく高速なアクセスを可能にする。

SAPのSAP HANA and Analytics担当シニアバイスプレジデント、ゲリット・カズマイアー(Gerrit Kazmaier)氏
頻繁にアクセスするデータ向けにはSybase IQベースの「HANA Data Lake」を、データアーカイブ用途にはディスクストレージ拡張「HANA Disk Store」をネイティブで用意しており、さらに「Apache Hadoop」などのサーボパーティ製データストアにも直接アクセスできる。こうしたデータの階層化とパーティショニングによって「HANAの長所をクラウド時代に適用できる」と語った。オンプレミスの顧客も、HANA Cloud Servicesを利用することで柔軟にキャパシティを拡張できる。
SAPでは2017年にビッグデータ活用のためのデータパイプライン「SAP Data Hub」を発表しているが、今回のHANA Cloud ServicesにはこのData Hubも組み込まれており、柔軟なデータ処理やデータ管理も可能にしている。
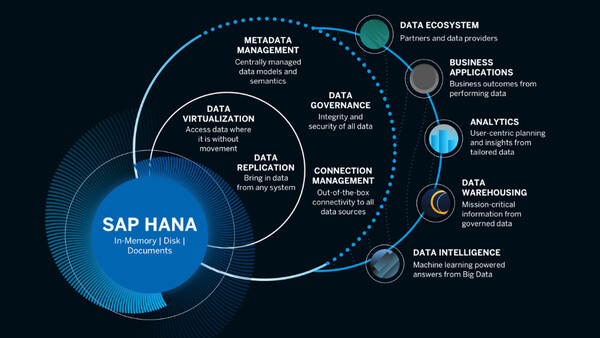
HANA Cloud Servicesが提供する機能群のイメージ。多様なデータソースに接続し、データ仮想化/レプリケーションによってHANAを「単一のデータゲートウェイ」にする
HANA Cloud Servicesの最初のアプリケーションとなるのが、データ管理ツールの「SAP Data Warehouse Cloud」だ。ビジネスユーザーが、自社保有のデータや社外のデータソースなどを簡単に組み合わせ、テンプレートと高度なアナリティクス機能を使って、相関関係を見たり洞察を得たりすることができるという。
デモでは、自転車メーカーのマーケティング担当者が、リアルタイムの売り上げデータとTwitterからのデータを組み合わせて、売り上げの増減とTwitterのセンチメントの上下の相関関係を確認、さらに掘り下げてみるとTwitterで新しい自転車のペダルについて苦情が出ていることがわかった。これを営業、製造、マーケティングなど関連するチームと共有して、対応するという流れを見せた。
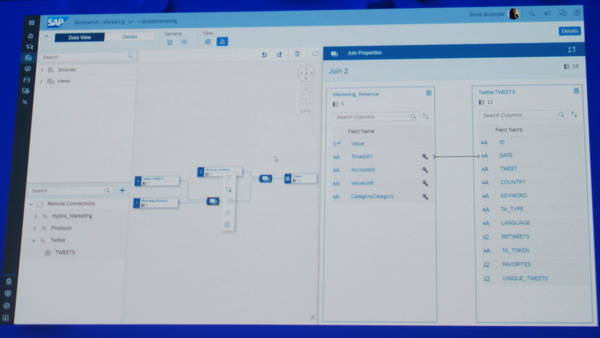
「SAP Data Warehouse Cloud」ビジネスユーザーが簡単にデータを取得したり、結合させることができる
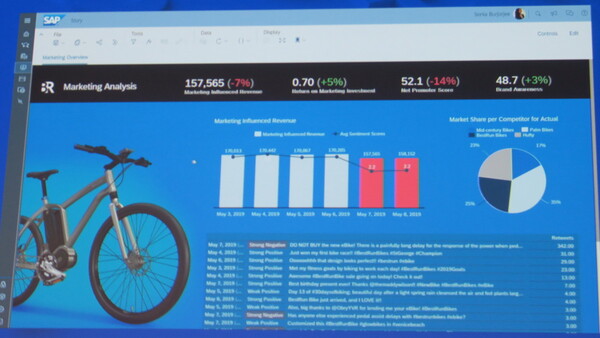
テンプレートを利用して2種類のデータの相関関係を調べ、さらに深掘りする
カズマイアー氏は、SAPアプリケーションのHANAプラットフォームへの移行についても触れた。
SAPではおよそ5年前から、提供するアプリケーション群をHANAプラットフォーム上に移行する作業を進めてきた。その移行作業は、SAP Ariba、SAP Concurの一部を除いて「ほぼすべて完了した」という。さらにアプリケーション/プランニング/シミュレーション/機械学習といった、連携するワークロード群が同一のプラットフォーム上で動くようになったことで、「HANAで高速化しただけでなく、ビジネスを改善するアプリケーションになった」と説明した。

SAPアプリケーション群のHANAプラットフォームへの移行は「ほぼすべて完了した」
SAPを中心に業務アプリケーション分野を追っているConstellation Researchの主席アナリスト、ホルガー・ミューラー(Holger Mueller)氏は、「HANA Cloud ServicesはHANAの対象をあらゆるデータソースに拡大し、ストレージの選択肢も備える。SAP顧客はインメモリの“牢獄”から解放される」と評価した。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



