



データガバナンス/データパイプライン/データ共有にまつわる課題を解決
ビッグデータ活用の障壁を解消する「SAP Data Hub」国内発売
2017年11月08日 07時00分更新

SAPジャパンは11月7日、企業のビッグデータ活用を促すデータソリューション「SAP Data Hub」の国内向け提供を開始した。データ処理のワークフロー定義を容易にし、DWHなどエンタープライズデータとの連携も可能にするなど、企業のビッグデータ活用を妨げてきたさまざまな課題へのソリューションを目指した製品。

「SAP Data Hub」の製品コンセプト。ビッグデータにまつわる複雑さや難しさを排除し、社内のあらゆるユーザーがビッグデータを活用できる環境を提供する

説明会に出席したSAPジャパン バイスプレジデント プラットフォーム事業本部長の鈴木正敏氏
グローバルのSAPでは今年9月末、SAP Data Hubを発表している。SAPジャパン バイスプレジデントの鈴木正敏氏によると、今回の国内提供開始を受けて、11月末から顧客向けのビッグデータ活用デモ環境を同社検証センター(SAPジャパン COIL Tokyo)に設置するほか、12月からは顧客向けのワークショップ、販売パートナー向けの技術セミナー/トレーニングも提供開始し、国内展開を本格化させていくという。
SAP Data Hubが実現する特徴について、鈴木氏は「データガバナンス」「データパイプライン」「データの共有」の3点を挙げた。
SAP Data Hubでは、企業が保有する多様なデータソースを統合的に管理/可視化すると同時に、社内でのデータの生成/加工工程もトレース可能にする(データガバナンス)。またデータ処理のワークフローはノンプログラミング/GUIツールで容易に定義でき、「新たなデータが追加されたら処理を実行する」といったデータ駆動型アプリケーションの開発も可能(データパイプライン)。そして、SAP HANAだけでない多様なSoRシステムとSoEシステム間でのデータのやり取りや、ビッグデータとエンタープライズデータへの統合アクセスを可能にする(データの共有)。分散処理エンジンのVoraはインメモリ技術をベースとしており、データを高速に処理できる点もポイントだ。
こうした機能を備えたSAP Data Hubが必要とされる背景について、SAPジャパンの椛田氏は、企業の積極的なビッグデータ活用を妨げている複数の「課題」を説明した。

SAPジャパン プラットフォーム事業本部 SAP HANA CoE シニアディレクターの椛田后一(かばたきみかず)氏
自社が保有するビッグデータを活用したいと考えている主体は、データアナリストだけでなくマーケティング部門、ビジネス部門、さらには経営層などさまざまだ。しかし、これまでビッグデータのクレンジング/成形/加工/集計といった処理にはPythonやScalaといったプログラミング言語をはじめとした専門的なスキルが必要とされた。専門スキルを持つ他部門から加工済みデータを入手しても、そのデータがいつ、どのように加工されたか、などの部分で不透明さが残る。また、ビッグデータ活用で「ビジネス価値」を生むためには、ビッグデータとエンタープライズデータを組み合わせて利用したいが、アクセス手段やポリシーが統合されておらず、それができない。
椛田氏は、こうした課題がビッグデータ活用の「壁」になっており、それを解消するのがSAP Data Hubだと説明した。
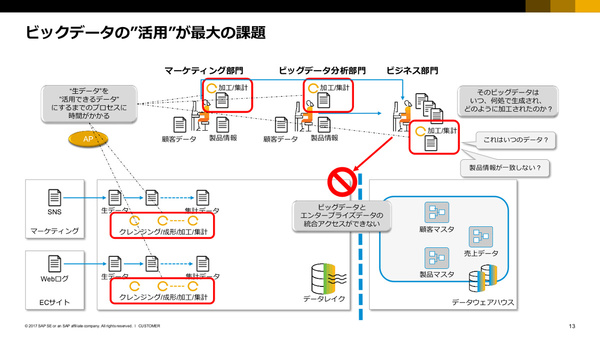
企業における積極的なビッグデータ活用を阻むさまざまな課題
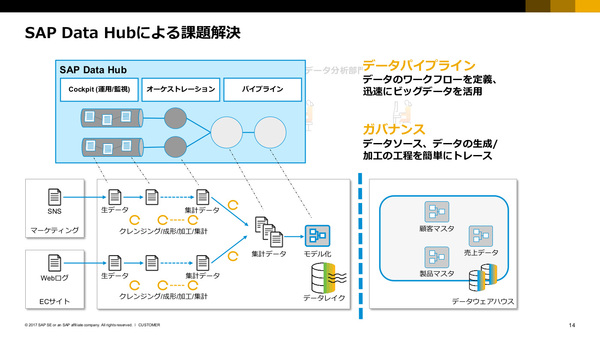
SAP Data Hubによる課題解決
SAP Data Hubは、データ処理環境全体のモニタリングやメタデータ管理、ワークフローのオーケストレーションなどを行う管理アプリケーション部分と、実際のデータ処理を分散クラスタ環境で行うエンジン部分とで構成される。このうち、処理エンジン部分にはSAP Voraが組み込まれている。
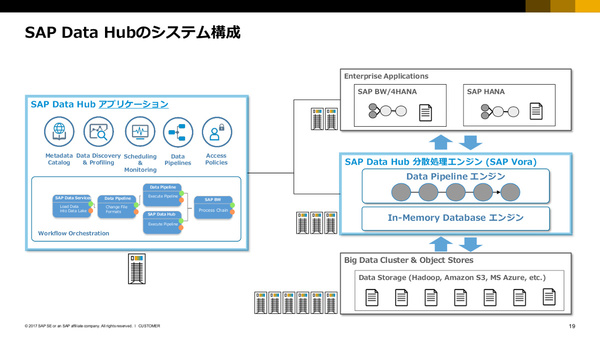
SAP Data Hubのシステム構成
今回のData Hub発売と同時に、SAP Voraのバージョンアップ(Ver 2.0)も発表されており、これによりオンプレミスのHadoopデータストアだけでなく、クラウドストレージ(Amazon S3、今後Azure Data Lakeにも対応予定)にも対応できるようになっている。加えて、Voraエンジン(Voraノード)そのものもDockerコンテナとしてデプロイされるようになり、クラウド上への実装も容易になった。ハイブリッドクラウド環境にも対応する。
SAP Data Hubは、「S/4 HANA」などHANA上のエンタープライズアプリケーションとのデータ入出力も容易だ。椛田氏は「SAP HANA、Vora、Data Hubを使うことで、エンタープライズデータとビッグデータの垣根をなくしてしまった、と言える」と説明した。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



