




3月27日(米国時間)、NVIDIAはサンノゼ市でGPU Technology Conference(GTC)を開催した。今年は参加者が9000人を越え、同イベントの来場者記録を更新している。

Quadro GV100を手にするジェンスン・ファン氏。GV100を搭載し、NVLinkで2枚のボードを接続できる
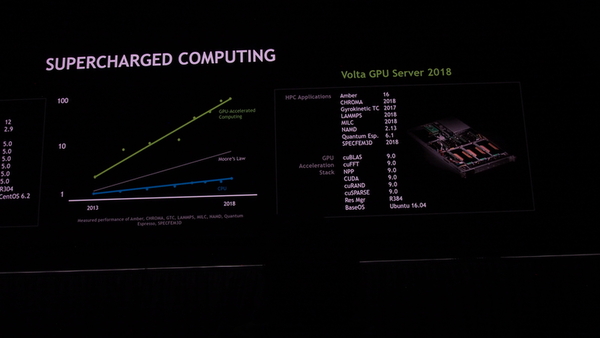
AIブームに乗った感のあるNVIDIAだが、他社と比べると参入やその後の製品展開がそもそも早かった。もともとGPUの計算性能のコストが安く、機械学習、深層学習の「学習」処理に必要な行列計算が安価にできたことから、同社のGPUを使う動きが2014年以前からあった。
2015年にNVIDIAは、AIや機械学習を重要分野と位置付け、同年のGTCで中心的な話題に据えた。また、モバイル用に開発したTegra SoCを強化、自動運転用などとして自動車メーカーへの働きかけを強めた。GPU自体も機械学習分野での学習性能などを考慮したPascalなどを開発した。実際のところ、その前世代にあたるKeplerアーキテクチャはあまり機械学習向けではなかった。このあたりの「変わり身」の速さが、同社をAIプラットフォーム企業へと押し上げたわけだ。
GTCの2日目には、同社CEOであるジェンスン氏が基調講演を行なった。講演内容は多岐にわたり、例年のことながら予定を30分以上オーバーしている。今回は冗談なども多く、昨年あたりに比べると、ジェンスンCEOに比較的余裕が感じられた。
さて、今回の発表のうち、主要なものを並べると
・32GB版Tesla V100
・Tesla V100を最大16個接続し、「巨大」なGPUを構成するためのNVswitch
・これを応用した16個のTesla V100を搭載するDGX-2ワークステーション
・32GB版Quadro GV100 GPU
・TenserRT4 推論Software
・DRIVE Constellation
・Drive Pegasus
などがある。また、基調講演では語られなかったが、当日の発表には、ARM社に対するNDLA(NVIDIA Deep Learning Accelerator)のライセンス供与がある。
最大16個のGPUを接続できる「NVSwitch」
講演の中心になったのは「NVSwitch」だ。これは、最大16個のV100プロセッサを接続するための専用チップである。昨年までは、毎年のように新しいGPUアーキテクチャを発表していたが、GPUアーキテクチャの改良はここで一段落し、GPUを相互接続し高い処理性能を引き出す接続チップで最高性能を更新した。

NVSwitchは、Tesla V100が持つ6つのNVLinkを相互接続し最大16個のV100を接続できる。
前述のように、NVIDIAはAI分野を本業のグラフィックスに並ぶ重要分野としたが、Keplerアーテキクチャはそれ以前に設計されたため、機械学習の「学習」処理で高い性能を発揮できなかった。そこで投入されたのがPascal(2016年)、Volta(2017年)とったアーキテクチャだ。
学習処理では高い精度は不要であり、そのためのデータ形式や多数の演算ユニットを組み込み、大量の演算をできように方向転換した。GPUコアの改良としてはVoltaで一段落し、さらに高い性能を引き出すために、多数のGPUを相互接続する方向を打ち出した。いわゆるCPUでいえば、マルチプロセッサを構成しやすくするためのチップを開発したわけだ。このNVSwitchは、Pascal世代で実装されたNVLinkを使ってGPU同士を接続する。
Tesla V100には、6本の双方向NVLinkが実装されているが、これでは、最大で8つのV100しか接続することができない。しかも、実際には本数が足らず、GPU間の接続は、2リンクにできるところと1リンクだけの部分があった。このため、他のV100GPUの演算結果を利用する場合、高速に転送できる2リンクで接続されているGPU同士と1リンクしかないGPUという組み合わせが生じた。これにより、演算結果を受け取るのが少し遅れてしまうことがあり、結果的に処理速度に影響していたわけだ。

NVSwitchにより、GPU間は、最大300GB/secでの接続が可能になる
NVSwitchは、この6つのNVLinkと接続し、最大16個のV100 GPUを相互に接続する「スイッチ」デバイスだ。「スイッチ」とは、電話の交換機のように、任意の2点を同時に接続できる。つまり、他のGPUへのアクセスは常に一定で、最大速度でできるため、GPUの組み合わせによる速度の低下は起こらない。
もう1つは、Tesla V100 GPUのパッケージ上に搭載されたHBM(High Bandwidth Memory)を16GBから32GBに増強した。この32GB版V100を利用することで、従来よりも多くのデータをGPUパッケージ内に格納できる。ただし、GPUコア部分(GV100)は、同じままだ。
最大2ペタFLOPSの半精度の演算性能を持つ「DGX-2」
この2つを利用して作られたのが、DGX-2である。DGX-2は、Pascal世代で発表されたAIワークステーション、DGX-1の強化版で、ディープラーニングの学習性能では、同じV100を使うDGX-1の10倍の性能があるという。32GB版Tesla V100を16個搭載するため、トータルのGPUメモリは512GB、半精度浮動小数点演算では最大2ペタFlopsに達するという。
DGX-2の「学習」性能がDGX-1よりも高いのは、主にメモリの増強と、NVSwitchが関係する。まず、Tesla V100はGPUであり、計算に利用するデータは、CPU側からPCI Expressを経由して入手する必要がある。逆に言えばCPU側が必要に応じてV100のHMBへデータを転送するわけだ。このとき、HMBの容量が2倍になっているため、この転送は同じ処理であれば、半分で済む。

DGX-2は、2枚のGPUボードをNVSwitchで接続、16個のTesla V100を搭載する。CPUにはXeon Platinum、30TBのSSDを搭載

DGX-2は、2枚のGPUボードとCPUボードなどから構成されている
機械学習では、大量のデータ(たとえば画像など)を学習データとして利用し、これらは、すべてCPU側に接続されたSSDなどに格納されている。このため、データの量、数が多いほど、PCI Express経由での転送が増えてしまう。メモリの増強は、その頻度を押さえる効果がある。
もう1つは、V100同士の接続がNVSwitch経由となり、制限のない高速なデータ伝送が可能になった点。一般に行列計算では、ある計算の結果を利用して次の計算をする。このとき、別のGPUにその結果があるなら、これを読み出してこなければならない。
前世代のDGX-1では、このときにNVLinkが1本、2本と違いがあり、1本の場合には、転送速度が半分になってしまう。GPUへの計算の割当方法などを工夫して効率的にすることもできるが、大量の演算をする場合には、どうしても制限のある組み合わせを使わざるを得ない場合が出てくる。これに対して、NVSwitchを使った場合、データ転送速度は常に一定となる。このため、次の演算を最短でできるようになるわけだ。さらに、GPUが8個から16個に増えているという単純な理由もある。
DGX-2のGPUボードは2枚に分かれており、それぞれに8つのTesla V100と6つのNVSwitchチップが搭載されている。NVSwitchチップは、それぞれ1つの双方向NVLinkを転送するようになっていて、個々のV100は、6つのNVSwitchチップに接続されている。2つのGPUボードは、NVSwitchで接続されていて、このために専用接続ボードがある。こうした構成のため、DGX-2は、DGX-1を2つ重ねたような形状になっている。

正面部分はDGX-1と同じく発泡質の金属で作られている。GPUボードが2枚になったため、DGX-1よりも高さが増えている

NVSwitchチップ。このチップに、6つのV100からのNVLinkが接続、バックプレーンを介してもう1枚のGPUボードと接続している

DGX-2のGPUボード。緑のヒートシンクの下に8つのV100があり、写真右側の銅のヒートシンクの下にNVSwitchチップが6つある
2枚で64GBのメモリが利用できる「Quadro GV100」
NVIDIAは、同じく32GBのV100GPUを搭載するグラフィックスボードQuadro GV100も発表した。本業のグラフィックスも忘れてはいないというところだが、こちらもNVLinkを使い、2枚のQuadro GV100を接続し、高速化が可能だ。

巨大なグラフィックスレンダリングシステムもQuadro GV100を使えばコストを1/5に、スペースを1/7に減らせるという
直前のGDC(Game Developers Conference)で発表されたリアルタイムレンダリング技術であるRTXに対応していて、高速なリアルタイムレンダリングが可能になる。
その他、自動運転向けのDRIVEシリーズの次世代製品としてDRIVE Pegasusを発表、自動走行車向けのシミュレータなども公開している。また、ロボティクス関係では、昨年発表した「仮想ロボットシミュレータ」であるISSACで開発したソフトウェアを実際のハードウェアに搭載するためのISSAC SDKなども発表した。

自動運転用プロセッサのDRIVEシリーズは、次世代としてPegasusを開発中で、さらにその次には、Orinを予定する

自動運転車用シミュレーターNVIDIA Drive SIM。DRIVEシリーズ用に構築したソフトウェアを仮想環境で動作させて検証できる。仮想環境であるため、さまざまな状態を作り出すことができる

2つのDGX-1を使い、片方でDrive SIMを動作させ、もう一方でDRIVE Pegasusのエミュレーションをする。このシステムをNVIDIAはConstellationと呼ぶ
AIやロボットについては、ある程度見えてきた感じなのか、今回は、AIやグラフィックスの応用分野として「Health Care」に対する取り組みも基調講演で触れられた。DGX-1ベースの医療向け画像スーパーコンピューター、CLARAも発表している。基調講演では、超音波エコー検査のデータから、実際に動いている胎児の心臓の動きを3D映像として生成して見せた。
DGX-1ベースの医療向け画像スーパーコンピュータCLARA。画像処理だけでなく、AI処理にも利用できる

DGX-2は、150万ドルのところ、「友達価格」で39万9000ドルになるというジョーク
直前のUberの自動運転試験中の事故から、自動運転に関しては、慎重な姿勢を見せたNVIDIAだが、AIや自動運転分野で一定の存在感を示したあと、他の市場へも同社のGPUを広げる方向に入ったようだ。

基調講演では、VRシステムであるHoloDeck内で仮想的な自動車の運転をデモ。仮想環境に表示される画像は、会場の外に置かれた自動運転車からのもの。VR環境を使って人間が車を操縦するとその通りに実車が動いた
本記事はアフィリエイトプログラムによる収益を得ている場合があります




























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























