




今週からしばらくは中休みということで、用語集をお届けする。「なぜ用語集?」というと、ジサトラメンバーから「用語は知ってるけれど、ちゃんと理解してない」言葉がいくつかある、という話が出てきていたので「それじゃ中休みがてら説明しましょう」ということである。そんなわけで単語の選定は、主にジサトラメンバーからあがってきたものである。その一発目はRing Busである。
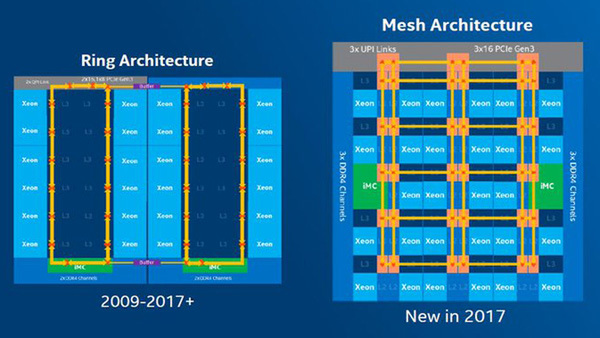
Ring Busってなに? どういう仕組み?
そもそもバスって何よ? という話は以前連載105回や218回で簡単に触れたが、要するにPCの内部のコンポーネント同士をつなぐのがバスである。
CPUとメモリーをつながないと、CPUが処理をするためのデータが永遠に手に入らない。メモリーとGPUをつながないと、いくら待っても画面は真っ暗なままである。そんなわけで、バスもまたPCの内部では非常に重要(ただし陽があたらない、影の存在)である。
さて、以前の連載では規格別にバスを紹介したが、少し別の観点からバスを分類してみる。トポロジー(つまりつなぎ方)で言うと、バスには以下の3種類がある。
(1) 共有バス
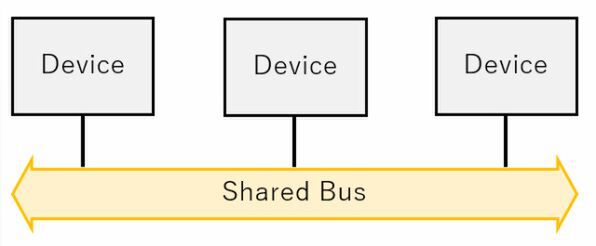
共有バス
複数のデバイスが1本のバスを共有する形だ。この方式は以下の特徴がある。
| 共有バスの仕組み | ||||||
|---|---|---|---|---|---|---|
| メリット | 構造がシンプルで、デバイスの数を簡単に増やしやすい。 1つのデバイスからほかのデバイスに一斉にデータを送れる(Broadcast)。 バスのデータ幅を増やしても、実装面積が最小に抑えられる。 |
|||||
| デメリット | あるDeviceの送信中は、ほかのデバイスが送信できない。 信号が高速になると、波形が乱れやすい(特にデバイス数が増えると顕著)。 デバイス間の調停機構(誰がいつまでの間送信できるか、を決める)が必要。 |
|||||
この共有バスは、かつてはインテルのFSB(Front Side Bus)で利用されており、ほかにもISA/PCIやLPC、Enhanced IDEなど非常に幅広く使われていた。現在もメインメモリーや、周辺回路でもI2Cなどは引き続き共有バス形式である。また広義に言えば、Wi-FiやBluetoothなど無線を利用したネットワークは、分類としては共有バスということになる。
(2) Point-to-Point
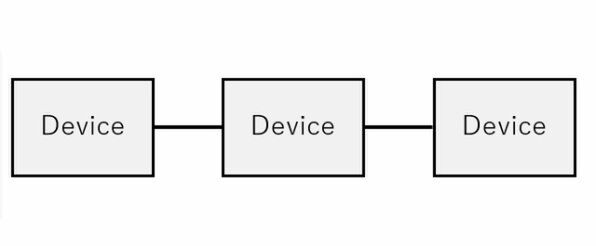
Point-to-Point
個々のデバイスが一対一接続する形だ。この方式の場合以下の特徴がある。
| Point-to-Pointの仕組み | ||||||
|---|---|---|---|---|---|---|
| メリット | 速度やバスのデータ幅を自由に選べるし、特に速度を非常に上げやすい。 小規模な構成であれば、最小の面積で実装できる。 |
|||||
| デメリット | デバイスの個数が増えると、途端に配線の数が爆発的に増えることになる。 ある程度以上の構成ではハブをはさむ形にすることが多いが、大規模になるとハブを複数個つなげることになり、これのレイテンシーや消費電力がバカにならない。 大規模なハブは、内部が複雑化する。 |
|||||
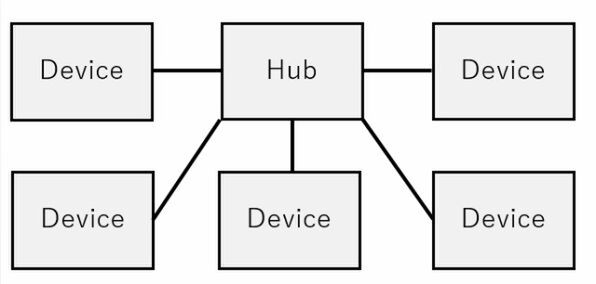
ある程度以上の構成ではハブをはさむことになる
Point-to-Pointが現在の主流であって、Nehalem以降のCPUの接続やPCI Express、Serial ATA、GDDR、USB、Thunderbolt、HDMI、DisplayPortなどさまざまなI/Fがこの構造を取っている。ネットワークでも、10BASE-T以降のすべてのイーサネットはこの方式である。
ちなみにこのハブの内部構造はこれも2種類あり、大別すると共有バス方式のものと、Switch(Fabricという言い方をする場合もある)方式である。下図が共有バス方式のもので、昔のUSB 1.1/2.0のハブなどはこうした実装であった。
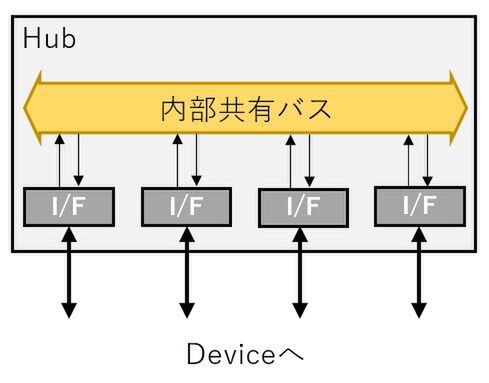
ハブの内部構造(共有バス方式)
この方式ではコストが安く済む一方、共有バス方式のデメリットを全部引き継ぐことになってしまうため、最近はあまり使われていない。
一方のSwitchは、最小構成では下の構図になっている。それぞれのデバイス用のI/Fから、縦横構造の配線に信号が渡されて、目的のデバイスにつながる形だ。
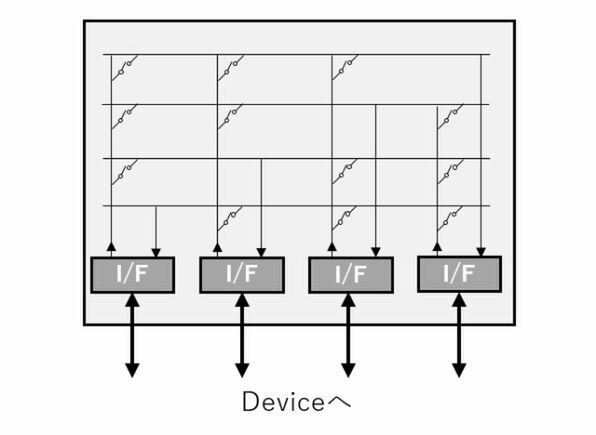
ハブの内部構造(Switch方式)
この方式、昔は電話交換機に使われており、縦方向の信号線に横方向のショートカット(横木)を当てる形なのでCrossbar、と呼ばれていた。最近では縦横の配線がまるで織物のようだ、ということでFabricと呼ばれることもあるが、Switch/Crossbar/Fabricのいずれも同じものを指している。
このSwitchは、たとえばDevice AとBが通信しながら、同時にDevice CとDが通信することもできるといったメリットがあり、レイテンシーも共有バス方式よりもずっと少ない反面、つながるデバイス(この図で言えば縦方向の配線)の数の2乗のサイズで回路規模が大きくなる、という欠点がある。
したがって大規模なSwitchは高コストになるという欠点もある。そこで複数個のスイッチをツリー状につなげる、という使われ方をする場合もある。スーパーコンピューターのASCI QがElite(これがSwitch)を3層のFat Treeにしたというのも、1個で3000台をブラ下げられるSwitchを作ることが技術的に不可能だからこその対策である。

ASCI Qは、図の四角で示したEliteがFat-treeの構造を形成する。出典はロスアラモス国立研究所が2003年のHot Interconnectsで発表した“Scalable Collective Communication on the ASCI Q Machine”
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 -
第872回
PC
NVIDIAのRubin UltraとKyber Rackの深層 プロトタイプから露見した設計刷新とNVLinkの物理的限界 - この連載の一覧へ











































ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












