




第1世代7nmの生産コストは14nmの40%増
第2世代7nmでようやく14nmと同じ生産コストに
さて、この14LPP+と14LPP++で時間を稼いでいる間に7nmをということだが、Globalfoundriesによれば30%の性能改善と、60%以上の省電力化、そして50%ものダイエリア削減が可能になるとしている。
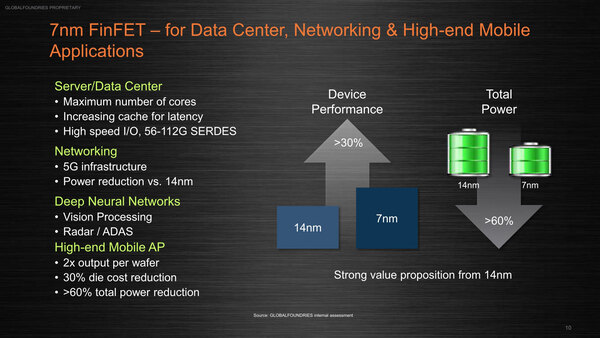
もうプロセスルールは実際の寸法を示していないので、数字でそのままサイズを判断することはできない。が、それでも14nm→7nmでエリアサイズはおおむね半分になるとしているようだ
用途は上の画像に示されるような、高性能プロセッサーなどであり、これは分かる。おもしろいのが、“2x output per wafer”なのでダイエリアそのものは半分になるにもかかわらず、ダイコストは30%の削減にしかならないこと。
これは7nm世代のウェハー生産コストが、14nm世代の40%増になることを意味している。理由は簡単で露光である。TSMCと同じく、7nm世代ではQuad Patterning(4回露光)が必要になるからで、このコストを下げるためには露光装置にEUV(Extreme UltraViolet lithography:極端紫外線リソグラフィー)が必要になるのは間違いなく、こちらの導入と据付、運用状態に持ち込んでからの調整などには相応の時間がかかる。
連載415回でも書いたが、露光装置そのものは今年中に納入されても、実際に運用段階まで持ち込めるのは早くて2019年になる。
このEUVを露光に使うのが、7nm FinFETの第2世代である。AMDのロードマップで言えば、Zen 3世代に使われる7nm+がこれだ。
ではその手前、2018年中に量産に入る予定の7nmは? というと、これはArF+液浸しかない。7nm世代でウェハー生産コストが4割も跳ね上がるのは、おそらくはこのためである。
ある程度まではダイサイズの縮小で相殺できるとは言え、基本的にはプロセスが微細化するごとに新機能やコアの増強を図ることでダイサイズを一定にしてきたPC業界向けとしてはやや厳しい。

7nm FinFET第1世代に関してはコストを抑えようとすると、理論上はダイサイズを14nm世代の70%程度に抑えないといけないことになる。密度は倍なので、利用できるトランジスタ数は1.4倍程度。つまり8コアのCPUを10コアにするのは可能だが、12コアは厳しいというあたり。
CPUは10コアでもおつりがくるが、コアの数が性能に直結するGPU向けは致命的である。このあたり、14nm世代と同じウェハーコストになるのはEUVが本格稼動する2019年以降で、そこまでは我慢の日々が続く、ということだろうか。
慰めにもならないが、これはGlobalfoundriesだけでなく、TSMCも当然同じである。その意味では、2018年は「相次いで7nm世代の製品が投入されるものの、あんまり性能が上がった気がしない」年になるかもしれない。
ちなみに5nm以降については、そもそも構造が確立していない。そろそろトランジスタよりも配線層がボトルネックになってくる世代だが、これに対する対処方法の決定打がないうえ、さらに投資額がかさむことが予想されている。
先のDigitimesのインタビューでもJha氏は、Globalfoundriesも5nm向けの研究開発は開始したが、5nmを必要とするアプリケーションも見えず、またトランジスタや配線の構造なども明確でないとしている。
Jha氏の個人的な見解では、少なくとも2020年まで5nm世代が来ることはないだろう、というものだった。
ところでTSMCでは16FF+→10FF→7FFというハイエンド向けとは別に、16FFC→12FFC→7FFCというメインストリーム/ローパワー向けプロセスが用意されていることを前回説明したが、GlobalfoundriesでこれにあたるのがFD-SOIである。
もともとGlobalfoundriesはAMDが導入したPD-SOIを受け継いでおり、その後IBM Microelectoronicsの買収によりFD-SOIの技術も入手した。さらにSTMicroelectronicsの開発した28nmのFD-SOIのライセンスも受けているが、2015年にGlobalfoundriesが発表したのが22FDXという22nm FD-SOIのプラットフォームである。

2015年の発表時には22FD-UHP(Ultra High Performance)もあったはずなのだが、いつのまにか消えてしまった
22nm FD-SOIのプラットフォームは以下の3種類がある。
| 各ビデオカードの比較表 | ||||||
|---|---|---|---|---|---|---|
| 22FDX-ULP | Body Biasを利用することで、最低0.4V駆動での動作が可能となっており、28nm HKMGプロセスと比較して平均50%、最大で70%もの消費電力削減が可能となる。 | |||||
| 22FDX-ULL | 22FD-ULPプロセスにマスクを1枚追加した、リーク電流の削減に特化したIoT/ウェラブル機器向けプロセス。リーク電流を1~10pA/μmのレベルに抑えられるとしており、40nmプロセスと比較して80%以上の消費電力削減が可能。 | |||||
| 22FDX-RFA | LTE-AやMIMO Wi-FiなどのRF段に利用可能で、従来と比較して最大50%の消費電力削減が可能となっている。 | |||||
実はこの22FDX、どこまで利用されるか当初は怪しんでいたのだが、実際には順調に顧客もつき、量産も順調のようで、すでに製品の出荷も始まっている。FD-SOIの場合ウェハーそのもののコストが高くつく反面、ウェハー以外の量産コストはFinFETに比べるとずっと安いということで、トータルコストでは遜色ないところまで落ちてきている。
ピーク性能はFinFETにおよばないが、省電力とかアナログ/RFには絶縁層の存在がうまく作用しており、次第に普及しつつある。これに手ごたえを感じたのか、2016年9月にはこの後継として12FDXを発表している。こちらはまだ詳細は明らかでないが、2019年ごろの量産開始を計画しているようだ。

12FDXでは、ついに動作電圧が0.4Vをきるところまで到達した
この22FDX/12FDXが、PC向けのCPUやGPUに使われることはないと思うが、バリュー向けのスマートフォン向けや、組み込み機器(たとえばCMOSカメラに内蔵されるコントローラー)などに広く使われていくと見られており、気がついてないだけで実は22FDXを使ったチップを使っていた、なんてことになっていくかもしれない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















