
前回に引き続き、今回もRyzenの内部構造について解説しよう。
省電力化に大きく貢献した
複数のライブラリー
下の画像はなにかというと、コア内部で使われているスタンダードセルライブラリー5種類の特性比較と、利用率である。
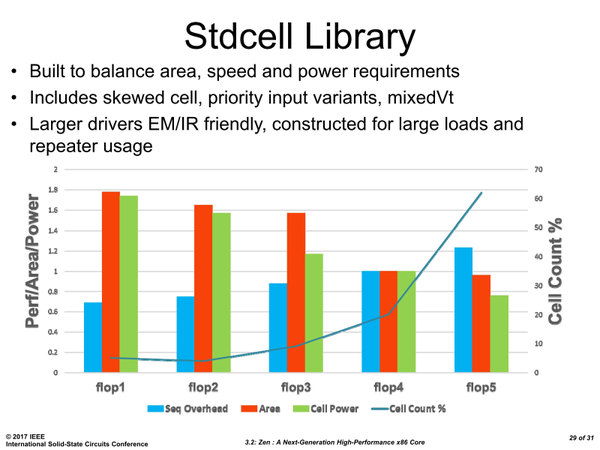
スタンダードセルライブラリー5種類の特性比較と、利用率。このグラフはflop4が基準になっている。おそらくこれがGlobalFoundriesの提供する、「一番バランスの取れた基準となる」ライブラリーなのだろう
スタンダードセルとは、連載229回で説明したが、要するに回路を構成するための基本的な構成部品のことで、これをまとめたのがスタンダードセルライブラリーというわけだ。
そのライブラリーだが、PPA(Power, Performance and Area)という3大パラメーターをどうバランスを取るかでいくつかの選択肢があるため、複数のライブラリーが用意されている。
上の画像でいえば、flop1~flop5がこれにあたる。Seq Overheadは処理のレイテンシーで、これが低いほど高速である。Areaはそのセルが占める面積、Cell Powerは消費電力となる。
これで言えば、flop1だけを使ってZenを構築すると、速度は一番上がる(他のライブラリーに比べてオーバーヘッドが30%少ないため、ラフに言えば40%ほど動作周波数が上がる計算になる)一方、消費電力は1.75倍ほど、エリアサイズは1.8倍ほどになる。
つまりそれだけ大きなダイとなり、さらに消費電力も増えるわけだ。逆にflop5だけを使うと、オーバーヘッドは20%強増えるので動作周波数は18%ほど落ちる計算になるが、エリアサイズは5%ほど削減でき、かつ消費電力は20%強削減できることになる。
ということで、これをどう組み合わせて、所定の性能や消費電力を実現しつつ、いかにサイズを小さくできるかというチャレンジになるわけだ。
Zenの場合は、上の画像の折れ線が示すように、一番遅い(ただし高密度で省電力な)flop5の利用率が60以上%と一番高く、次いで標準的なflop4が20%程度で、全体の8割以上がこうした省電力向けのライブラリーで構成されている。
次いで消費電力こそ1.6倍近いが、10%程度オーバーヘッドが少なく、エリアサイズも2割増で収まるflop3が10%程度。本当に高速だがエリアサイズ/消費電力ともに急増するflop1/flop2は合わせて10%弱でしかない。
クリティカルパスと呼ばれる、CPU全体の動作周波数に大きな影響をおよぼす部分にのみこうした高速なライブラリーを使い、あとはなるべく省電力なライブラリーを使うという工夫が、全体としてZenの省電力化に大きく貢献したものと思われる。
性能/消費電力比は
3つの設計ポイントで最適化された
ちなみに省電力化に関してはおもしろい話があった。下の画像は、性能/消費電力比の最適化に関する議論であるが、Zenの設計チームは3つの設計ポイントにあわせての最適化を行なったとする。
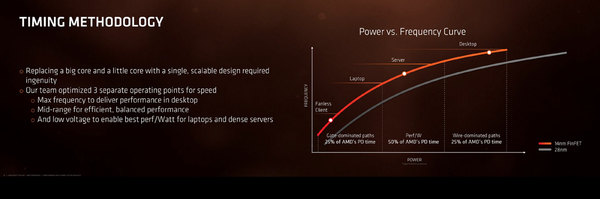
性能/消費電力比の最適化に関する議論。同じ図はISSCC 2017でも示されたが、こちらの方が説明がていねいに書かれているので、Ryzen発表時のスライドを利用した
おそらく中心になるのがサーバーで、ここは性能/消費電力比を最大にする形での最適化となる。その一方で、ハイエンドのデスクトップなどに関して言えば、ボトルネックは配線のレイテンシーになるとしており、これを最適化する方向で設計が行なわれた。
一方ローエンドの、例えばFanless Clientなど数WのTDPの範囲では、今度はゲート(つまりスタンダードセルそのもの)がボトルネックになりやすいとして、ここの最適化を行なったとする。
これにより、そもそもBulldozer世代でローエンド向けに投入されたBobcatのラインナップまで、単一アーキテクチャーでカバーできるようになった、というのがAMDの主張である。
ちなみに競合するインテルも似たようなもので、単一のCoreアーキテクチャーで4.5Wから140Wまでの幅広い範囲の製品をカバーしており、事実上Atomコアが要らない子になりつつあるのはご存知の通り。ただそれでもインテルがAtomを止めないのは、「安価なx86コア」はまだまだ利用できる範囲が大きいからだ。
前回の繰り返しになるが、ZenとSkylakeのダイサイズを比較してみると以下のようになる。
| ZenとSkylakeのダイサイズ | ||||||
|---|---|---|---|---|---|---|
| ダイ | Zen | Skylake | ||||
| 全体(4 CPUコア+4 L2+L3) | 44mm2 | 49mm2 | ||||
| 3次キャッシュ | 16mm2 | 19.1mm2 | ||||
| 2次キャッシュ | 1.5mm2×4 | 0.9mm2×4 | ||||
| CPUコア単体 | 5.5mm2 | 6.55mm2 | ||||
つまり1コア/2次キャッシュなしのCPUを作ったとしても、ダイサイズは5.5~6.6mm2とけっこう大きいことになる。それも14nmを使ってこれなので、どうしても価格は高くなる。
それにも増してここまで大きいと、たとえばXeon Phiのように72コアものコアを入れ込むような製品には到底使えない。Skylakeコアをそのまま72コア集積すると、それだけで470mm2を超えてしまうからだ。
また組み込み向けにも明らかに大きい。例えばARMのCortex-A72ですらTSMCの16FF+でわずかに1.15mm2でしかない。
もっと下の、Cortex-A53やCortex-A35など組み込み向けに多用されるコアは1mm2を切る(2次キャッシュまで入れても1mm2前後)サイズに留まっており、その意味ではSkylakeコアやZenコアは組み込み向けといっても極めて用途は限られることになる。
まだ広範な組み込み向けの製品展開を狙うインテルとしては、Atomコアは捨てられないものであり、企業再生のために市場を絞り込んでいるAMDは、Bobcatグレードの製品を維持する必要も、そのコストも持ち合わせていなかったということだろうか。
逆にそうした市場にフォーカスしているARMは“One Size Does Not Fit All”を合言葉に、さまざまなサイズと性能のCortex-Aプロセッサーを世の中に送り出しているわけで、このあたりの対比がおもしろい。
他にももう少し細かな話はいくつか上がっていたが、大きなテーマとして現時点でAMDから公開された情報はこのあたりである。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ








