




今週はNVIDIA GPUのロードマップ アップデートをお届けしよう。まずは連載361回以降の製品アップデートから話をする。
2014年~2016年のNVIDIA GPUロードマップ
いきなり前回のロードマップ図の訂正だが、GP104コアにはNVLinkが完全に省かれており、Multi-GPUの手段はSLIブリッジ経由ということが明らかになった。前回は「NVLink数削減?」と表現していたが、NVLinkそのものがない形になった。
もっともNVLinkを使おうとすると、基板上に別のインターコネクトを用意する必要が出るため、現実問題としてはコンシューマー向けとしては妥当な手段だろう。
ちなみにその大元になったGP100を搭載するTesla P100であるが、こちらは複数のバリエーションがあることも明らかになった。
もともとGTCなどで発表されていたのはMezzanineカードタイプのもので、こちらはI/FにNVLinkを持つ(おそらくはNVLinkと一緒にPCI Expressの信号も通っていると思われる)タイプであるが、これに続きPCI ExpressカードタイプのP100も発表された。

最初に発表されたTesla P100。背面写真にコネクター部が見えている

PCI ExpressカードタイプのTesla。シャーシに格納することを前提に、冷却ファンは持たない構成
データシートによればMezzanineカードタイプのものもPCI Expressカードのものも、シェーダー数(CUDAコア数)は3584であり、単精度での演算速度がMezzanineカードが10.6TFlops、PCI Expressカードのものが9.3TFlopsとされる。
ここから逆算すると、Messanineカードタイプが1480MHz程度、PCI Expressカードタイプが1300MHz程度の動作周波数と考えられる。
またPCI Expressカードタイプには16GBのものと12GBのものがあるが、16GBのものが720GB/秒のメモリー帯域なのに対し、12GBのものは540GB/秒に帯域が減らされており、これは素直にHBM2のスタックが3つのみに減らされたと考えられる。
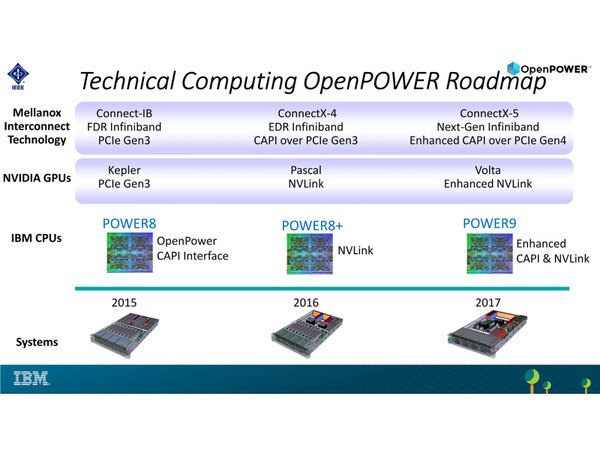
さて、Messanineカードタイプは、オークリッジ国立研究所のSummitと、ローレンス・リバモア国立研究所のSierra向けが最初のターゲットである。
ここは最終的にはPower9+Voltaという構成になるという話は連載340回でも書いたが、その前段階としてPower8とKeplerのシステムがまず導入される。
それに続き今年度にはCAPI I/FがNVLink対応となったPower8+とP100のシステムが導入、2017年度にはいよいよPower9と、予定が順調ならVoltaベースのTeslaが納入される。
現状ではVoltaもPower9も存在しないので、この通りに行くかは不明
画像の出典は、“Performance Beyond Moore's Law:OpenPOWER”
ただこれはIBMのPowerベースのサーバーと組み合わせるのは問題ないが、従来タイプのサーバーではNVLinkのI/Fを電気的にも物理的にも持っていないため、PCI Expressカードタイプも当然必要になる。
もちろん多数のTesla P100を利用する構成では、例えば下の画像のような形での接続も可能で、必ずしもMessanineカードタイプでは、インテルのCPUと組み合わせできないわけではないが、もう少し小規模なシステムを望む場合にはやはりPCI Expressカードの方が好ましいだろう。
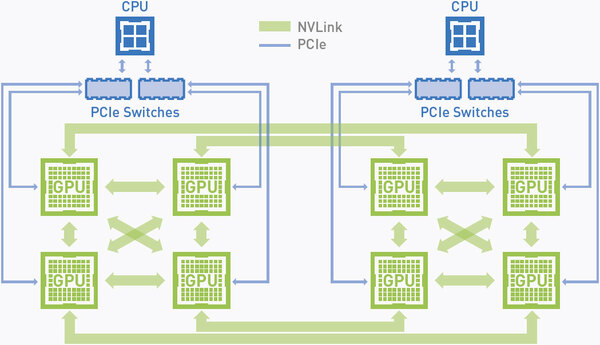
これはNVIDIAの発売するDGX-1の構成そのものと思われる
画像の出典は、“NVIDIA TESLA P100:INFINITE COMPUTE POWER FOR THE MODERN DATA CENTER”
ちなみに、PCI Expressカードタイプの動作周波数がやや低くなっているのは、おそらく冷却の都合と思われる。
後述するGeForce Titan XはTeslaと異なり冷却ファンを持つ構成だが、連続稼動させているとしばしばThermal Throttling(温度が高くなりすぎるのを防止するために、動作周波数を自動でやや落とす仕組み)が発生し、ピーク性能が出ないという。
これはPCI Expressカードに収めるためにヒートシンクの体積に縛りがあり、放熱が十分でないことから発生する。このあたり、Messanineカードの方が冷却的には有利(少なくともPCI Expressカードのような「ガワ」がないだけでもだいぶ効率が良い)というあたりに起因すると思われる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























