



かんぽ生命、東大医科研も登壇、「IBM Watson Summit 2016」基調講演(後編)
スバル「アイサイト」の進化も支える、IBM Watson活用事例
2016年06月09日 07時00分更新

東京大学医科学研究所:人知を超えた膨大なデータに基づくがん診断を可能に

東京大学医科学研究所 教授 理学博士 ヒトゲノム解析センター長の宮野悟氏
東京大学医科学研究所(東大医科研)の宮野氏は、医療分野において次世代の創薬や治療法に役立つ「ゲノム解析(遺伝子情報解析)」を研究している。ゲノム解析を通じて、たとえば「この『がん』はどういう種類のものか」「どんな治療法や治療薬が効くのか」といったことも徐々にわかるようになりつつある。
ただし、その作業は膨大なデータ量との戦いである。ゲノム解析でがんの変異遺伝子を見つけるためには、まず、30億個の塩基配列を組み立てなければならない。「シーケンサーという装置で解析するのだが、30億個がつながった形で抽出できるわけではない。ランダムに切断された数千万個の断片から、パズルのようにして(基の配列を)組み立てていく」(宮野氏)。その作業はまるで、シュレッダーにかけられた数十万枚の書類の断片をつなぎ合わせ、元の状態に戻すようなものだと、宮野氏はたとえる。
もっとも、シーケンサーとスパコン技術の進化により、現在ではこの処理までは「全世界のだれでもできるようになっている」(宮野氏)。問題はここから先の、見つかった変異からがん遺伝子を絞り込み、それに有効な治療法や治療薬を提案するという作業だ。これまでは「人知」に頼っていたこの作業だが、ここにもまた、別の膨大なデータ量との戦いが潜んでいる。
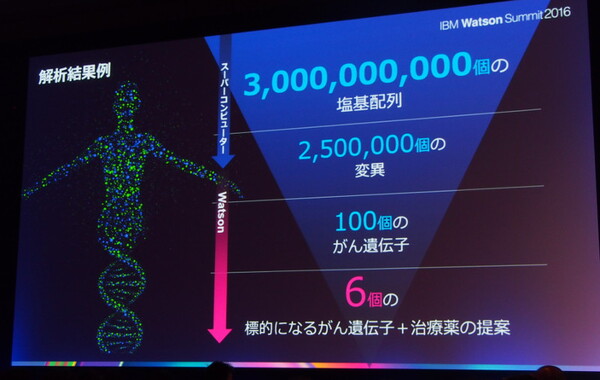
30億個の塩基配列を組み立て、変異を見つける処理まではスパコンにより実施できるが、これまではその先の作業が人間に頼っていた
「生命科学に関する論文数は、2014年までに約2400万件が登録されている。がん関連のものだけに絞り込んだとしても20万件。すべてデジタル化されており、自然言語で『読める』形になってはいるが、1人の研究者がすべてを読むことは到底できない」
医療論文に加えて、化合物式を含む新薬の特許情報データベース、変異遺伝子のデータベースなども参照しなくてはならない。宮野氏は、人知、人力による対応は「無理だ」と述べ、そこでWatsonを採用したと語った。
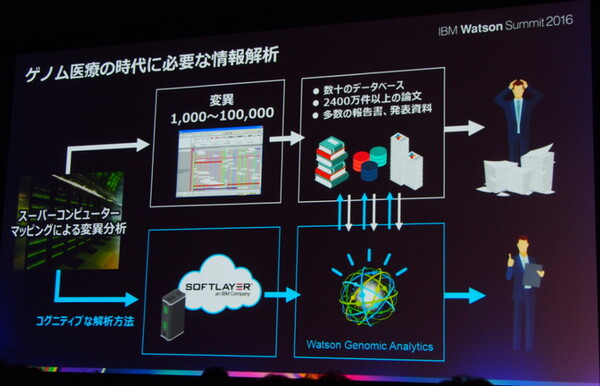
膨大な情報に基づいてがん遺伝子を絞り込み、治療法や治療薬を提案する作業をWatsonが支援する
「東大医科研付属病院では、すでに昨年から血液および消化器のがんにおいて(Watsonの)臨床試験が始まっている。がんは、診断がつくものがまだ半分ほど。研究結果の自然言語(論文)だけでなく画像も学習し、さらに精度の高い医療を作っていくためにも、Watsonは必須の支援ツールになると思っている」(宮野氏)
* * *
セッションの締めくくりとして登壇した日本IBMの池田氏は、スバル、かんぽ生命、東大医科研の各事例から、3つの結論が導けると述べた。
「1つめは、コグニティブは企業、社会を変える汎用的な技術であること。2つめは、Watsonはすでに実用段階にあり、先進的なアーリーアダプター企業にとってはもはや普及段階と言ってもいいレベルに進んでいること。そして最後は、データが重要性を持っており、データ基盤の整備も大切であること」(池田氏)
こうした企業のWatson活用について、IBMでは専門のコグニティブコンサルタントが支援を行っていくと述べて、同セッションは幕を閉じた。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



