




超並列システムを2段のスイッチでつなぐ
画期的なアイデアの「Butterfly-1」
さて、恐ろしいことに実はここまでが前段落であり、いよいよここからが今回の本題である。
Pluribusで並列システムに習熟したほか、1980年にはSUEを生産していたLockheed Computer Corp.も買収したりと勢いがつき、業績も年々改善していった同社は、単にPacket Processingだけでなくもっと広い範囲で利用できるシステムの構築を目論む。
最初に開発を手がけたのは、Voice Funnel向けのシステムだ。Voice Funnelは今で言えばVoIPのご先祖様といったところか。1979年~1981年にかけて行なわれたこのVoice Funnel Systemで、BBNは超並列システムの構成を取った。
構図としてはPluribusに近い「全てのノードが1:1でつながる」方式だが、実際に配線するのは無茶があると思ったのか、2段のスイッチを挟んだ構成となった。
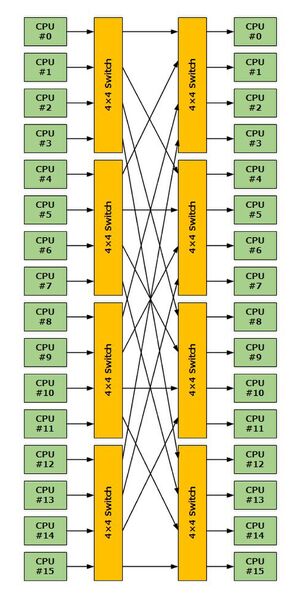
Voice Funnel Systemの構成図
上図がその構図であるが、左右にCPUが分かれているのではなく、右と左のCPUは同じものである。別の形でこれを描いたのが下の画像である。
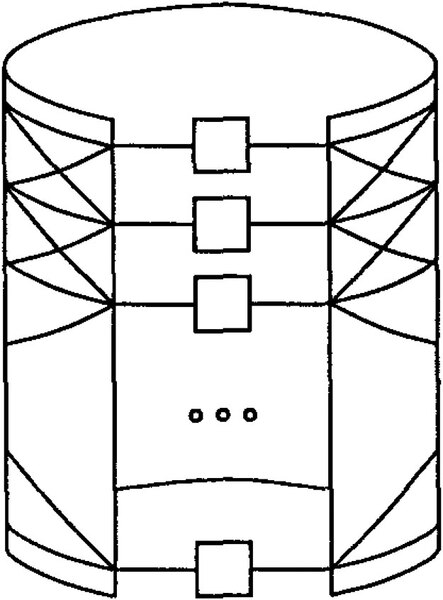
上にある図は、この画像のプロセッサーの部分を半分に切って円筒を広げたもの、と考えてほしい
画像の出典は“Large-Scale Parallel Programming:Experience with the BBN Butterfly Parallel Processor”。
ちなみにこれは16プロセッサーの構成であるが、理論上は最大256プロセッサーまでサポートした。プロセッサーモジュールは8MHzのMC68000と1MBのローカルメモリーが搭載されており、他に同じくMC68000を使ったコミュニケーションモジュールや、AMD 2901を利用したPNC(Processor Node Controller)モジュール、Intel 8089を搭載したI/Oモジュールなどもこの数には含まれる。

プロセッサーモジュールは、1MB分のメモリーソケット(DIPタイプ)が圧巻である。左のソケットがスイッチへのI/F

こちらはコミュニケーションモジュール。右端の電源部のカバーが左の写真と違って外れているのがわかる
画像の出典は“ClassicCmp”。
スイッチは4入力/4出力で転送速度は32Mbit/秒、つまり接続1本あたり8Mbit/秒となる。スイッチ経由での他のノードへのメモリーアクセスは4マイクロ秒で、自ノードのメモリーアクセスの5倍ほど時間がかかった、というより5倍しか時間がかからなかったというべきか。
初号機はThe BBN Parallel Processor System(The BPP)が正式名称らしいのだが、実際にはButterfly-1と呼ばれることも少なくない。
なぜButterflyかというと、前述した図のスイッチの構図が、まるで蝶が羽根を広げたように見えるから、ということだ(*)。
(*) FFT(高速フーリエ変換)に用いられるバタフライ演算と似ているから、という説もある。ただバタフライ演算そのものが、蝶が羽根を広げた格好ににているからという話でこの名前が付いたらしいので、要するに根っこは同じである。
このThe BPPはその後プロセッサーをMC68010に変更したバージョンが少なくとも1つは存在するが、大量には作られなかった。
その代わり、プロセッサーをMC68020+MC68851(MMU)に切り替え、ローカルメモリーを4MBに増量したButterfly GP-1000が登場する。
OSは、The BPPがChrysalisと呼ばれる独自OSだったのに対し、GP-1000ではカーネギーメロン大学が開発していたMach OSを移植したMach 1000が搭載された。
性能不足で販売が振るわず
会社の命運が尽きる
さて、このButterflyであるが、1985年にThe BPPがリリースされてから1994年までの間に少なくとも100システム以上が販売された。
もっとも、ロチェスター大学のコンピュータサイエンス部門が導入したThe BPPはわずか3ノードの構成だったし、最大構成はローレンス・リバモア国立研究所が導入した128ノードのものでしかない。
率直に言えばあまり売れなかった理由は価格性能比の低さである。The BPPの性能あたりの価格は1万2000ドル/MFLOPSにも達した。ちなみにこれは1980年代中旬における、もっとも価格/性能比が高いシステムである。
では一番安いものはというと、MEIKO Computing Surfaceで300ドル/MFLOPSとなっている。理由は簡単で、MC68000/68010はそもそもFPUがなく、続くMC68020ではMC68881/68882が使えるようになったものの、完全にパイプライン化されていたわけではないため性能は低かった。要するに実力不足である。
もちろんパケット処理などの浮動小数点演算がいらない用途にはFPU性能は必要ないし、いくつかの大学では医療用アプリケーションや画像処理、数式演算システムの開発などが行なわれた。
しかし、どちらかというとさまざまなアプリケーションを超並列システムに移植する実験という側面が強く、実用になるといった話はほとんど出てこなかった。変わったところでは、DARPA(国防高等研究計画局)の資金援助の下でLispを移植するという取り組みもされた。
Butterflyの根本的な性能不足はプロセッサーに起因するわけで、次にBBNはやはりDARPAから資金援助を得て、Monarchsというコード名で新製品を開発した。これは最終的にTC-2000として製品化されたが、ここで採用されたのはMC88100であった。
黒歴史入り(記事は書籍版の黒歴史に掲載されています)したMC88000ではなく、問題を解決したというか事実上再設計に近いMC88100を選択したのは正解で、20MHz駆動のMC88100は倍精度演算でピーク10MFLOPSの性能だったから、これはそれなりに競争力があるはずだった。
ローカルメモリーは16MBに増量され、スイッチは8×8のものが用意、最大プロセッサー数は512となっており、理論上は5GFLOPSのマシンが構築できるはずである。BBNはこのTC-2000がAlliant FX/8やConvex C2と競合できると見込んでいた。
あいにく、その前に会社の命運が尽きた。1989年、同社は日本航空のネットワーク構築の契約に絡んで1100万ドルの損失を出す。おまけに1989年に冷戦が終わった結果、米軍向けの契約が急激になくなった。
損失をカバーする目的で、BBNのルーツであった音響関係のビジネスをAcentechとして分離するものの、その後も凋落の一途を辿り、1997年にアメリカの地域電話会社であったGTE(現Verizon)に買収される。その後は次々に買い手が変わり、最終的に2009年にRaytheonに買収されて現在に至る。
ただGTEに買収されるはるか前に、同社はコンピューターシステムの販売から撤退しており、超並列システムを2段のスイッチでつなぐという方式がその後様々な超並列システムに影響を与えたことが、今となっては唯一の功績かもしれない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 -
第872回
PC
NVIDIAのRubin UltraとKyber Rackの深層 プロトタイプから露見した設計刷新とNVLinkの物理的限界 - この連載の一覧へ











































ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












