




プロセッサーの動作を制御する
Central Control
このような構造から、GF11はプロセッサーあたり20MFLOPSの演算性能になる。これを512プロセッサー動作させれば10240MFLOPS、スペアも全部使って576プロセッサー動作にすると11520MFLOPSという演算性能になるわけだ。
ただWTL1032/1033は本当に、レジスターに値を入れて何サイクルか待つと結果がレジスターに出てくる「だけ」のものなので、細かい実行制御や、そもそもどのデータに対して演算を行なうか、といったことは外部で制御する必要がある。
これを行なうのがCentral Controlのブロックである。ちなみに個々のプロセッサーにはSRAMおよびDRAMも搭載されており、SRAMは短期記憶、DRAMは長期記憶という使い分けになっていた模様だ。
WTL1032/1033以外の回路はFairchildのFAST TTL Logic ICで構成され、レジスターファイルはFairchildの100K ECLが利用された。レジスターファイルのアクセス時間は12.5ナノ秒(80MHz)となっている。
ちなみにCentral Controlからは200bit(当初は180bitと記述されていたが、拡張されたらしい)のマイクロコードの形で各プロセッサーの動作制御が行なわれた。
マイクロコードは、576個のプロセッサーすべてにブロードキャストする形になっており、その意味ではMPP(超並列システム)ではあってもMIMDではない。すべてのプロセッサーが同じマイクロコードを受け取って、同じ処理を行なうからである。Central Controlは当初はIBM PC/ATで実装していたようだ。
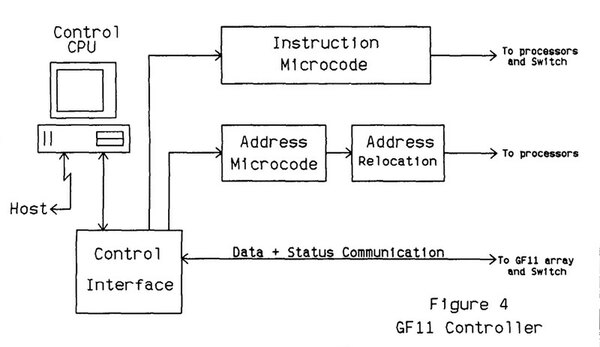
コントローラーの概要。すべてのプロセッサーが同じマイクロコードを受け取って、同じ処理を行なう仕組みだ
演算の高速化のために搭載された
Memphis Switch
プロセッサーとつながる“Memphis Switch”の内部構造が下の画像である。それぞれのスイッチは24入力、24出力(入出力幅は9bit)になっており、これを24個並べると576ポートになる計算だ。
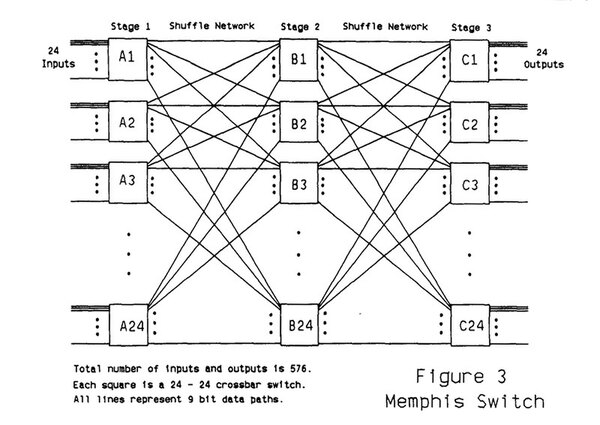
“Memphis Switch”の内部構造。スイッチの名前が“Memphis Switch”なのであって、Memphis Switchという一般名称のスイッチがあるわけではない。なぜこの名前なのかも不明
ただこのままではストレージを接続できない。これもあってか、当初は512+64プロセッサーという構成を予定していたが、後にはプロセッサーの数を512+54の566に減らし、代わりにストレージを10個接続している。
各スイッチはLSI LogicのセミカスタムCMOSで製造されたチップを利用しており、1つのスイッチには18個のチップが利用された。つまり3段のMemphis Switch全体では、1296個のチップが使われていた計算になる。
Memphis Switchの目的は、演算の高速化である。例えば行列演算などでは、転置(行方向と列方向を入れ替える)がしばしば要求される。メモリー中のデータに対して転置をかけるとオーバーヘッドが大きいが、GF11の場合はMemphis Switchで転置を実行できるので、計算が容易になる。
ちなみに3段もの構成ではあるが、大抵のアプリケーションでは1段ないし2段で必要な並べ替えができると考えていたようだ。並び替えだが、Memphis Switchそのものは1024種類の構成をプリロードしておくことが可能で、200ナノ秒で構成を切り替えられるとされていた。
システム全体で言えば、およそ40万個のチップで構成された。576個のプロセッサーは20本の19インチラックに収められ(これには空調と電源も含まれる)、これとは別にMemphis Switch用に19インチラックが5本利用された(ただしうち2本は純粋に配線が通っているだけ)。Central Controllerはラック2つで、システム全体ではおよそ200KWの消費電力となっている。
余談になるが、プロセッサーボードは合計で660枚オーダーされ、うち440枚がデバッグをしてインストール、40枚が予備に回され、55枚が破棄されたとか。なかなか大変な話である。
話を戻すと、性能/消費電力比は57.6KFlops/Wで、これはQCDOCの51.7KFlops/Wよりも優れている計算になるが、QCDOCは倍精度の浮動小数点演算での数字なのに対し、GF11は単精度浮動小数点演算なので、同列に比較はできない。
とはいえ、10GFLOPSクラスのマシンが1985年の時点で稼動を始めることになり、ここから物理学者の出番となった。
1989年に、D. Weingarten博士と共同で作業していた物理学者のJ.C.Sexton博士が発表した“The Status of GF11”という論文によれば、比較的早期からGF11の性能を引き出せたとある。
GF11用のCコンパイラを利用してQuenched QCDを計算した際には、ピーク性能の80%を利用でき、ガウス=ザイデル法を利用した反復計算ではピーク性能の90~95%を利用できたとしている。
とはいえ、まったく独自のアーキテクチャーで構築された、しかも世界で唯一の計算機だけに、ソフトウェアは全部自分たちで記述する必要があり、これには相応の時間がかかる。
GF11は基本単精度演算のみだが、解くべき問題のサイズを大きくしていくと、一部で倍精度が必要になったり、WTL1032/1033には搭載されていない平方根や逆数平方根、指数/対数/三角関数/乱数などの特殊演算など、いろいろソフトウェア面での対応が必要になった。
さらにはQCDの演算の中には3×3の行列演算が含まれるので、この対応(GF11は基本偶数回の演算を前提にしている)も必要だった。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































