




ベクトル演算部を変えた
第2世代のFX/40とFX/80
FXシリーズは単に浮動小数点演算だけではなく、整数演算もそれなりに高速だった。性能比較チャートではDECのVAX 8800と浮動小数点演算性能を比較しているが、このVAX 8800の整数演算性能が大体12MIPSとされた。
一方Alliant FXシリーズは、CE1個で2.5MIPSなのでFX/4で10MIPP、FX/8なら20MIPS相当なので、この点でもVAX 8800を凌駕していることになる。
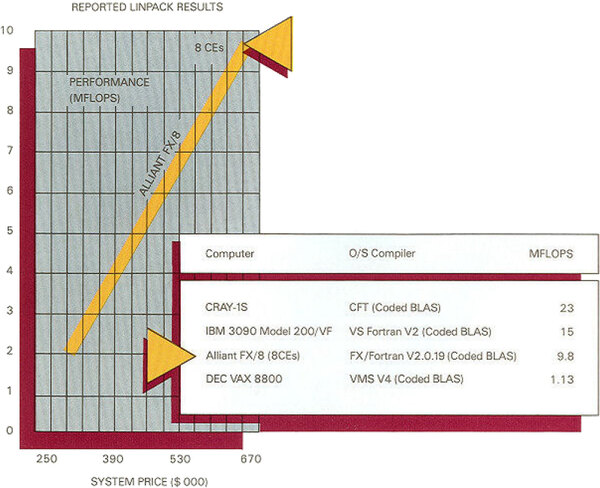
冒頭にも掲載した性能比較チャート
また開発環境などもいろいろ提供することでアプリケーションの移植を容易にした。といってもConvexが提供したVAX/VMSの互換環境にあたるものまでは提供しなかったようだが。
その代わりといってはなんだが、まず1988年には第2世代のFXとしてFX/40とFX/80を投入する(FX/10はなかったらしい)。
違いはベクトル演算部で、WeitekのFPUに代えてBipolar Integrated TechnologyのBT2110/2120を採用した。連載331回でも話が出てきたものだ。
ほかにも、例えばIPは68012から68020(後に68030版も追加されたらしい)となり、またIP間の接続はマルチバスからVMEになった(マルチバスのオプションも残された)。またCPキャッシュの帯域は188MB/秒から376MB/秒に倍増するなど、性能の引き上げが目立つ。
プログラミングの観点では、ベクトルFPUが交換になった関係でベクトルレジスターの構成が変更されている。正確な資料がないのだが、CEはベクトル以外にもあちこち変更があったようである。同社はこの新しいCEをACE(Advanced CE)と称している。
CE1個あたりの性能は以下のとおりで、これを8つ搭載したFX/80シリーズでは理論性能188.8MFLOPS、LINPACKでのスコアは69.3MFLOPSとなっている。
| CE1個あたりの性能 | |
|---|---|
| 32bitスカラー演算 | 7.2MIPS |
| 64bitスカラー演算 | 6.2MIPS |
| ベクトル演算 | 23.5MFLOPS |
性能的には結構な底上げになった第2世代のFXシリーズだが、この時期はConvexのC2やnCUBE 2など、新たな競合製品が登場した時期でもあり、底上げした製品でも十分とは言えないものだった。
また同社が長年仮想敵と目していたDECも、1989年にはアーキテクチャーをまったく変えたAlphaチップの最初のリリースであるDEC 21064を発売しており、こちらに早急に対応する必要があった。
競合他社より有利だったSMP+ベクトルだが
性能の伸び代が少ないため時代とともに失速
Alliantが目をつけたのはインテルのi860である。
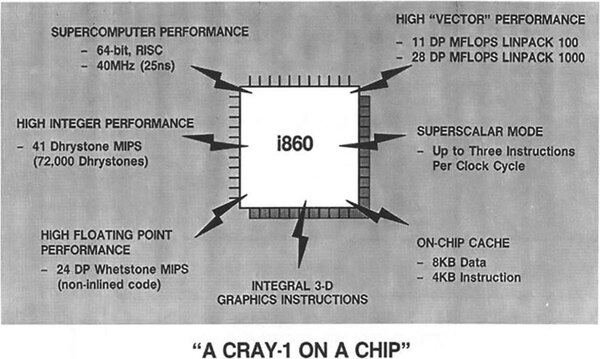
目をつけたのはインテルのi860。確かにカタログデータ的には素敵である。ここからの資料はHerbert Reska氏(Alliant Computer Systems GmbH)の“Highlights of Alliant's Parallel Supercomputer Generation FX/2800 Series”という論文だ
i860はインテルのiPSCやParagonのほか、GENESIS Version 1にも採用予定だったが、スペックだけ見る限りは確かに素晴らしい。
Alliantは従来のCE/ACEとIPの両方を、このi860ベースで作り直したものをFX/2800として1990年に発表した。
下の画像がFX/2800のシステムアーキテクチャーであるが、CEはSCE(SuperCE)、IPはSIP(SuperIP)となって、しかもSCEとSIPが一体化する形での実装になった。
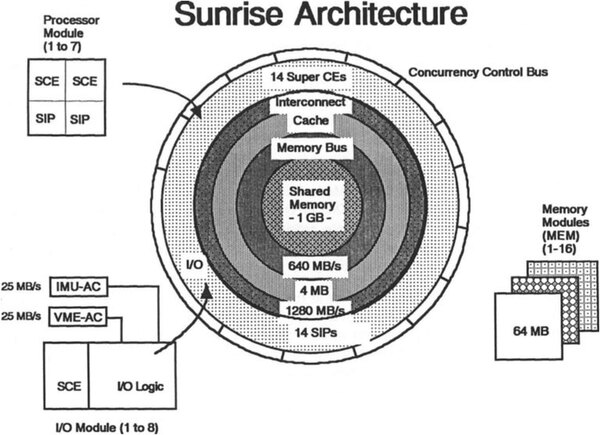
FX/2800のシステムアーキテクチャー
画像のとおり、2つのSCEと2つのSIPで1つのプロセッサーモジュールを形成する。このモジュールが1~7個の範囲で増減する。それそれのモジュールには512KBのSRAMキャッシュが搭載される。
メモリーは最大1GBを搭載可能で、キャッシュとの間は最大640MB/秒の帯域で接続される。プロセッサーモジュールとメモリーの間はクロスバースイッチでの接続となる。
下の画像はFX/2800の最大構成で、プロセッサーモジュール7枚に、外部接続用のi860カードとあわせて合計29個のi860が搭載される。
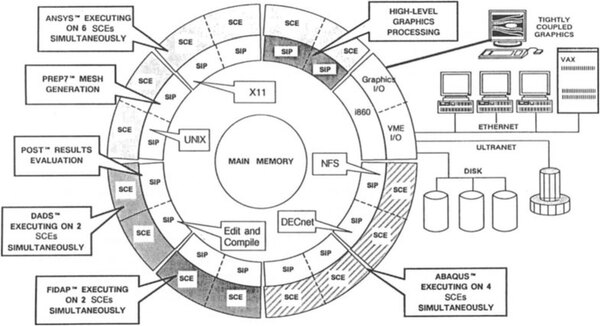
FX/2800の最大構成。なお、最小構成は、プロセッサーモジュール2枚にi860のGrpahics/VMEボードのみとなる
論文によれば、このFX/2800のシステムの性能は以下の表のとおり。
| 各ビデオカードの比較表 | ||||||
|---|---|---|---|---|---|---|
| モデル名 | FX/80 | FX/2808 | FX/2828 | |||
| プロセッサー数 | 8 | 8 | 28 | |||
| 理論ピーク性能 (MFLOPS) |
188 | 320 | 1120 | |||
| Dhrystone (MIPS) |
60 | 192 | 672 | |||
| Linpack 100 (MFLOPS) |
10 | 20 | 42 | |||
| Linpack 1000 (MFLOPS) |
69 | 200 | 720 | |||
FX/2808はプロセッサーモジュールが2枚の最小構成、FX/2828は7枚の最大構成である。特にこのLINPACKの1000×1000での性能は、わざわざ競合製品の性能比較を出してその優位性をアピールするなど、いろいろ努力をした。
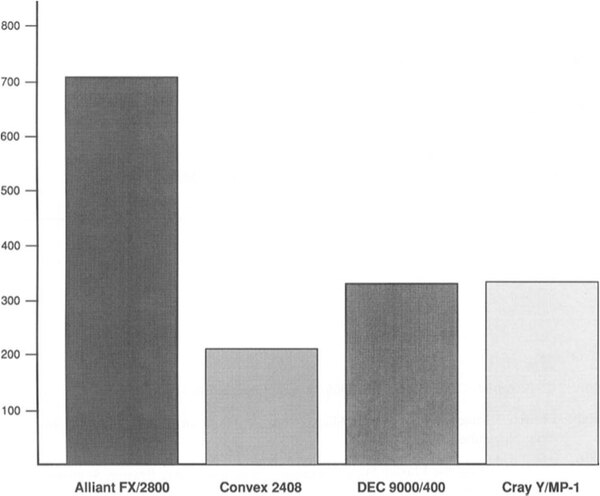
性能比較。ConvexのC2408とDECのVAX 9000/400はともに4P構成、Cray Y-MP/1は1P構成で、それと28P構成のFX/2828を比較するというあたりが無茶だとは思う
それにも関わらず、あまり売れ行きは良くなかった。1つは価格の問題である。Computer Business Reviewの1990年1月21日付けリリースによれば、FX/2800シリーズの価格は35万英ポンド~120万英ポンドとされる。
おそらくFX/2808が35万、FX/2828が120万というあたりだろう。当時の為替レートで計算するとおおむねFX/2808が58万ドル、FX/2828が200万ドルほどになる。つまり、競合製品に比べるとややお高めの価格帯に移行してしまったのである。
加えて1990年、同社はRaster Technologiesというグラフィック技術を持った会社を買収、コンピューターグラフィックの方面に新たな市場を開拓しようと目論んだのだが、売り上げにはつながらなかった。
その一方で超並列処理の機運が急速に高まりつつあることを受けて、同社も超並列の方面に乗り出すことにしたようだ。といってもゼロから超並列のアーキテクチャーを開発する時間的な余裕も金銭的な余裕もなかった。
そこで1991年11月、FX/2824(つまりコンピューターモジュールが6枚のFX/2800シリーズ)を1つのクラスターノードと称し、このクラスターノードを最大32個、HMI(High-speed Memory Interconnect)と呼ばれる最大2.56GB/秒のインターコネクトでつなぐという形での巨大超並列システムをCAMPUS/800として販売開始する。
なんか構造だけ見てるとASCI/Qを彷彿とさせる構成である。プレスリリースによれば、100プロセッサー(つまりクラスターノードが4つ)の「典型的」な構成でおおむね250万ドル、800プロセッサーの最大構成で1600万ドルとなっているほか、すでにFX/2800シリーズを利用している顧客は10万ドル以下の価格でCAMPUS/800にアップグレードできるサービスも提供していた。
ただこれはどう見ても取ってつけたかのような構成で、やや現実味に欠ける気がする。これにあわせて既存のFX/2800も最小構成を20万ドル以下に値下げするなど努力したものの、結局1992年に資金が底をつき、倒産となってしまった。
1980年代には競合メーカーに比べると有利だったSMP+ベクトルの構成も、1990年に急速な性能向上競争が始まるとむしろ性能の伸び代が少ないということで、ネガティブな方向に働いてしまったのが根本的な敗因ではある。
皮肉なのは、3人の創業者の出身元であるData Generalの方が、1999年にEMC Corporationに買収されるまで延命したことだろうか。
さて、今年も皆様にはいろいろご指摘などをいただきまして、ありがとうございました。新年はしばらくスーパーコンピューターの系譜をお休みして、久しぶりにPCの製品ロードマップをお届けする予定です。それでは皆様、良いお年をお迎えください。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ


















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












