




今回のスーパーコンピューターの系譜は前回の続きでNVIDIAのGPUである。GeForce 8000シリーズ、あるいはG80世代というべきかもしれないが、この世代でGPGPUに名乗りを上げたNVIDIAだが、いきなりこれでGPGPU全盛になった、というほど話は簡単ではなかった。

G80世代の代表作「GeForce 8800 GTX」
G80世代の最初の製品は、2006年11月に投入された「GeForce 8800 GTX」である。こちらの記事の写真にもある通り、G80コアでは16個のSP(Streaming Processor)を1つのブロック(SPA:Streaming Processor Array)とし、これを8つ並べた形である。チップ全体としては128SPという計算になる。
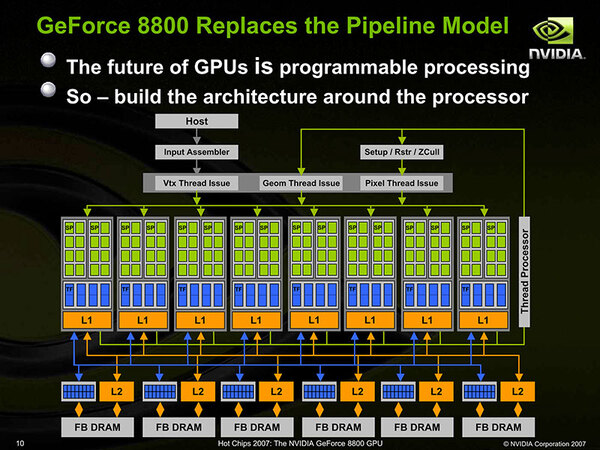
GeForce 8800 GTXの構造。シェーダーが完全に均質化(Unified)されている。2007年のHotChips 19でNVIDIAのErik Lindholm氏とStuart Oberman氏が発表した“The NVIDIA GeForce 8800 GPU”のスライドより
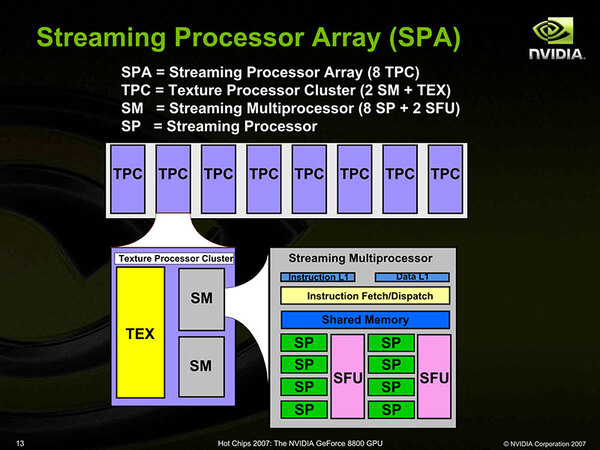
各々のSPAの中は下の画像のように構成されている。テクスチャーユニットが配されるのは、まだGPGPUとしての用途よりもGPU用途が多いからで、これに2つのSM(Streaming Multiprocessor)が組み合わされる。
SPAの構造。SPあるいはSFUの演算は、SM内のShared Memoryに対して行なう。これをL1/L2経由でメモリーに書き戻す
各々のSMは8つのSPと2つのSFU(Special Function Units)から構成される。1つのSPは32bitのMAD(Multiply-Add)ユニットで構成されるもので、整数演算とIEEE754に準拠した32bitの浮動小数点演算が可能である。
このMADユニットは名前の通り加算と乗算が可能なもので、逆に言えばそれしか出来ない。実際実行できるものはADD/MUL/MAD(Multiply-Add)/MIN/MAXといった演算に限られる。
ただ、GPUやGPGPUに求められる演算の大半がこれで済むとは言え、これ以外の計算も時には求められる。それを実行するのがSFUで、RCP/ESQRT/LOG/EXP/SIN/COSといった特殊な演算や値の補完、これを応用した逆数の計算などが実行できるようになっている。
さて話を戻すと、2つ上の画像では8つのSPAとそれ以外では、動作周波数が異なっている。GeForce 8800 GTXの場合、コア全体(SPA以外)は575MHz動作なのに対し、SPAは1350MHz駆動となっており、2.34倍というやや変則的な周波数比である。
この比は一定ではなく、だいぶ後に登場する「GeForce 8800 GT」(G92コア)ではそれぞれ600MHzと1500MHzで2.5倍設定となっている。要するにかなり自由に設定できるようになっているわけだ。なぜこのような複雑な方式を取ったかはいくつかの要因が考えられる。
G80はNVIDIAにとって初めてのGPGPU構成の製品であり、GPGPUに使うときにシェーダーとメモリー、周辺回路がどのような頻度で使われるかは完全に読みきれなかった。
ただ、もともとDirectX 10のUnified Shader化により、GPU側は1つのシェーダーコア(上の画像で言うところのTPC)がひたすらブン回る構成を考えていた。
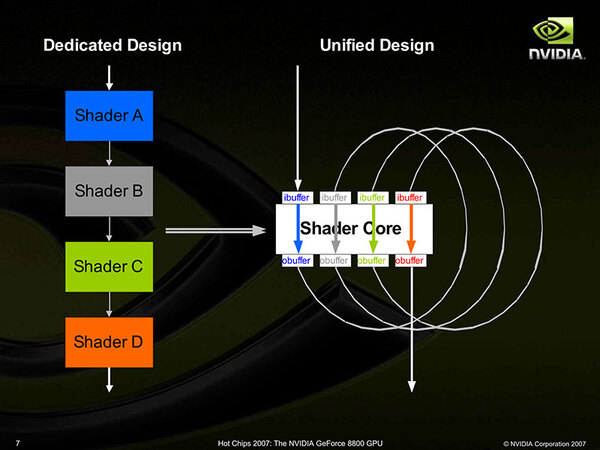
G80は1つのシェーダーコアがひたすらブン回る構造になっている。実際にどの程度ブン回るかは設計時点では読みきれていなかったようだ
こういう場合では実装の方法は2つあり、下のどちらかになる。
- Unified Shader 4つをそれぞれShader A/B/C/Dの役目に割り当てるパイプライン方式
- 1つのUnified Shaderを4倍速でブン廻す方式
G80の場合、シェーダー数そのものは128とそう多くないため、パイプライン方式では間に合わないと判断したのだろう、ぶん回し方式を取るのはある意味必然とも言える。加えて言えば、G80の世代は90nmプロセスで製造されていたが、当時のTSMCの90nmでGPU全体を1GHz以上でブン廻すと、消費電力がかなり大きくなることも考えられた。
それにメモリーコントローラー(GDDR3 900MHz)や2次キャッシュなどは別に1GHzを超える速度でブン廻す必要は皆無であり、500~600MHzで十分間に合う程度だった。このあたりも、設計のバランスを考えると分離して別々の速度で動かすのがリーズナブルと考えられた。
→次のページヘ続く (G80世代では思った性能が出ない)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")




























{kind=link}