




Prescottで得た知見や技術は
インテルの財産になった
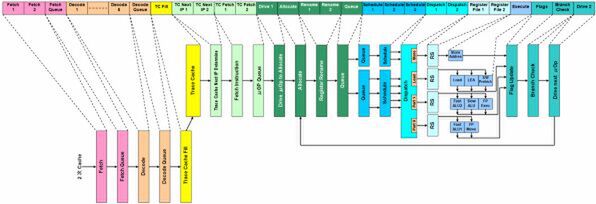
図1 Prescottのパイプライン構造図
インテルがPrescottでこのようなデコーダー部を実装した理由はなにか。この当時インテルは「Yamhill」(後のIntel 64)「Vanderpool」(後のIntel VT)「LaGrande」(後のIntel TXT)といった新技術をCPUに搭載しようとしていた。これらはPrescott登場時点ではまだ完全に仕様が固まりきっておらず、特にYamhillはまったく命令体系が変わってしまったほどだ。こうした変更に対しても、柔軟に対応できるようにしようというのが、Prescottの基本的な設計思想である。
もちろん、こんな仕組みでは性能を追求するのは難しくなる。新しい命令セットを導入する場合、動くプラットフォームがないと普及しない。だからまずプラットフォームを用意する必要がある、と判断したのではないかと思われる。性能に関しては、5GHz動作という力技で解決できると踏んだのだろう。こうした理由で、Willametteととはデコード部がまったく異なる実装になっているのは間違いない。
次がALUそのものの違いだ。PrescottのALUは64bit命令を扱えるように拡張されており、Fast ALUは32bit幅の倍速、Complex ALUは64bit幅にそれぞれ拡張された。ただし冒頭で説明したとおり、命令そのものを倍速で発行する仕組みは入っていないので、32bit命令と64bit命令でスループットはまったく変わらない。その意味では無駄の多い実装である。
この結果として、Register Fileなどもすべて、64bitを扱えるように拡張されている。Register Fileの数も増やされている。Register Fileのエントリ数は、Willamette世代がInteger/FPともに128なのに対して、Prescott世代では倍の256に増やされているもようだ。また細かいところでは、「Load/StoreバッファがどちらもWillamette世代から倍増されている」という説もあるが、筆者はこれに疑問を持っている。ただ、64bitのLoad/Store命令のスループットを32bitと同等にするためには、帯域を倍増させる必要があり、そのため1次データキャッシュとの接続部のデータ幅そのものは、Load/Storeともに64bitに拡張されていると思われる。
そうなると、これを格納するLoad/Storeバッファのデータ幅も64bitであるから、エントリ数が増えなくても物理的なサイズが倍に膨れ上がることになる。これを「エントリ数倍増」と判断したのではないかと思われる。性能やパイプラインのバランスを考えると、ここでLoad/Storeバッファのエントリ数を増やしても、ほとんど性能に寄与しないと考えられるからだ。
パイプラインの違いの説明は以上である。「たったこれだけ?」と思われそうだが、インテルの資料などを読む限り、違いはこの程度に留まっているようだ。CPUとしての改良で言えば、「SSE3」命令のサポートや一部のFPU命令の高速化なども挙げられるが、これはほとんどがデコード段と、一部実行ユニットの改善程度の話だ。パイプラインそのものはほとんど変わらないと思われる。
そして高速動作に関しては、パイプラインをいじらずに、90nmプロセスの「歪シリコントランジスター」に、「LVS(Low-Voltage Swing)Technology」という「回路素子の高速化+回路技術の高速化」でカバーしようとしたのだろう。その意味では、NetBurst Architecture世代をTick-Tockモデルで表すると、こうなるのかもしれない。
- Willamette(Tock)→Northwood(Tick)→Prescott(Tock)
- ではなく
- Willamette(Tock)→Northwood(Tick)→Prescott(Tick)
Prescottが商業的には大失敗に終わり、続く「Tejas」まで巻き込んだという話はすでに何度もしているので繰り返さない(関連記事)。それでもNetBurst Architectureで実現したTrace Cacheの技法は、「Nehalem」の「Loop Stream Detector」(LSD)や「Sandy Bridge」の「μOp Decoded Cache」として蘇ったし、ハイパースレッディングも同様である。
倍速ALUやLVS Technologyは今のところ復活の兆しはないが、こうした技術を磨きこんで再び復活というのは、インテルのお家芸だけにまたいつか登場しないとも限らない。今振り返ってみると、NetBurst Architectureそのものは結果として消滅してしまったが、ここで得た知見はインテルにとって、かなり有用だったであろうと思う。
この連載の記事
-
第769回
PC
HDDのコントローラーとI/Fを一体化して爆発的に普及したIDE 消え去ったI/F史 -
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 - この連載の一覧へ











が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")













