





Prescottコアの「Pentium 4」
今回は予告どおり「Prescott」について解説するが、その前にひとつ前回の補足をしておきたい。
NetBurst ArchitectureのALUに関する補足
Twitterで「倍速ALUが16bit分しかないと言うのは間違いだと思います。なぜなら32bitの演算を行なっても16bitと同等のスループットだからです」というコメントがあった。
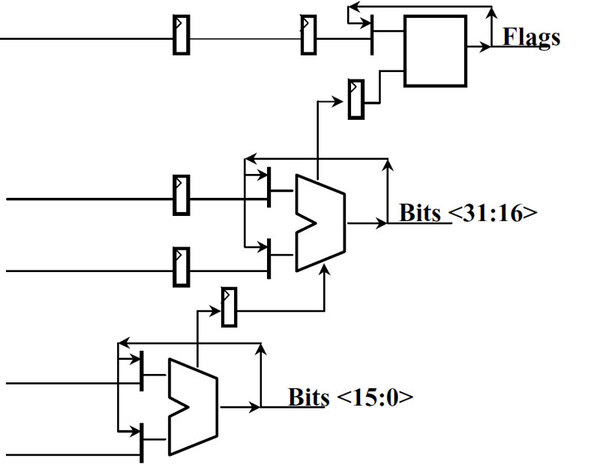
NetBurst ArchitectureのALUの構造。図では下と上、2つのALUが配されているように見えるが、実際はひとつの16bit ALUが2倍速で動いている。上位16bit側のALUは入力の手前にラッチが用意され、下位16bit分のALUが動作している間は、上位16bit分のデータを保持している
上の図は「Intel Technology Journal Q1, 2001」の、「The Microarchitecture of the Pentium 4 Processor」から引用したものだ。Pentium 4では16bit幅のALUが、このように2段構造になっている。最初のALUがデータの下位16bit分を、次のALUがデータの上位16bit分をそれぞれ計算し、最初のALUからのキャリーフラグがタッチ経由で2つ目のALUに渡されるように構成されている。
この目的について同記事では、「大雑把に全μOpの60~70%がALU命令である」としたうえで「これを高速に実行するため、ALUはメインクロックの2倍の速度で動作し、しかも遅延が短縮できるため、結果として処理性能が上がる」と説明している。この仕組みをインテルは「Staggered add」(千鳥足加算)と呼んでいるが、このように物理的にALUは間違いなく16bit幅である。
ではなぜ16bit命令でスループットが上がらないのか?。それはあくまでこの仕組みは、「ひとつの32bitデータを2つの16bitデータに分割して倍速処理する」というものであり、「2つの16bit命令を倍速に処理する」ものではないからだ。分割するのはデータ幅のみで、命令そのものの発行速度は、この仕組みをもってしても倍にはならない。
そもそもx86では16bit命令だろうが32bit命令だろうが、命令そのもののサイズは変わらない。もし倍速で命令を発行しようとするとこのFast ALUのみならず、SchedulerやRegister Fileなども倍速で動かないと間に合わなくなる。技術的可能性としては、「Macro Fusionを使って、2つの16bit ALU命令をひとつの32bit ALU命令にまとめてしまう」なら可能だ。しかし、実際にはレジスタの割り当てなどを考えると非現実的だろうし、そんな機能はNetBurst Architectureには搭載されていない。誤解しやすい点であるが、この仕組みでも16bit演算のスループットは変わらないわけだ。
まるで変わっていない?
WillametteとPrescottの内部構造
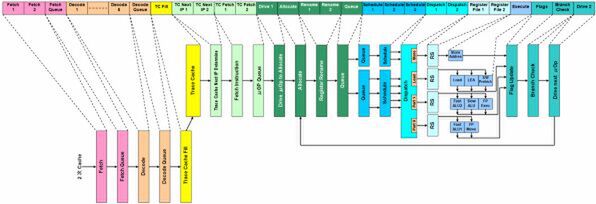
図1 Prescottのパイプライン構造図
それではNetburst Architectureにとどめを刺したPrescottの構造について解説しよう。インテルは意外なほど、Prescott世代のパイプライン構造を公開していない。2004年に公開された「Intel Technology Journal」の「Volume 08 Issue 01」は「Intel Pentium 4 Processor on 90nm Technology」と題したPrescott特集号である。その前書きにはこうある。
The papers discuss its microarchitecture including the thirteen new instructions referred to as SSE3 and the 31-stage pipeline
(この文章はSSE3として知られる13の新命令と、31段パイプラインを含むマイクロアーキテクチャーについて論じる)
それにも関わらず、肝心の31段の詳細は載っていない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















