




0レベルキャッシュで高速化を実現?
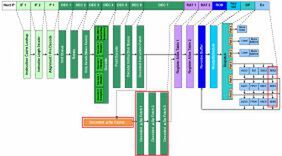
図1 Sandy Bridgeの内部構造図。赤枠内がNehalemからの主な変更部分
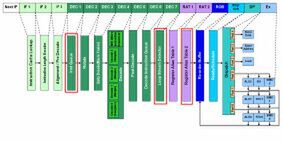
図2 Nehalemの内部構造図
まずはフロントエンドから見ていこう。Nehalemでは28命令の「Loop Stream Detector」(LSD)をデコードの後に搭載して、繰り返し処理が発生する場合の処理の効率化と省電力化を実現した(右図のDEC 7段)。
Sandy BridgeではこのLSDの代わりに、最大1500μOpの容量を持つ「Decoded μOp Cache」を搭載した。面白いのは、Decoded μOp Cacheの制御は新設計されたBranch Prediction Unitが行なうことだ。

「Decoded μOp Cache」の説明図。扱いとしては1次キャッシュよりもさらに内側ということで、「L0 Cache」とも呼ばれている

Decoded μOp Cacheが動作中は、IF 1~DEC 6までの各ユニットは休止状態になる、という点はNehalemのLSDと同じ
Nehalemの場合、「DEC 7」にあったLSD自身が「繰り返しがあるか否か」を判断していたが、貯めておけるμOpが最大1500個ともなると、LSD単体で管理するのは不可能となったようだ。繰り返しの有無の判断は、新設計された分岐予測ユニットから制御されることになる。
この結果としてパイプラインは、「IF 1」~「DEC 6」まではNehalemのものと構造的には一緒であるが、DEC 7が複雑になっている。分岐予測ユニットが「繰り返しではない」(=Decoded μOp Cacheにヒットしない)と判断した場合は、DEC 6の出力がDEC 7経由で「RAT 1」に渡されるが、この際にDEC 6からのμOpがコピーされて、Decoded μOp Cacheに格納される。
一方で分岐予測ユニットが「繰り返しである」(=Decoded μOp Cacheにヒットする)と判断した場合は、DEC 6の出力ではなくDecoded μOp CacheからμOpを取り出して、RAT 1に渡すことになる。ただし、この際最初だけ余分に2サイクルかかるようで、「μOp Cacheにヒットした」ケースでは、最初だけ見かけ上パイプラインが18段あるように見えることになる。
インテルがいまだにSandy Bridgeでの分岐予測ユニットについて、詳細を明らかにしていないため断言できないのだが、どうやら分岐予測を従来のx86命令ベースからμOpベースに作り変えたと思われる。この結果として分岐予測のベースとなる入力は、「Post Decode」(DEC 5)のステージの後で出てくるμOpを基準に判断することになる。DEC 6と平行して1サイクルで分岐の有無を判断するのだが、そこからDecoded μOp Cacheにアクセスして目的のμOpを取り出し、RAT 1に入力するまで3サイクル要するようだ。
誤解のないように書いておくと、この2サイクル余分にかかるというのは、最初にDecoded μOp Cacheをアクセスする時だけだ。以後はパイプライン動作のため、余分なサイクルは入らない。
Decoded μOp Cacheの導入によるメリットは、より広範囲な繰り返し処理の高速化である。LSDが格納できる28μOp分では、非常に小さな処理のループを高速化する程度の効果しか期待できない。それが1500μOp分となれば、もう少し大きなループ、あるいは複数の処理ループの高速化が期待できることになる。また、これが有効な間はNehalem同様に、IF 1~DEC 6が止まることで省電力化が期待できるわけで、CPUの省電力化を進める上でのメリットになる。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ










が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

















