遠藤諭のプログラミング+日記 第209回
人文社会・エンタメ芸術系でAI活用が遅れると、社会的打撃は大きい
鉄腕アトムー科学+魔法=AI on NVIDIA DGX Sparkが出した答えとは?
2026年06月10日 09時00分更新


御徒町のカフェで、NVIDIA DGX Sparkを前にノマド作業をしている。液晶の向こうに小さく本体が見える。Tailscaleを使えば、ノートPCからたいていのことはできるのだが、コマンドを打ってから返ってくる感触は、やはり少し違う気がする。などと思っていたら、NVIDIA SyncでもTailscale連携が扱えるようになってしまった。
日本の"otaku"を64分類してみたい
2010年から2015年にかけて、角川アスキー総研では「メディアとコンテンツに関する1万人調査」というものを行っていた。そのころ、一緒に仕事をしていたNくんやIくんと、「日本のオタクを64分類してみたいよね」なんて話をしていた。
この“オタク64分類”には、元ネタのようなものがある。アメリカで売られていた「The 56 Geeks」というポスターである。いまでも検索すれば見つかるが、そこにはアニメ好き、マンガ好き、映画好き、音楽好き、Apple派、Linux派といった具合に、さまざまな“ギーク”が分類されている。
見ていて楽しいポスターなのだが、当然ながら、そこに描かれているのはアメリカのギーク文化である。アニメとマンガの重なり方も、ゲームや同人や特撮やアイドルとのつながり方も違う。ならば、日本版の分類を作るとどうなるのか。せっかくなら64分類くらいまで広げてみたい。そんなことを、当時、話をしていたのだった。
1万人調査のテーマは「メディアとコンテンツ」だったので、好きなキャラクター、放送中のアニメ番組、ゲーム、映画などについての設問はかなり細かく用意していた。映画業界、新しい動画配信プラットフォーム、ゲーム機メーカーの案件なども手がけていたが、クライアントが求めるのは、たいていの場合、「数字で裏づけられたデータ」だった。
もちろん、それはそれで大切な仕事である。ただ、その数字の向こう側にある「この人は、どういう好きの回路を持っているのか」というところまでは、なかなか踏み込めなかった。だから“オタクの64分類”は、実際の作業としてはほとんど手つかずのまま残っていた。
気がつけば、それから10年以上が過ぎている。このテーマはずっと、私の頭の中で宿題のようなものとなったままである。
DGX Sparkがもたらした“仕事と遊びと学び”の新しい境界
今回の話は、その「64分類」そのものではない。ただ、その宿題に少し近づくための道具を、思いがけず手にしてしまった、という話でもある。
きっかけは、2025年10月にNVIDIAから“デスク上のAIスーパーコンピューター”と称して出荷開始されたDGX Sparkだった。このマシンについては、以前に「DGX Spark」は現代の「Apple II」である」という原稿を書いた。
ニュースによると、WindowsネイティブのこのクラスのAIコンピューターが2026年秋(?)には主要メーカーから発売される予定だという。搭載されるRTX Sparkは、NVIDIAのAI向けスーパー チップ/プラットフォームで、DGX SparkのGB10と同じ流れにあるものらしい。これが本当に広がるなら、私のようなライトなローカルLLM活用層は一気に増えるかもしれない。
いま、AIの使い方は大きく二極化して見える。片方には、ChatGPTやNotebookLM、プログラマならClaude Codeのようなツールを、仕事の相棒として使う人たちがいる。もう片方には、モデル研究やファインチューニングを本格的に行う専門家がいる。しかし、その中間にも、かなり面白い場所がある。自分の手元に少し強いマシンを置き、データをいじり、モデルを動かし、仕事とも遊びとも学びともつかない作業を進める場所である。この記事で紹介したいのは、まさにそのあたりの使い方だ。

これは私の仕事場で使っているDGX Sparkである。左上に端っこだけ見えるのは、Apple ComputerがApple IIとMacintoshの間に発売したApple IIIだ。1990年代に秋葉原の五洲貿易でジャンクとして購入したものである。Apple IIIのトラブルは××のコンデンサが原因と友人のMくんが教えてくれ、実際に30分ほどで修理してくれた。
DGX Sparkで私が最初にやったのは、以前の記事で紹介した自作AI画像検索ソフト「画像さがす君」をローカルLLM化することだった。AI向けコンピューターはいろいろあるが、NVIDIAのCUDAに対応しているという安心感はやはり大きい。同社のソフトウェア環境は、そのままクラウド上の本格的なAI開発にもつながっていく。そう考えると、人材教育の面でも意味がありそうだ。
では、私自身はほかに何をしているのか。ご多聞にもれず、ComfyUIから使える画像・動画系の生成も試している。いまどき、ChatGPTやGeminiでも画像生成は気軽にできる。わざわざローカルでやる意味があるのか、と言われそうだが、やってみると違いはある。パラメーターを明確に指定して再現性を高められるし、3Dモデルを作るもの、加工可能なSVGの線画データを生成するものなどもある。そういうことを、触っているうちに知ることになる。ただし、最初からやりたいと思っていた動画品質の向上(Topaz AIのような)は、手つかずのままである(詳しい方がいたらお教えいただきたい)。
もうひとつ、このコラムで以前紹介した「DokodemoLLM」もローカルLLM対応にした。「DokodemoLLM」は、Apple Intelligenceの“作文ツール”やWindows PowerToysの同種の機能に近いものだが、プロンプトを履歴から編集して使えるので、ずっと便利に使うことができる(手前ミソだが。もちろんクラウド経由のAPIも利用可能=コチラからダウンロード可能)。かなり使い込んでも、トークンの無料枠か月額数百円もいかない上に品質もGPTやGeminiを呼んだほうがよいのだが、ローカルLLMの練習問題のつもりである。vLLMとLlama-3.1-8B-Instruct-NVFP4の組み合わせだ。
Wikipediaをベクトル化してポップカルチャーを俯瞰しよう
日本のオタクを64分類したい。そう考えたとき、頼りになる素材のひとつがWikipediaである。日本語Wikipediaには約150万項目があり、そのうちアニメ、マンガ、ゲーム、映画、ライトノベル、タレント、声優といった項目だけで全体の30%以上を占めるという見方もある。正確な割合はともかく、少なくとも日本語Wikipediaがポップカルチャーの巨大な索引になっていることは間違いない。
そこで、日本語Wikipediaの項目をまとめてベクトル化、つまりエンベディングしてみることにした。いまどきのテキスト処理を始める前の“地ならし”のようなものだ。
もちろん、ChatGPTやGeminiのような大規模言語モデルも、Wikipediaのテキストを大量に学習しているはずである。だから、質問すればWikipedia由来の知識がいくらでも出てくると思われる。しかし、こちらが欲しいのは、質問に対するもっともらしい答えではない。元のWikipediaのテキストに戻ったり、そこから別の見方で並べ直したり、自分の手でじっくり作業したりしたい。そうなると、ChatGPTやGemini(正確にはその言語モデル)は、あまり役に立つわけではない(人間が頭で覚えたことと同じでデータそのものではないからだ)。
ベクトル化自体は、DGX Sparkを持ち出すまでもないシンプルな作業である。むしろ大事なのは、ベクトル化したあとに、そのデータをどう眺め、どう組み合わせ、どう使うかのほうだ。
なお、今回は私のマシンの中で閉じた使い方しかしていないが、Wikipediaのベクトル埋め込みデータを何らかの形で公開したり再利用したりする場合には、当然ながら利用条件への配慮が必要になるだろう。
“鉄腕アトム”引くことの“科学”、足すことの“魔法”は?
このデータを使って、“Pop-Culture Explorer(DGX Spark Edition)”という、少し大げさな名前のソフトウェアを作ってみた。
この分野に詳しい人なら、10年以上前に話題になったWord2Vecをすぐに思い出すだろう。「今さら?」という感想もあるかもしれない。けれども、日本語Wikipediaのポップカルチャー項目をまるごと飲み込んだベクトルである。「吾妻ひでおの『不条理日記』に似ている作品は何か?」といった問いにすぐに答えが返ってくるのは、ちょっとした感動がある。初期段階での結果は次の通りだった。
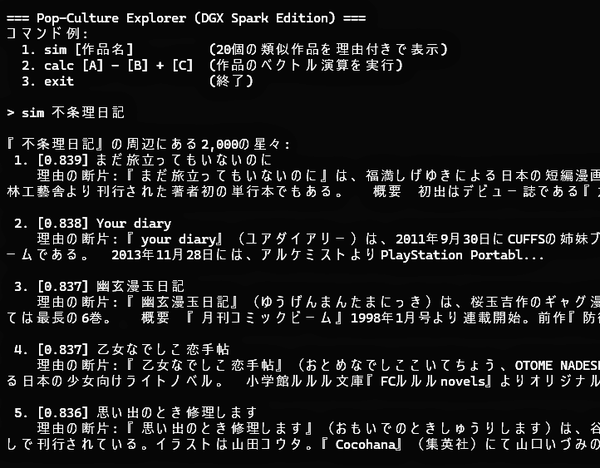
Pop-Culture Explorer(DGX Spark Edition)の実行例
たとえば短編マンガ『まだ旅立ってもいないのに』(福満しげゆき)、18禁恋愛アドベンチャーゲーム『your diary』(ユアダイアリー)、桜玉吉の『幽玄漫玉日記』(ゆうげんまんたまにっき)など、ジャンルを越えて作品名が並んでくる。
このような検索だけなら、実のところ、コンテンツの説明文をそのまま抜き出すだけでもかなり役に立つのでそのようにしている。しかし、DGX Sparkを使えば、要約や解説を生成することもできる。この点については、あとで改めて触れる。
ベクトルにしているのだから、もちろんベクトル演算もできる(これがまさにWord2Vec的)。
私は、『鉄腕アトム』が放送されていた時代に小学生だった世代である。高井達雄さん作曲、谷川俊太郎さん作詞の主題歌には、「科学の子」というフレーズが出てくる。ところが、ひねくれた小学生だった私は、「科学の子」と言われても、科学からポンと子どもが出てくるわけではないだろう、などと思っていた。実際、『鉄腕アトム』には、もっとドロッとした社会意識やモラルなども描かれていた。
アトムが、自分の何十倍もある相手を小さな手で支えて運ぶシーンを見ると、子ども心に「物理法則的におかしいだろう」と思った。結局、「わからずやめー」と言いながら10万馬力のパンチで解決するしかないのか、とも思った。そもそも、なぜ海水パンツに赤い長靴なのか。いま思えば、私は、なんとも面倒くさい小学生だった。
そんな記憶があるので、「鉄腕アトム」から「科学」を引いてみたくなった。「科学」が「正義」のように描かれていることが、ちょっとした錯覚ではないかと思ったからだ。しかし、ただ引いただけでは少し寂しい。そこで「魔法」を足してみることにした。すると、Pop-Culture Explorer(DGX Spark Edition)は次のような答えを返してきた。
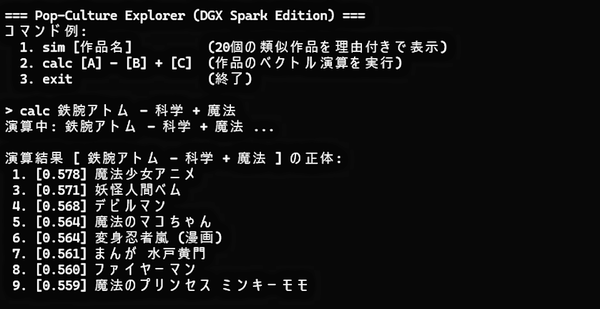
ベクトル演算で“鉄腕アトム ー 科学 + 魔法”を実行してみる
「科学」を引いて「魔法」を足すのだから、『ハクション大魔王』のようなものが出てくるのではないかと期待した。ハクション大魔王とアクビ娘は、鉄腕アトムに匹敵するかそれ以上のキャラクターだと私が思っているのもある。ところが、先頭に出てきたのは「魔法少女」という、作品名ではなく項目名だった。
なんのデータの加工もしていない演算なので、当然といえば当然である。それでも、「科学」を引いたことでロボット勢が脱落。「魔法」というあいまいな概念を足したことで、『妖怪人間ベム』、『デビルマン』、さらには『まんが 水戸黄門』まで出てきた。『まんが 水戸黄門』には幻術や妖怪も出てくるらしい(?)。
小野田大臣の「あなたの"otaku"属性は診断テスト」の結果やいかに?
ここまでは、まずは軽く試してみたという段階である。しかし、このベクトル化した日本語Wikipedia項目データは、その後、ZEN大学HARC(コンテンツ産業史アーカイブ研究センター)での私の取り組みともつながっていった。HARCについてはコチラを参照してほしい。
私が取り組んでいるテーマは、「メディアスタック・クロノロジー」と呼んでいるものだ。
メディアやコンテンツは、単独で存在しているわけではない。いくつもの層が積み重なったエコシステムの中で生まれ、流通し、受け止められている。音楽を例にすると、いちばん下には数学や物理、生理学のような基礎がある。その上に、シンセサイザーや録音機材などのテクノロジーが乗る。さらに、それを使う楽器や制作環境があり、アーティストが楽曲を作り、レコード、配信、ライブといった経路を通って、ようやくオーディエンスに届く。そのあいだには、コミュニティ、批評家、専門メディアも存在する。
テクノロジーなしにアート表現は成立しない。これは、フレスコ画の時代からずっと変わっていないのではないか。1990年代には、ある音楽レーベル関係者が「アイドルの曲はテレビで20回耳に入れば必ず一定のヒットになる」と私に言ったことがある。作品とメディアと流通と受け手が、どのように結びついているのかを端的に示す発言だった。
その積み重なりと相互作用を、時間軸の上で見えるようにしたい。それが「メディアスタック・クロノロジー」である。しかも、それは時代ごとにそこに生きた人々の“世代”によって変化を続けていることを示したい。
そのために、ちょうど1年ほど前から「Xnative/Timeline」というソフトウェアを作っていた。そして、それを応用したデモンストレーションを、2026年4月25日と26日に幕張メッセで開催されたニコニコ超会議2026で展示・公開することになった。ZEN大学の大学祭「展軸祭2026」におけるHARCのブースである。
そこで展示・公開したのが、「あなたの"otaku"属性は診断テスト」というソフトウェアだった。

ニコニコ超会議2026・展軸祭HARCブースでの診断テストのようす。2端末がほぼ埋まっており待ちが出ることもあった。2日間で200人の診断を行うことができた。
診断を受ける人は、まず画面上で自分の生まれた年をセットする。だいたい9歳くらいから利用できるようにしてあり、その人が、いつ、どんなコンテンツを見たのか、どんな製品に触れたのか、何に萌えたのか、どんな影響を受けたのかを順番に選んでいく。選ばれた項目は、その人の年齢に沿って年表の上に積み重なっていく。最後に、その履歴をAIに渡して診断してもらうしくみである。
診断にはOpenAIのGPT-5.4やGemini系のモデルを利用した(タイミングや都合により切り替えている)。つまり、診断そのものはAIに丸投げである。
学園祭でコンピューターを使って診断を行う試みは、1970年代からあった。野末陳平さんの姓名判断をFORTRANでプログラム化し、HITAC-10やFACOM 230などで動かしていた時代を、「涙が出るほど懐かしい」いう人はいるはずである。当時も「AIが診断します」とうたうものはあったが、中身は大いにあやしかった。それが2026年のいま、本当にAIに診断させられるようになった。これは、私のような世代にはとても感慨深いことだが、これからは当たり前になるのだろう。
AIによる診断なので、出力形式もこちらの指定しだいで変えられる。今回は、結果を四字熟語風に表現することにした。診断自体、便宜的なしかけもあるのだがちょっとした演出である。
あなたの"otaku"属性は診断テストの説明シート(4月25、26日配布)
作品や製品を選択した結果をもとに、「主属性」、「副属性」、「裏属性」を割り当てる。主属性と副属性は、いわば「本命」と「対抗」である。裏属性は少し離れたところにあるが、その人の中にたしかに混じっている「穴馬」的な属性とした。用意した属性は、以下の11種類である。
世界観没入:その世界に入れる感じで選ぶ属性
機構偏愛:道具や仕組みそのものに心が動く属性
未来感受:次が始まる気配や時代の切り替わりに反応する属性
異形親和:少し危うく変なものに熱を感じる属性
日常浸透:生活に溶け込む手触りを長く愛する属性
越境回遊:ジャンルや媒体の境界を軽やかにまたぐ属性
少年回路:冒険と発見の想像力に火がつく属性
少女回路:変身と関係性、内面の揺れに惹かれる属性
反復愛着:何度も戻ることで好きが深まる属性
作者偏信:作り手の癖や姿勢まで含めて愛する属性
記録蒐集:好きなものを系譜や記録として抱える属性
これ以外にも、「惹かれやすい領域」として「Apple美学」や「萌え/美少女」、「匿名ネット文化」などを出すようにした。さらに、AIには「あなたの異名」も生成してもらった。
この異名については、大学祭の準備段階でHARC所長の細井浩一さんにも試してもらった。そのとき、なかなか強烈な結果が出た。細井さんからは、次のようなコメントをいただいた。
「さっそくやってみました。《螺鈿万華鏡、奇譚の断片を紡ぐ》と感性分析され、《ん?》と思っていたら、まとめで《過去の異形な作品とハードウェアを愛する、孤高のアーカイブマスター》と喝破され、ぐうの音も出ませんでした。完敗です」
名前まで入力して診断した場合、裏側はGPT-5.4である。正真正銘のアーカイブマスターである細井さんに対して、こういう診断が出るのは、ある意味では当然かもしれない(それは診断ではなくて検索だが)。しかし、今回の診断は匿名で行ったのだ。つまり、一人ひとりの肩書きや背景は診断結果に影響しない。細井さんの場合も、選択した作品や製品が多かったこと、そしてその選び方でこの診断になったのだろうか?
ほかにも、「妙に当たっている」という話をいくつか聞いた。占いや診断というものはいろいろな意味で恐ろしい。
診断時に記入してもらった年齢や性別、そして選択された項目については、少しずつ分析を進めている。すでに興味深い結果も出てきているので、ここで紹介する予定である。
なお、ニコニコ超会議には、小野田紀美経済安全保障大臣がゲストとして来場し、HARC関連のステージにも登壇された。その合間に「あなたの"otaku"属性は? 診断テスト」の噂を聞きつけ、ブースにも立ち寄ってくださった。診断結果はニコニコニュースでも紹介されているが、主属性は「少年回路」だった。
ローカルLLMによる設問設計──この程度のことから始めるのがよいのではないか?
ここまで読むと、診断の面白さはAIの出力にあるように見えるだろう。実際、診断文そのものはGPTやGeminiに任せている。もちろん、どのような指示を与えるか、どのような形式で出力させるかには相応に工夫しているわけだが。
その意味で、この診断で本当に大変だったのは、そこではない。診断に使う約1000項目の選択肢をどう用意するかである。
来場者には、自分が好きだったもの、影響を受けた作品や製品を選んでもらう。そのためには、マンガ、アニメ、ゲーム、テレビ番組、映画、インターネット、ハードウェア、ソフトウェアといったジャンルごとに、さらに時代ごとに、できるだけ偏りのない選択肢を並べる必要がある。メジャーな作品ばかりで占めたら意味がない。できるだけいろんな傾向のコンテンツや製品を入れ込む必要がある。だから、必要なのは常識ではなく注意深さともいうべきものである。
ところが、そうしたことについてバランスよく知っている人など、ほとんどいない。ChatGPTやGeminiに聞けば、それなりに「優等生的な答え」は返ってくる。けれども、人間と同じように、抜けもあれば偏りもある。
そこで役に立ったのが、先ほどのWikipediaベクトルデータである。
ベクトルデータは、意味の近さを扱える。その一方で、人間の記憶や好み、AIのもっともらしい語りとは少し違う、冷たい客観性がある。しかも、根拠になっている元データとの関係性というものが明確にある。
そこで、日本語Wikipediaの項目のうち、コンテンツに関係しそうな約4分の1を抜き出し、最初は9分類、最終的には100分類まで表示しながら、選択肢を決めるための参考データを求めた。各クラスターの中心に来る作品は、たいていの場合、あまり一般には知られていないものになる。そこで、外国語版Wikipediaのページ数が多い順に並べて表示するようにした。
もちろん、私自身も知らない作品がたくさん出てくる。そこで、各作品には要約文も表示するようにした。DGX Sparkを使っている利点を活かし、Ollama経由でOpenAIのgpt-oss-120bというモデルを動かした。作品の要約だけでなく、各クラスターが何を意味しているのかについても、AIで説明文を生成させた。
この作業は、派手ではない。しかし、やっていると、机の横に調べものの得意なアシスタントが座っていて、黙々と候補を出し、要約し、分類の意味を説明してくれるような感覚がある。AIの使い方としては地味だが、こういう地味さこそ実用的なのではないかとも思う。
最終的に、「あなたの"otaku"属性は?」診断テストで用意した選択肢は、以下のような構成になった(カッコ内は選択肢の数)。
MNG: マンガ(213)
ANM: アニメ(203)
GM: ゲーム(199)
TV: テレビ番組(176)
MOV: 映画(136)
NET: インターネット(125)
HAR: ハードウェア(138)
SW: ソフトウェア(141)
おそらくこれは、私がDGX Sparkを使って行った作業の中で、いちばん地味で、いちばん単純な使い方である。
しかし、よく考えると、むしろこういう作業こそAIに向いているのではないか。特別な職人技を代替するわけではない。専門家の助言や論考を一気に書かせるわけでもない。画像や映像を生成して驚かせるわけでもない。人間がこれまで、調べ、見比べ、抜けを探し、最後に判断してきた作業を、少しずつ肩代わりしてくれる。ここにも、いまのAIの大きな意味があったのだと気づかされた。
もう少し具体的な例をあげれば、Wikipediaで「1966年の漫画」というCategoryがあり、それを集めたページも用意されている。ところが、よく見てみると『ウルトラQ』や『ウルトラマン』までこのページに登場する。それぞれのページを見てみれば、たしかにコミカライズされているのだが、たぶん99パーセントの人が「テレビ番組」とだけ判断したい情報である。Wikipediaをデータとして使えるようにするWikidataというものもあるが、逆にこうした文章に埋もれた情報を拾いたいこともある。
要するに、いままでアルゴリズムで解決するにはあまりに大変だったことが、AIに対して言葉で指示するだけでかなりの精度でできるようになった。
ところで、生成AIが、この1年間で圧倒的に効果を発揮しているのは、なんといってもプログラミングの世界である。言葉で指示してプログラムのコードやそのドキュメントを書かせるといったことが、ほぼ自動化されてしまった。まさに、青天の霹靂である。まともなプログラマほど、ゼロから手でコードを書く時間は限りなくなくなり、設計し、検証し、AIに直させる仕事へと移っているように見える。
この変化を「プログラマーの話」として片づけてしまうと、かなり危うい。プログラミングで起きていることは、これから多くのジャンルに広がっていくはずだからだ。
たとえば、人文科学・芸術系の人たちが、バイブコーディングやClaude Codeに代表されるAI開発支援の変化を「プログラマーだけの話」として見ていたら、日本の学術・芸術分野、ひいては社会や産業全体が、デジタル敗戦に続くAI敗戦に巻き込まれてしまう可能性もあると思う。これは、少し大げさに聞こえるかもしれない。けれども、文化や芸術や人文知は、社会の周辺にある飾りではない。私たちが何を面白がり、何を大切にし、何を未来に残したいと思うかの土台である。
もし、その領域でAIの活用が遅れれば、影響はゆっくりと、しかし深く広がっていく。生活の質、芸術、教育、研究、さらには一見無関係に見える技術や産業の世界まで、少しずつダメージを受けることになる。
その意味で、ぜひ実現してほしいのが、国立国会図書館デジタルコレクションの内容をベクトルデータ化することだ(これについては2023年1月に一度書いている)。そこには、日本の文化そのものが、生々しいかたちで蓄積されている。主要な言語モデルに読ませるべきなのだ。書店が減った、本を読まなくなったことを嘆く人がいるが同じような性格のものだと考えるべきである。これは単なるアーカイブ整備ではなく、AI空間における日本語文化の地政学にも関わる問題だと思う。
もちろん、私がこんなことを書いているあいだにも、本当に必要としている人たちは、人文科学系でもエンタメや芸術系でも、すでにどんどんAIを使っているのかもしれない。ただ、それはまだ本当に一部に見える。
あなたの"otaku"属性は診断テスト
今回の記事で紹介したメディアスタック・クロノロジーのためのソフトウェアXnative/Timelineを応用した「あなたの"otaku"属性は診断テスト」のやり方は以下のとおり。
以下からお試し可能です(予告なくサービスを休止することがあります)。
https://xnativecfr-production.up.railway.app/?owner=hortense667&repo=xnative&testid=zutest01&mode=2
Xnative/Timelineに関してはこちらをご覧ください。
https://github.com/hortense667/Xnative
遠藤 諭(えんどうさとし)

角川アスキー総合研究所リサーチパートナー、MITテクノロジーレビュー日本版アドバイザー、ZEN大学客員教授、ZEN大学 コンテンツ産業史アーカイブ研究センター研究員。プログラマを経て1985年に株式会社アスキー入社。月刊アスキー編集長、株式会社アスキー取締役、株式会社角川アスキー総合研究所取締役などを経て、2025年より現職。雑誌編集長時代は、ミリオンセラーとなった『マーフィーの法則』など書籍も手がけた。著書に、『計算機屋かく戦えり』、『近代プログラマの夕』(ともにアスキー)など。
X:@hortense667
Bluesky:https://bsky.app/profile/hortense667.bsky.social
mixi2:@hortense667
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第208回
プログラミング+
“合成音声”はかくも機械的なのに心を揺さぶるのか? -
第207回
プログラミング+
秋葉原は「アキバノハラ」だったのか、「アキハノハラ」だったのか? -
第206回
プログラミング+
“宿題でAIを使いはじめる前”に、“AI的ゾンビ”(a-zombie)にならないための方法 -
第205回
プログラミング+
「電脳秘宝館・マイコン展」──Intel 4004“ナゾ基板”の正体と、日本最初の野球ビデオゲーム「ラスト・イニング」 -
第204回
プログラミング+
Geminiにタイ移住を命じられた――100日チャレンジからAI駆動生活へ、大塚あみさんインタビュー -
第203回
プログラミング+
「DGX Spark」は現代の「Apple II」である -
第202回
プログラミング+
マイコン誕生50周年の最後に「Apple 1」と『Yoのけそうぶみ』がやって来た! -
第201回
プログラミング+
秋葉原・万世書房と薄い本のお話 -
第200回
プログラミング+
11/2(日)ガジェットフリマと豪華ゲストによる変態ガジェットアワードが東京ポートシティ竹芝で開催 -
第199回
プログラミング+
現役“中学生”によって「変態ガジェットプロジェクト」が始動!! - この連載の一覧へ




















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")
















