




今回はLightmatter社のインターコネクトについてだ。Lightmatterは連載676回で光ベースのAIアクセラレーターであるEnviseを開発しているメーカーとして紹介しており、この際にそのEnviseを複数接続するためのバックプレーンとしてPassageの話も合わせて簡単に説明した。
Lightmatterのウェブサイトを見ると、製品はM1000とL200であり、Enviseは? というと(URLこそproductsページの下だが)Researchの下に移動している。そのEnvise用のプログラミング環境であるIDIOMも同様の扱いだ。
そんなLightmatterであるが、Hot InterconnectsではCEOであるNicholas Harris博士による基調講演とTaylor Groves博士(Principal Solution Architect)らによる"Accelerating Frontier MoE Training with 3D Integrated Optics"という発表に加え、Hot Chips 2025でも Darius Bunandar博士(Chief Scientist)による"Passage M1000: 3D photonic interposer for AI"という発表をしている。
Hot Interconnectsに関して言えば同社はダイヤモンド・スポンサーにもなっており、とにかくPassageをまず商品として売りたいという物すごく強い意志(というか、強い圧)を感じたのは同社のスポンサー筋の圧力? と思ったりするが、そういう事情はともかくとして3つも講演が行なわれたので、これをまとめてPassage M1000について説明したい。
プロセッサーではなくインターコネクトがボトルネックになる
まずHarris CEOによる概略から。AIの進展にともない、計算能力は順調に増加しているが、インターコネクトがこれに追い付いていないとする。
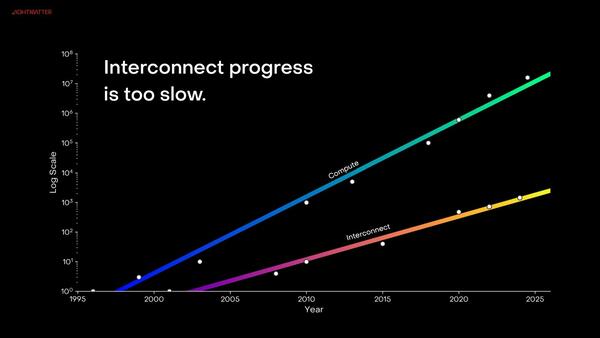
結局今のところGPUにしてもAIプロセッサーにしても単独で動作する程度では性能が全然足りないので、膨大な数のチップをつなぐ必要があり、このインターコネクトがボトルネックであるとする
ただこれは構造的な問題でもある。構造的、というのは仮に光で通信しても、CPO的な実装だと帯域はやはりチップ周辺の長さに比例することに変わりはないからだ。
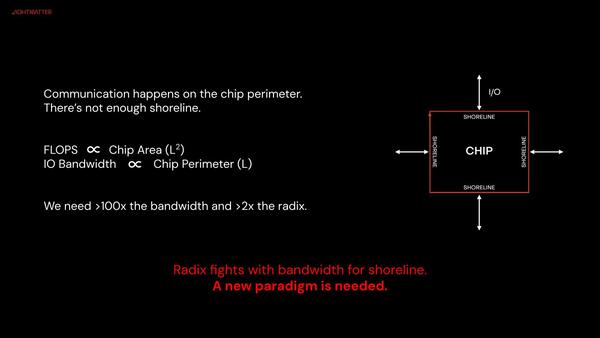
I/Oはチップの周辺に配されるから、I/Oの数はチップ周囲の長さに比例する。一方で計算能力はチップの面積に比例するから、どうやっても足りなくなる。ここでいうLはチップの長さ(縦でも横でもよいが)であり、現時点でも100倍くらいのギャップがある
冒頭のグラフのとおり、インターコネクトの性能を100倍にできれば、ギャップはいくぶんなりとも小さくなる(この話は後述)。そのための方法がフォトニクスであるというのはLightmatterの生い立ちを考えれば明白なのだが、このための方法が4世代あり、同社はすでに第3・4世代のソリューションを用意しているというのが今回のメッセージである。
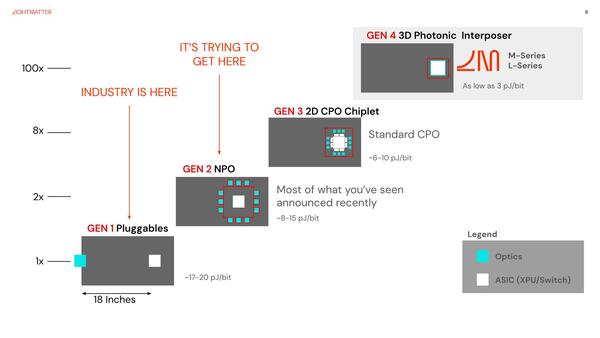
NPOはNear Package Optics、CPOはCo-Packaged Opticsの略である。すでにBroadcomなどはCPOを現実に実装しているので、もう第3世代まではかなり現実に近い
世代ごとに実装の方法が異なり、その性能差は消費電力の差という形で示されている。現在のデータセンターの課題は莫大な消費電力であり、通信に関しても「性能を落とさずに」消費電力を下げることが至上命題である。17~20pJ/bitから3pJ/bitまで下げられれば、その効果は非常に大きいわけだ。
ではどのうようにそれを実現したのかだが、先に書いた第3世代がPassage L-Series、第4世代がPassage M-Seriesであり、今回はPassage M-Seriesとして最初に製品化されるPassage M-1000についての説明があった。

最初はEnvise向けにPassage M-Seriesを開発しており、途中から方針が変わったことで、従来型のASICにチップレットの形で利用できるソリューションも必要になり、これをPassage L-Seriesとして追加した関係で、L-Seriesの方が提供は後送りになっている
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")



















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












