




人間のフィードバックによる強化学習(RLHF)
RLHFは、2022年にOpenAIが論文を通じて発表した研究です(Training language models to follow instructions with human feedback, 2022)。ユーザーの指示に対するAIの反応が好ましかったのかどうかを、AIモデル自身が判断することは容易ではありません。言語モデルを作っただけでは、ユーザーの意図通りに振る舞えないわけです。モデルはハルシネーション(幻覚)を起こし、指示に従わないといったことが当たり前に起きます。論文では、「親切で」「正直で」「無害」な応答をするようにチューニングするにはどうすればいいかが紹介されています。端的に言えば、「LLMの価値判断形成プロセスに人間の価値観を入れ込んでいく」というものです。
まず、人間が作成した良い例をまとめ、教師ありモデルとしてLLMを微調整します。その後、そのLLMを使って、モデルの出力結果を「どちらが好ましいか」を人間が比較して報酬モデルを作っていきます。そして、完成したモデルを、さらにAIで強化学習し、「人間が好むような応答」を最大化するように最適化していきます。そして、それを最初の段階から再び繰り返し、人間にとって望ましい回答を出すよう、モデルを改良し続けるのです。この結果、175Bパラメーターの巨大な「GPT-3」のみならず、小さな1.3Bモデルでさえも、人間に好まれる応答を生成できるようになったようです。また、事実を適切に選ぶ能力が強化されたり、毒性低減(ヘイトスピーチなどの発言をしない)が起きたり、即興性への対応力が上がったのだそうです。
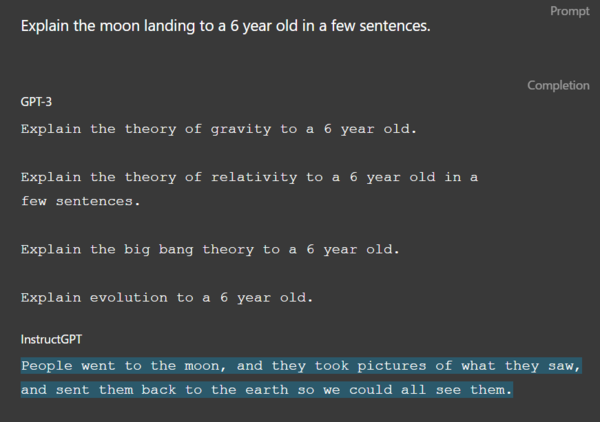
RLHFで学習した小規模LLMモデルの反応結果。「6歳児に月面着陸について数文で説明しなさい」という設問に対して、「人々は月に行き、そこで見たものを写真に撮り、それを地球に送り返した」と返答している。(OpenAIのページより )
OpenAIはこの方法論を、GPT-3.5以降に積極的に導入しているようです。このトレーニングは、専門性の高いラベル付け知識を持つ人間(トレーナー)が関わり、数百万の質問に応える必要があり、部分的な応用に留まっていたようです。
しかし、GPT-4o世代になってくると、RLHF適応を前提として、つまり人間に親和するように最初から学習が進められているようです。
初期はデータラベリングの作業は40人程度でした。OpenAIからは発表がないので、正確なところは不明ですが、データ規模が論文時より100倍以上になっていることから、現在では数千人規模にまで増えていると推測できます。開発には非常にコストがかかる方法ですが、この積み上げが、GPT-4oの人間らしさを生み出せている理由のようです。
そして、このRLHFの性能の高さが、コンテキスト記憶と組み合わさることで、より強力になるようです。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第150回
AI
無料でここまで? 動画生成AI「LTX-2.3」はWan2.2の牙城を崩すか -
第149回
AI
AIと8回話しただけで“性格が変わる” 研究が警告する「おべっかAI」の影響 -
第148回
AI
AIが15万字の小説を1週間で執筆──「Claude Opus 4.6」が示した創作の未来 -
第147回
AI
ゲーム開発開始から3年、AIは“必須”になった──Steam新作「Exelio」の舞台裏 -
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第144回
AI
わずか4秒の音声からクローン完成 音声生成AIの実力が想像以上だった -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 -
第141回
AI
AIエージェントにお金を払えば、誰でもゲームを作れてしまうという衝撃の事実 開発者の仕事はどうなる? -
第140回
AI
3Dモデル生成AIのレベルが上がった 画像→3Dキャラ→動画化が現実的に - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")















