



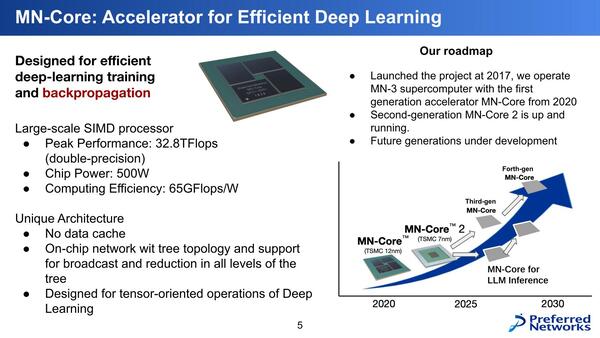
ロードマップでわかる!当世プロセッサー事情 第798回
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
2024年11月18日 12時00分更新

NVIDIA A100より高性能で
価格は約半分のMN-Core 2
前置きが長くなったが、ここまでは初代MN-Coreの話で、ここからがHot Chipsで説明のあったMN-Core 2の話である。下の画像が初代MN-Coreのまとめであるが、MN-Core 2の次には推論向けと学習向けで異なるラインナップを用意するという話が出ている。
考えてみれば4ダイで500Wなので、1ダイあたりでは125Wであり、法外なほど高い消費電力とは言えないかもしれない。それでも大きめだが
第2世代のMN-Core 2であるが、目標は高い性能/消費電力比を維持しながらコストを下げることにあるとする。
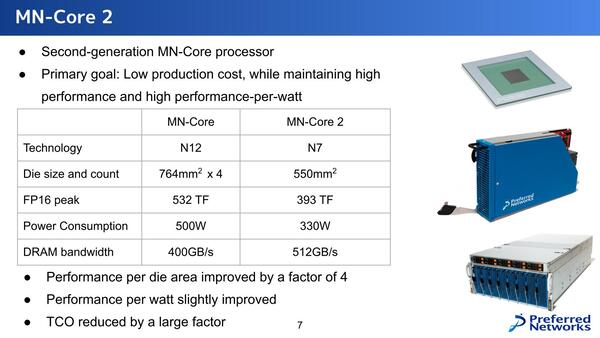
MN-Core 2はダイの数が1つになっており、トータルのL2Bの数は半減している。ただし動作周波数を引き上げているので、性能はそこまで落ちない
MN-CoreとMN-Core 2の違いは下の画像のとおりで、MN-Core2ではダイあたりのL2Bの数が8つに増えている。とはいえMN-Coreでは4ダイで16個だったから演算器そのもので言えば半減である。

MN-CoreとMN-Core 2の違い
しかしMN-Coreでは500MHz駆動だったのが、MN-Core 2では750MHzと1.5倍になっている関係で、性能はMN-Coreの75%ほどに落ち着いている。実際性能が393TFlops vs 532TFlopsで73.9%ほどに収束しているから、ほぼ計算通りと言える。
細かいところでは、例えばメモリーの搭載量は半減しているが、演算器の数も半分なので実質変わりはないし、むしろLPDDR4→GDDR6Xで高速化されているから、メモリーアクセスのレイテンシーを減らせて性能を上げやすくなっているともいえる。
性能として示されたものが下の画像である。アプリケーションによって差の開き方がだいぶ変わるのだが、ResNet-50の学習で2倍、推論で4倍というのはわりと大きな差だし、姫野ベンチマークでは14倍以上の差がついているのがわかる。姫野ベンチマークについては理研のウェブサイトを参照してもらいたい。メモリー依存度が非常に高いベンチマークである。
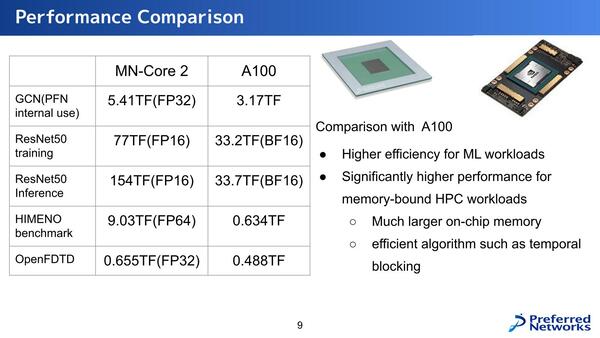
MN-Core 2の性能。比較がA100のままでいいのか? というのはやや疑問ではある
問題はLLMに利用するにはあまりにメモリーが足りなさすぎることだ。今年9月にCloud Operator Days 2024というイベントがあり、そのクロージングでPreferred Networksが「自社開発した大規模言語モデルをどうプロダクションに乗せて運用していくか~インフラ編~」という発表をしているのだが、この中でモデルが巨大すぎ、かつCUDAが必須なので現実問題としてNVIDIAのGPUを使うしかなく、しかもH100/H200は全然入手できないのでA100の利用が現実的、という話をされている。
その意味ではMN-Core 2の性能をA100と比較するのは間違っていないのかもしれない。ただ現実問題として16GBのMN-Core 2では大規模LLMが乗り切らないので、ホストメモリーを併用することになるが、こんなことをしたらまともに性能が出るはずもない。
またCUDAで書かれたコードをMN-Core向けに書き直すのも猛烈に大変である。したがって、今のところMN-Core 2をLLMに使うという話が見あたらないのが、現時点での最大の問題かもしれない。
などと考えていたら、11月15日にPreferred NetworksよりMN-Core L1000の開発に関する発表があった。DRAMをチップの上に3次元実装することで、LLMに必要となる大量のメモリーをHBMよりも安価かつ高速に実現できる、という目論見だそうだ。登場時期は2026年の予定となっている。

MN-Core L1000。実はSamsungが一時期、HBMを直接チップの上に積層する技術を開発していたはずなのだが、その後話がどこかに行ってしまった。このDRAM積層がそれと同じものなのか、あるいは別のものかは不明だが、いったいメモリーは誰が主体となって開発しているのだろうか?
話を戻すと、すでにMN-Core 2は発売されており、MN-Core 2を8枚搭載するMN-Server 2 V1が2000万円、1枚搭載のMN-Core 2 Devkitが200万円となっている。おそらくMN-Core 2のカード単価で言えば150万~160万円程度。昨今の為替レートを考えると1万ドル前後というあたりで、ラフに言ってA100の半額、インテルのGAUDI 2よりややお高めといったところだろう。

MN-Server 2 V1はXeon Platinum 8480+×2に1TBメモリーを組み合わせたラックサーバー構成、MN-Core 2 DevkitはCore i5-14500に64GBメモリーという構成だ
次世代製品については、学習向けではピーク性能10倍とアプリケーション性能30倍、推論向けは性能20倍としている。それはいいのだが、学習向けがSamsungのSF2というあたりに一抹の不安を覚えざるを得ない。ちゃんと製品が作れるのだろうか?
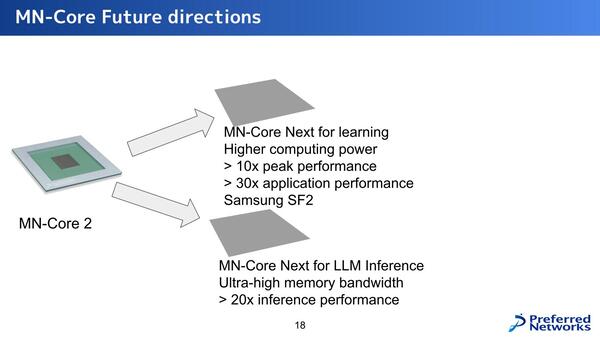
推論向けはLLM Inferenceとあるのに、学習向けにLLMの文字がないあたりも気になる。LLMの学習はとにかくメモリーが鬼のように必要なので、あるいはマーケットとして捨てている可能性もある
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ














で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")










































