




AIで「三面図」を出し、衣装のバリエーションを作る
東京ゲームショウ時の取材で見せたのは、その新しく試していた手法です。ゲームのヒロイン向けに追加の衣装を作ろうという話が出ており、新たにデザインを起こす必要が生まれました。ちょうど8月に登場した画像生成AI「FLUX.1」の性能が高く、デザイン的に一貫性を保ったままいきなり三面図を作成できることがわかったので試し始めたのです。
ディレクターからは「チャイナドレス風衣装は作れないか。物理オブジェクトがついている、ヒラヒラしているような」というオーダーがあったんです。またしても「なんやそれ……」という感じだったんですが(笑)。
まず、Midjourneyのアニメ系画像生成AIサービスの「Nijijourney」を使い、ヒラヒラしたチャイナドレス風衣装を着たキャラクターのバリエーションを大量に作りました。バリエーションを作る「Vary」の機能を使うことで、一度出た画像のバリエーションを出すことは簡単で、また生成にかかる時間もカエルの頃よりも格段に早くなっています。

Nijijouneyを使って作成したチャイナドレス風衣装の一部
次に、出てきた画像を選別し、30枚のセットにしてFLUX向けのLoRAを開発しました。LoRA作成ツールは「FluxGym」を使います。ポイントは三面図を出力することが目標であるため、そのなかに後ろ姿の画像も含めておくという点です。それにより、背面の出力も適切にできる可能性を高めることができます。
そして、ヒロインキャラクターの3Dモデルのスクリーンショットを用意し、Flux.1が動作するWebUI Forgeの環境で、LoRAと組み合わせてImage-to-Image(i2i)で生成します。これによって、様々な服装をした女性の三面図のバリエーションが、30秒に1枚くらいのペースで出せるようになりました。ControlNetを使ったほうが望ましい一貫性を作成できる可能性があるのですが、まだForgeではその環境が登場していないために、i2iで作成しています。
生成される画像は完璧ではなく、前後を取り違えたり、デザインが破綻していたりと完全な一貫性を担保できていないものも少なくないのですが、まずは十分です。
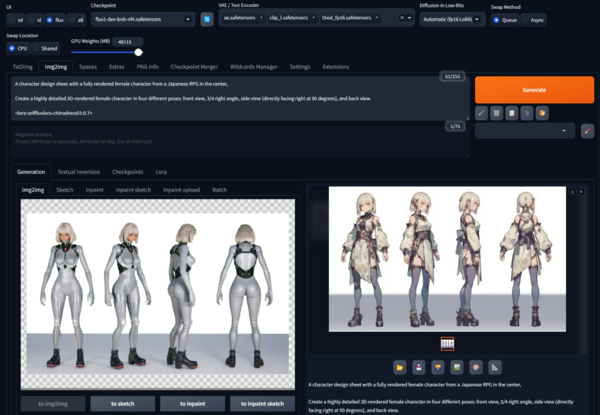
WebUI Forgeのi2iの画面。左側にヒロインモデルの三面図の元となるスクショを配置し、そのポーズを参考に、生成された画像が出力される

衣装の生成結果の一部。プロンプトの変更やLoRAの強度を変えることで、様々なバリエーションを生み出せる

生成した画像の一枚。アイデア出し段階なので、一定の整合性があれば、完全でなくても問題ない
ここで出された三面図のなかから、どんなコンセプトを狙っていくのかという絞り込みを進めています。カエルの時よりも、精度が高い画像をより速く出せるようになっています。参考にできる画像が出てくると、ディレクターのイメージも膨らむもので、「若干SF的な意匠を盛り込んでほしい」などの追加注文が出てきます。それらを他の自作LoRAなどと組み合わせたり、レタッチ作業をして情報を整理しながら、精度を上げていきます。そして、まだ最終的な完成には至っていないのですが、最後は人間の手でデザインをまとめ上げていくことになります。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第165回
AI
AIがBlenderを勝手に操作 3D制作のハードルが一気に下がった -
第165回
AI
社内WebサービスをAIで開発 完成後に直面した運用の壁 -
第164回
AI
AIはすでに、私たちの心を内部で再現しているのかもしれない -
第163回
AI
無料の画像生成AI「Krea 2」が話題 実写もアニメもこなす新勢力 -
第162回
AI
ローカルAIで“しゃべる推理ゲーム”を作ったら、思ったよりちゃんとゲームになってきた -
第161回
AI
わずか3日で停止された新AI「Claude Fable 5」は何がすごかったのか -
第160回
AI
寝不足になるほど面白い ローカルAIと音声合成をつないだら、キャラが普通にしゃべり始めた -
第159回
AI
AIを使える人と使えない人で、とんでもない差が出ると実感した理由 -
第158回
AI
SDXLの次はこれ? アニメ特化のローカル画像生成AI、驚きの実力 -
第157回
AI
AIだけでゲームは作れるのか? Codexに7本作らせて見えた実力と限界 -
第156回
AI
ChatGPTの画像生成AIは本当に最強か Nano Bananaと比べて見えた“弱点” - この連載の一覧へ











、バッテリー駆動時間は13時間超え。もう欲しくなる要素しか見つからないッ!")








ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")



