



GKEなどのGoogle Cloudサービスを用いた負荷軽減と運用効率化のノウハウを披露
「あれ、サーバー代で倒産する…?」大ヒットゲーム・パルワールドが語る、安価で堅牢なインフラ構築
2024年08月14日 08時00分更新

Google Cloudは、2024年8月1日と2日、同社の最新ソリューションや活用事例を紹介する年次イベント「Google Cloud Next Tokyo ‘24」をパシフィコ横浜で開催した。150社を超えるユーザー企業やパートナーのセッションが展開された。
本記事では、「パルワールドのインフラ最前線」と題したポケットペアのセッションをレポートする。登壇したのは、ゲーム開発事業部の中條博斗氏、西北尚史氏、笹和成氏の3名。発売から6日足らずで800万本を売り上げ、ピーク時の同時接続数は210万人にも達したパルワールドを支えるインフラの裏側について語られた。

不思議な生き物「パル」が暮らす世界である「パルワールド」
月のサーバー代予測が“7053万円”!? 人気が爆発したパルワールドの裏側では……
パルワールド(Palworld)は、広大な世界で不思議な生物「パル」を集め、戦闘や建築、農業などをしながら冒険を繰り広げるオープンワールドサバイバルクラフトゲームだ。SteamやXbox Game Pass、Xbox Series X/S、Xbox Oneといったゲームプラットフォームで提供されている。
2024年1月19日にリリースされ、総プレイヤー数は2500万人、Steamでの同時接続数は210万人を突破するなど、まさに爆発的な人気を博した。ただし、開発したポケットペアは数十名ほどの小さなゲーム開発会社。中條氏も「この規模のヒットは全く予想していなかった」と驚きを込めて振り返る。

ポケットペア ゲーム開発事業部 リードネットワークエンジニア 中條博斗氏
同社社長の溝部拓郎氏がXでつぶやいた「あれ、ひょっとしてサーバー代で倒産する?」というポストも話題になった。
リリース直後の開発チームは、品質向上を目指すべくアップデートに取り組んでいたが、アクセス数が予想外の急増。サービスを落とさないよう急遽サーバー台数を増やして対応した結果、今度はサーバーコストの予測額が「月7053万円」にふくれあがった。
もちろんそんなサーバー代を支払うわけにはいかないため、「最適化を図ってはるかに少ない費用で乗り切った」と中條氏。リリース当時の運用体制は中條氏のワンオペだったが、現在は運用メンバーも増え、アーキテクチャも変更して、安価かつ堅牢なインフラを構築している。
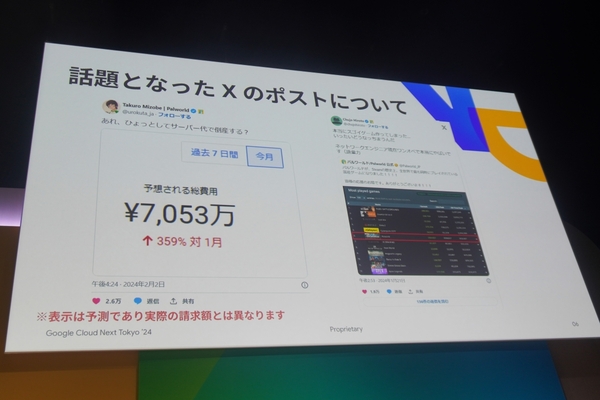
「あれ、ひょっとしてサーバー代で倒産する?」 Xのポストも話題に
セッションでは、「Google Kubernetes Engine(GKE)」を始めとするGoogle Cloudのサービスを活用した、各種サーバーの負荷軽減や運用効率化の取り組みが披露された。
APIサーバー:Cloud SpannerやCloud CDNを採用して負荷軽減
パルワールドのAPIサーバーは、公式サーバーやコミュニティサーバー(後述)を閲覧・検索するための「ゲームサーバーの一覧」機能、チャットメッセージやプレイヤー名に含まれる不適切なテキストをマスクする「テキストフィルター」機能を提供している。
パルワールドは、知り合いや他のプレイヤー(フレンド)と一緒に冒険できるマルチプレイを特徴としている。このマルチプレイには2つの方式がある。招待を受けた知り合いのPCに直接インターネット接続して参加する“P2P方式”と、ポケットペアの公式サーバーもしくはプレイヤーが運用するサーバーに接続して参加する“専用サーバー方式”だ。
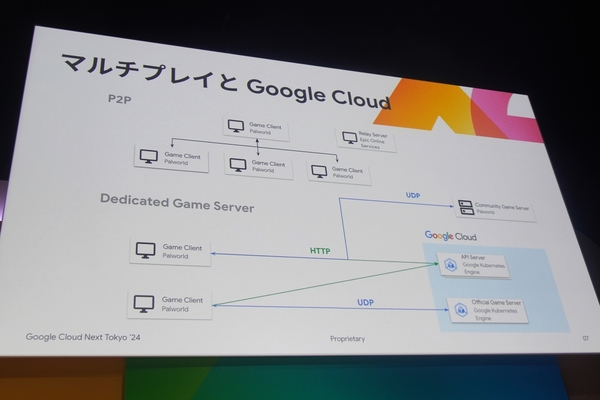
マルチプレイのアーキテクチャー(P2P方式、専用サーバー方式)
専用サーバー方式の場合、最大32人のマルチプレイが楽しめる。また、プレイヤーが専用サーバーを立てることで、サーバー独自のルールを設定することができる。この専用サーバーを他のプレイヤーにも広く公開しているのが「コミュニティサーバー」で、現在では数万台のコミュニティサーバーが登録されているという。
前述のとおり、APIサーバーは接続先となる公式サーバーやコミュニティサーバーの情報を提供する。APIサーバーへの通信はHTTPを使用しており、アプリケーション自体はGo言語で実装。さらに、GKE上で動作させることで、水平方向へのスケーラビリティを確保している。
「コンテンツアップデートなどに伴うアクティブユーザー数によって、サーバー負荷も激しく変動する。GKEのオートスケーリングによって自動対応し、面倒を見る必要がほとんどない」(西北氏)

ポケットペア ゲーム開発事業部 リードインフラエンジニア 西北尚史氏
APIサーバー全体のアーキテクチャーは、GKEを中心に据えて「Cloud CDN」や「Cloud Load Balancing」などで構成している。
公式サーバーやコミュニティサーバーの情報は、分散型データベースである「Cloud Spanner(以下Spanner)」で管理しており、テキストフィルターについては、結果をキャッシュして高速化するために、インメモリデータストアである「Memorystore for Redis」を使用している。

APIサーバーのアーキテクチャー
実は、当初はサーバー情報の保持についても、SpannerではなくMemorystore for Redisで検討を進めていたという。
検討時点での性能要件は「最大30万サーバー、1万クエリ/秒程度のリクエスト負荷に耐えられること」というものであり、Memorystore for Redisで十分対応できると考えていた。また、更新のないサーバーをリストから自動削除するうえでは、TTL(Time To Live)機能を備えたMemorystore for Redisが適しているという判断もあった。
しかし、負荷試験を実施すると、大量のサーバー情報更新と検索が同時に発生する処理にMemorystore for Redisでは耐えられなかった。そこで、より高いパフォーマンスが望めるSpannerへと切り替えたが、Spannerが標準で備えるTTL機能では求める機能を実現できず、時間経過によるサーバー情報の削除処理は自前で実装することになった。

Spannerを選択した理由
Spannerを採用するうえで、もうひとつ工夫が必要だったのがデータベースへのアクセス方法だという。選択肢は2つあり、ひとつはPostgreSQLサーバーを仲介役(プロキシ)としてSpannerにアクセスする「PGAdapter」を使う方法、もうひとつは各種ライブラリでSpannerのドライバーを使用して「Google Standard SQL」を実行する方法だ。
当初は、PostgreSQLとの互換性が保てるPGAdapterを採用して、PostgreSQL向けに書かれた既存のクエリを実行していたが、PGAdapterのCPU負荷がAPIサーバーの5倍にも達するようになってしまった。そこで、Spannerをネイティブで動かすGoogle Standard SQLへの移行を決断した。
「データベース周りの実装変更というと苦い経験をされた方も多いかもしれないが、API自体が複雑ではなかったこと、ライブラリ実装が充実していたことから、比較的容易に変更できた。結果としてPGAdapterのオーバーヘッドがなくなり、パフォーマンスが劇的に向上したほか、スケーリングの設定も容易になり、リソース効率で大きな成果が得られた」(西北氏)

PostgreSQL互換 or Google Standard SQLの選択
その他にも、APIサーバーとSpannerの負荷軽減のために、Cloud CDNでサーバー一覧や検索結果を対象としたキャッシュを実施している。これは、リアルタイム性が求められていないサーバー情報だからこそとれる方法であり、キャッシュヒット率はおおむね30~40%で推移するなど、一定の成果が得られているという。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



