



ロードマップでわかる!当世プロセッサー事情 第782回
Lunar LakeはNPUの動作周波数がアップし性能は2倍、ピーク性能は4倍に インテル CPUロードマップ
2024年07月29日 12時00分更新

SHAVE DSPを大幅強化
ホストで処理していた作業をNCE側でカバーする
NPUの構造に話を戻すと、MACユニットの方はより効率を高めた、という説明はあるものの、どう効率を上げたのかの詳細は説明されていない。

活性化関数の強化やデータの変換/並び替え「以外」にも効率性向上のなにかがあるらしいのだが
活性化関数に関しては、NPU 3に比べて対応する関数を増やしたことが示されており、またデータ変換用の機能も搭載され、これまでだったらSHAVE DSPもしくはホストで処理していた作業をNCE側でカバーできるようになったとしている。
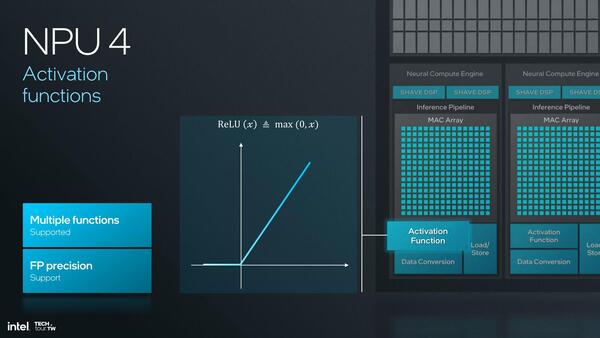
NPU 3でもFP16のサポートはあった記憶があるのだが、Activation FunctionではなくDSP側での対応だったのだろうか?
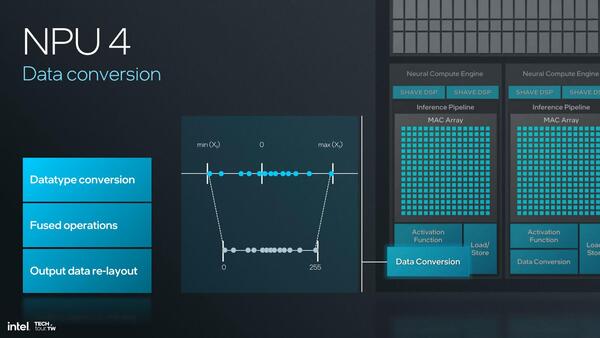
例えばFP16からINT 8への変換が今後は専用ハードウェアでできることになる。Fused Operationというあたり、MACアレイでの処理と同期するかたちで実行できるようだ
そのSHAVE DSPが、NPU 4では大幅に強化された。SHAVE DSPはもともと1つのNCEに2つ搭載されており、それぞれ128bit幅のSIMDエンジンを搭載。INT 8/16/32とFP16/32を扱えるようになっていた。

NPU 4で大幅に強化されたSHAVE DSP。レジスターもまた512bit幅になっている
もちろんこれは通常のMAC演算も可能ではあるのだが、それは専用のMACアレイを使った方が効率が良い。なので、MACアレイでサポートしていないINT 16/32やFP32での処理、あるいは通常の乗加算以外の処理を行なう場合に利用されることになる。
さてそんなSHAVE DSPだが、NPU 4ではSIMDエンジンの幅が128bit→512bitと4倍に増強された。INT 8の場合で言えば64 Ops/サイクル(MAC演算の場合:通常の乗算なり加算なりだけなら32 Ops/サイクル)が可能であり、1個のNCEあたり128Ops/サイクルとなる。
先程の性能の試算ではMACアレイだけを使う計算になっていたが、SHAVE DSPの性能が大きく上がった関係で、実際にはこちらも加味して計算をしている可能性がある。NCE1つあたりの処理性能は4352Ops/サイクルとなり、これが6つでかつ1.7GHz動作だと性能は44.4TOPSほど。1.75GHzだと45.7TOPSになり、上の試算より100MHz動作周波数を落とすことが可能になっている。
このSHAVE DSPの性能を加味したものかどうかがハッキリしないので、動作周波数は一応推定1.85GHzとするが、実際は1.75GHzとか1.8GHzの可能性もある。
さて、その46TOPS程度のNPU 4の性能は? ということでインテルから示されたのはStable Diffusionを動かした場合の結果である。
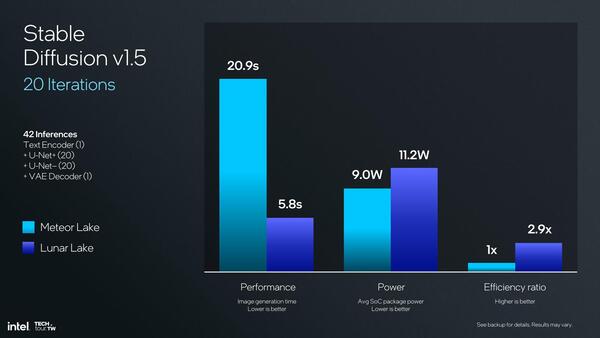
連載781回で示したとおり、Lunar LakeのXe2コアは理論上67TOPS程の性能であり、ピーク性能比較はNPUの方がやや低い結果になることそのものは変わらない
Meteor Lakeの時もStable Diffusionを実施した場合の性能が示されたが、この時は比較対象がなかったこともあり、CPUでやった場合とGPUでやった場合、NPUを組み合わせた場合の4パターンでの比較である。
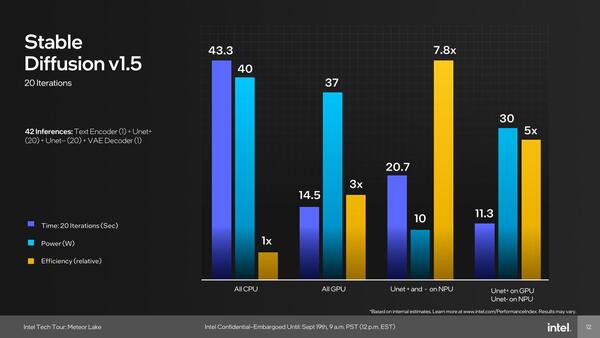
Meteor LakeでStable Diffusionを実施した場合の性能
結果は連載740回の最後にも示したとおり、NPU 3を利用した場合の性能はGPUを利用した場合の7割程度に過ぎず、ただし消費電力が圧倒的に少ないというものだった。
一方今回はMeteor LakeとLunar Lakeとの比較になるので、直接前回との比較にはならないのだが、まず性能で言えば20回の繰り返しに要した時間が20.9秒→5.8秒で3.6倍の性能向上となっている。一方でシステム全体での消費電力は9W→11.2Wと若干ではあるが増えているのは当然ではある。
先に説明したように、NPU 4はNPU 3と比較してピークで4倍の性能になっているが、その一方でピーク時の消費電力は推定で2.58倍ほどになっている。実際はシステムの構成もメモリーの構成も異なるから無茶な計算ではあるのだが、この2.2Wの増分がNPU 3とNPU 4の消費電力の差だと仮定すると、NPU 3の消費電力は1.4W程度であり、NPU 4ではこれが3.6W程に増えたことになる。
この数字、厳密さには欠けるものではあるのだが、案外に外していないのではないかと思う。Meteor Lakeでは省電力のSoCタイルで実装され、省電力に注力した構成になっている。NPU 2、つまりMyriad Xの場合は当初TSMCの16nm、次いで12nmに移行しているが、これが大体3W程度であった。NPU 3ではプロセスの微細化と省電力プロセスの採用もあり、2W以下に押し込むことは可能だろう(Myriad X VPUに搭載されていたISPを省けたことも効果あると思われる)。
一方NPU 4の方は、1.8GHz前後の動作周波数ではあるが、これはTSMC N3Bプロセスとしてはかなり低い動作周波数レンジであり、消費電力もそれほど高くならない。3.6Wで収まるか? というともう少し行きそうな気はするが、5Wまでは行かないだろう。
ピーク性能はもちろんXe2コアには及ばないだろうが、この程度の消費電力でこの性能なのは十分評価できる。総じて、良いバランスのNPUと言って良いだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























