





Google DeepMindは6月17日、動画のピクセルデータから音声を自動生成する技術「Video-to-Audio(V2A)」を発表した。この技術により無音の生成AI動画に自然な音声、音楽、効果音、セリフを追加することが可能になる。
動画の内容を直接解析して音声を生成
V2Aは動画の内容(ピクセルデータ)を直接解析し、動きやタイミングに合わせて適切な音声をリアルタイムで自然に同期させることが可能だ。
プロンプトは「Cinematic, thriller, horror film, music, tension, ambience, footsteps on concrete(シネマティック、スリラー、ホラー映画、音楽、緊張感、アンビエンス、コンクリートの足音)」
プロンプトは「A drummer on a stage at a concert surrounded by flashing lights and a cheering crowd(照明と歓声に包まれたコンサートのステージに立つドラマー)」
どちらも動画はグーグルの動画生成AIモデル「Veo」で作成され、そこにV2Aが動画の内容にぴったりなBGMや効果音を加えている。
動画+ポジティブ/ネガティブプロンプトから音声を生成
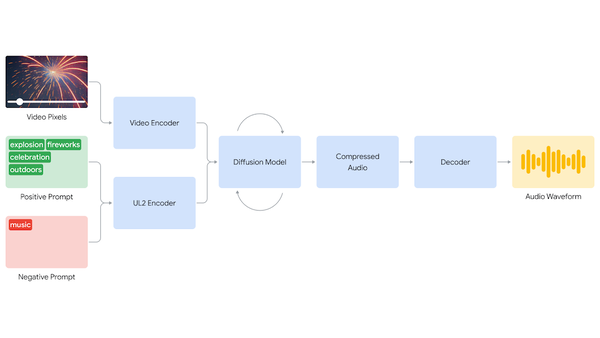
V2Aモデルは高品質な音声を生成し、特定の音を発生させる能力を得るため、「音声の詳細な説明が付与されたAI生成のアノテーション」「発話対話の書き起こし」などの追加情報を付加した動画、音声データでトレーニングされている。
動画と(ポジティブ/ネガティブ)プロンプトを入力すると、モデルはそれらを圧縮された表現にエンコードし、その後拡散(Diffusion)モデルが動画情報とプロンプトに導かれ、ランダムなノイズから徐々にオーディオを生成していく。最後に、オーディオ出力がデコードされオーディオ波形に変換された上でビデオデータと組み合わされる。
リップシンクは動画生成モデル次第
ただし現時点ではいくつかの問題点が明らかになっている。
オーディオ出力の品質はビデオ入力の品質に依存するため、入力する動画の質が悪いとオーディオ品質が著しく低下することがあるという。
また、セリフがある動画の場合、トランスクリプト(台本)をプロンプトとして入力すると、V2Aモデルはキャラクターの口の動きに同期させようとする(リップシンク)が、使用する動画生成モデルがトランスクリプトに対応していない場合、ビデオと音声の間で不一致が生じることがあるという。
本記事はアフィリエイトプログラムによる収益を得ている場合があります





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















