





AIスタートアップのストックマークは5月16日、ハルシネーションを大幅に抑止した1000億パラメータ規模の大規模言語モデル(LLM)「Stockmark-LLM-100b」を公開した。
ハルシネーションを大幅に抑止

同モデルは、公開されている既存のモデルを用いずフルスクラッチで開発されており、1000億パラメーター規模のサイズは国内最大級となる。
事前学習に用いられたデータは、独自に収集したビジネスドメインの日本語データが中心となっており、日本語・ビジネスドメイン・最新の時事話題に精通しているうえ、ハルシネーション(幻覚とも呼ばれる、AIが根拠のない嘘を出力する現象)を大幅に抑止することに成功したという。
また、同モデルは商用利用可能なモデルとしてオープンソース(MIT License)で公開されており、誰でもダウンロードして利用できるようになっている。
各種ベンチマークで高性能

同社が独自に設定した、ビジネス情報や最新の時事話題に関する質問(Stockmark Business Questions)の正答率は9割を超え、特定の話題に限ればGPT-4-turboよりも大幅に精度が高いという。

また、LLMモデルの正確性、一貫性、流暢性の評価で活用される「VicunaQA Benchmark」ベンチマークにおいても、GPT-4には敵わないものの、「Llama2 70B」「GPT-3.5」よりも高い評価を獲得している。
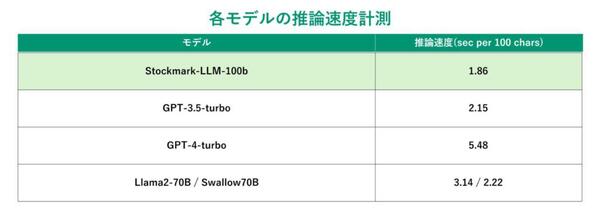
さらに、100文字の日本語を生成するのに要した時間を計測したところ、1.86秒と他の海外製モデルと比較して高い日本語速度性能を有している。
なお、同事業は経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が主催する、国内の生成AI開発力強化を目的としたプロジェクト「GENIAC」の採択を受け、国立研究開発法人産業技術総合研究所との共同研究の一環として実施されている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















