



Google CloudやNEC、シナモン、Boxの語る取り組みとチャレンジ
生成AIにより企業に眠る非構造化データをどう有効活用していくか
2024年02月13日 08時00分更新

シナモン:ドキュメント解析エンジンによる“Super RAG”でハルシネーション低減に取り組む
3番手として登壇したのは、AIソリューションを手掛けるベンチャー企業、シナモンの代表取締役 Co-CEOである平野未来氏。LLMを開発するGoogleやNECと異なり、同社は生成AIの周辺技術を展開している。

シナモン 代表取締役 Co-CEO 平野未来氏
平野氏はまず、「これまで、さまざまな企業が業務効率化や自動化を進めてきたが、途中で頓挫してしまう企業が多かったのではないか」と投げかける。その理由を平野氏は、AI-OCRを利用するにも座標定義をしなければならず、チャットボットを構築するにも莫大なQAシナリオを定義しなければならないなど、自動化自体にコストがかかっていたと指摘する。
このような“手動(手作業)”での自動化は今後変わり、「自動化の自動化」が進んでいくと平野氏。シナモンは非構造のドキュメントを理解する「ドキュメント解析エンジン」を開発。LLMと組み合わさることで、多くのプロセスが自動化され「自動化の自動化」が実現できるという。
シナモンのドキュメント解析技術は、生成AIのRAGの強化においても発揮される。前述のグラウンディングも含む一般的なRAGは、LLMの知識を補うために外部知識リソースをコンテキストとして与え、回答の質を向上させるものだが、実際は精度40%程度に着地することがほとんどだという。
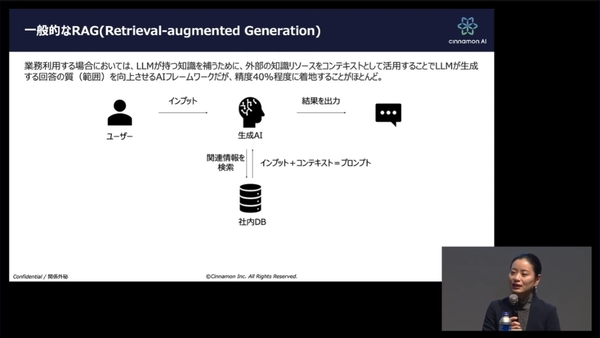
一般的なRAG
RAGの抱える文章の複雑性やドメイン知識の不足、あいまいなプロンプトによる精度低下という課題を解決するのが、同社が取り組む“Super RAG”だ。ドキュメント解析やナレッジ注入、プロンプトの自動作成おける独自技術により、RAGの仕組みで40%程度の精度であったタスクでも、90%超の精度を実現するという。
シナモンはSuper RAGにより、ドキュメントから必要な情報を抽出して回答する照会対応、技術文章を検索してレコメンドするナレッジマネジメント、OCRで読み込んだ手書きの文章をLLMと連携させる「ぜんぶよむもん」などを手掛けている。

シナモンが取り組むSuper RAG
今後シナモンが注力するのは、どの情報をプロンプトの一部として与えるかを工夫することで更にハルシネーションを低減させることだ。また、回答がどういう情報で生成されたのか、ドキュメントの参照箇所が分かるような仕組みの構築にも取り組んでいる。

生成AIの参照元をハイライトで表示するような仕組み
平野氏は最後にとある保険会社の事例を紹介。同事例でシナモンは、有無責判定業務、つまり事故があった際などに保険金を支払うか、いくら支払うかの判定を、AIが支援する仕組みを構築した。
同事例のAIの学習データは、約款や社内マニュアル、過去の判定結果などを用いたが、当初は60%ぐらいの精度しかなかったという。原因を調べたところ、人間による過去の判定結果自体がぶれていたことが判明。最終的には、AIだけではなくドキュメント側も改善し、効率化だけではなく業務自体を根本から変革できたという。今後、AI活用をきっかけに、基となるコンテンツの在り方を見直す企業も出てくるだろう。

保険会社の生成AI活用の事例
Box:生成AIの価値を最大化するコンテンツの一元管理の重要性を訴求
最後に登壇したのは、Box Japanのエバンジェリストである浅見顕祐氏。Boxは、同社プラットフォームにシームレスに生成AIを組み込んだ「Box AI」のベータ版を2023年12月より順次展開している。

Box Japan プロダクトマーケティング部 エバンジェリスト 浅見顕祐氏
現在、社内データを活用するために、業務用ChatGPTで検索をするという事例が一大ムーブメントになっていると浅見氏。その理由として、デジタル化は進んだものの、かつてバラバラだった社内のコンテンツは、Microsoft 365といった生産性ツールやクラウドストレージ、クラウド化された基幹業務システムなどに分散されたまま。どこに何の情報があるか分からないという課題が、依然解消されていないからだと浅見氏は分析する。
また、権限管理の観点でみると、バラバラなコンテンツは、セキュリティポリシーが不一致であったり、同じコンテンツが重複していたりして、生成AIでデータ活用をしようにも、どれを使ってよいのか、どこまでのアクセス権限を持たせたらよいのかは悩ましい。とはいえ、社員全員がアクセスできるデータに絞って生成AIを活用すると、就業規則GPTぐらいにしか使えない。生成AIは、情報の検索や権限管理などは向いておらず、「やっぱりコンテンツの管理をしなきゃいけない」というのを、改めて提案していると浅見氏。

生成AIは情報の検索や権限管理には向いていない
Boxが提案するのは、それぞれのアプリケーションのコンテンツをBoxに集約してコンテンツ管理の基盤を作り、欲しい情報がすべてBoxにあるという世界だ。Boxは、コンテンツのアクセス権限も一元的に管理しているため、セキュリティポリシーも統一でき、コンテンツの重複も可能な限り減らすことができる。その基盤の上で、業務用ChatGPTをはじめとした生成AIを活用する形だ。

コンテンツの一元管理で生成AIの価値を最大化
Box内でもAIアシスタント機能であるBox AIを提供しており、Enterprise Plusエディションで追加コストなしで利用できる。「Box AI for Documents」は、検索したドキュメントに対して要約や質問への回答をしてくれ、2024年に登場予定の「Box Hubs」では、複数コンテンツを横断しての生成AI活用を実現する。

Boxにシームレスに生成AIを組み込んだ「Box AI」
今後は、生成AIの機能を自社向けにカスタマイズしたいという要望に応えていく。
Box AIでは、プロンプトが投げられた後、関連箇所をドキュメントから抜き出すのにVector技術を用いて、その後、プロンプトに情報を付け足して生成AIの精度を上げている。今後登場する「Box AI API」では、これらの処理を裏側で代替してくれ、カスタムアプリの作成を支援する。この処理に特殊なナレッジを挟み込みたいという場合には、Boxが従来から備えるAPIを利用してインテグレーションも可能。開発すら不要になるよう、BoxのパートナーアプリをAI領域でも利用できるよう連携を深めていく。

カスタマイズの要望に、Box AI APIの提供やパートナー連携で応えていく
また現在LLMに関しては、プラットフォームニュートラルの方針をとっており、当初の機能はOpenAI、今後はGoogleのLLMも利用する。BYOM(Bring Your Own Model)としてユーザーが独自開発したモデルを使えるようなプランも開発中であり、NECのような日本語に強みを持つようなLLMも繋げられるよう取り組んでいる。
浅見氏は、「Boxは色々なビジネスパートナーの皆さんと組んでユーザーの声に応えていきたい」とセッションを締めくくった。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



