



「コア」と「エッジ」で構成する超分散型クラウドプラットフォームが必要な理由とは
アカマイ、「Connected Cloud」強化に向けデータセンター拠点を拡大
2023年09月15日 07時00分更新

アカマイ・テクノロジーズ(Akamai Technologies)は2023年9月13日、米国本社から上級副社長 兼 CTOのロバート・ブルモフ氏、APJ(アジア太平洋日本)統括責任者であるパリマル・パンジャ氏が来日し、現在同社が注力しているクラウド戦略と、超分散型クラウドコンピューティングプラットフォーム「Akamai Connected Cloud」について説明した。
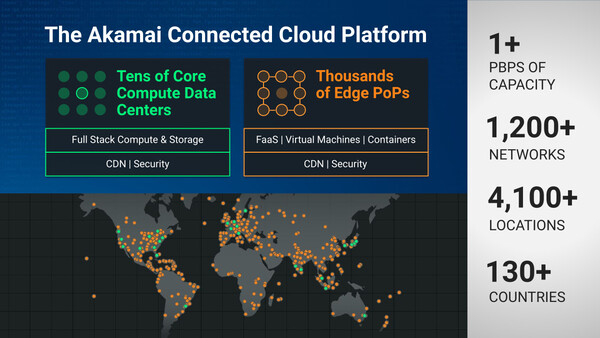
“コア”と“エッジ”で構成する超分散型のクラウドプラットフォーム「Akamai Connected Cloud」について、データセンター拠点の拡大を明らかに

米Akamai Technologies 上級副社長 兼 CTOのロバート・ブラモフ(Dr.Robert Blumofe)氏、同社 APJ(Asia Pacific Japan)Managing Director 兼 営業担当VPのパリマル・パンジャ(Parimal Pandya)氏、日本法人 マーケティング本部 プロダクト・マーケティング・マネージャーの中西一博氏
「クラウドコンピューティングビジネスには、これから大きな商機」
アカマイは今年創業25周年を迎え、APJのビジネス展開開始からも20周年となる。APJ担当のパンジャ氏によると、APJのビジネスは「過去5年間、最も速いスピードで成長を遂げている」という。
さらにパンジャ氏は、「現在のアカマイは、創業以来、最もワクワクする時期にいる。将来に向けて新しいアカマイを作っているからだ」と語る。アカマイは現在、今年2月に発表した“超分散型”のエッジ/クラウドコンピューティングサービス「Akamai Connected Cloud」に注力しており、「この領域は今後の5~10年を見据えた場合、大きなチャンスを持っている」(パンジャ氏)と見ているという。
「データがある場所にコンピュートを持って行く」超分散クラウドの戦略
続いてCTOのブラモフ氏が、アカマイのクラウドコンピューティング戦略を紹介した。ブラモフ氏はまず、クラウドコンピューティングにおいて「コア」と「エッジ」が必要になる理由を説明する。
「コンピュートの基本原則は『データを追いかけるべき』ということ。コンピュートがある場所にデータを動かすよりも、データがある場所にコンピュートを持って行くほうが良いという意味だ。そこで、コンピュートを配置する場所は『コア』と『エッジ』の2カ所になる」(ブラモフ氏)
「コア」と「エッジ」、いずれもデータのある場所にコンピュートを持って行くという考えは同じだが、役割は異なる。「コア」は、データベースやデータレイクといった1つの場所に、大量に蓄積/格納された“動き(移動)のないデータ”を処理するのに適している。その反対にエッジは、センサーやビデオカメラ、ユーザーデバイス、ロボットなどが出力する“動きのあるデータ”の処理に適した場所だ。
アカマイがConnected Cloudのコンピュートサービスで解決しようとしているのは、次世代アプリケーションに求められるパフォーマンスやスケール、遅延といった課題だ。次世代アプリケーションでは、データベース中心の要素とユーザー/デバイス中心の要素が含まれるため、コアとエッジの両方が単一のプラットフォームで提供されていることが望ましい。
「アカマイにとってのクラウドコンピューティングは、コアとエッジの2つを統合したものであり、現在はその基盤を構築している。これがAkamai Connected Cloudであり、超分散型のクラウドプラットフォーム上で、コンピュート、CDN、セキュリティという(アカマイがサービス提供する)3つすべての処理を行う」(ブラモフ氏)

従来のCDNやセキュリティのサービスも、Connected Cloudから提供される
今年から来年にかけてデータセンター拠点を大幅に拡大へ
Akamai Connected Cloudに注力する同社は、今年から来年にかけてデータセンター拠点数を大幅に拡大していく予定だ。
アカマイ日本法人 マーケティング本部 プロダクト・マーケティング・マネージャーの中西一博氏は、Connected Cloudでとくに解決したいのは「レイテンシ(遅延)」だと述べた。レイテンシの問題を解決するために、「コア」となるデータセンター拠点数を拡大し、さらに自動で接続することで処理の分散を図っていくという。
「要するに、プロセッシングをユーザーの近いところ、デバイスに近いところに置いていくというコンセプトに沿った設計になっている。たとえばAIに関しても、学習(トレーニング)処理に最適なロケーション、学習した結果を用いて判断(推論)するためのロケーションはどこにあるべきかを、エッジとコアの使い分けによって、最適なパフォーマンスで高レベルなコンピューティングが構築できるようになる」(中西氏)

AI領域では、大規模なデータとコンピューティングリソースが必要なトレーニングを「コア」で、低遅延性が求められる推論を「エッジ」で処理できる
Connected Cloudは、初期段階ではメディアやゲーミングといった業界が主なターゲットになるが、将来的にはあらゆる業界に利用が広がっていくことを期待しているという。日本では「IoT」「ゲーミング」といった分野に可能性を感じていると述べた。
なおブルモフ氏は、現在あらゆる領域で注目を集めているAIの活用について、次のように語った。
「アカマイでは2012年ごろ、セキュリティサービスにおいてディープラーニング技術の活用を開始した。これはディープラーニングが大規模なデータセットの分類に適していたからだ。具体的にはアカマイが扱っているトラフィックを使ってモデルをトレーニングし、トラフィックが正常か異常か、また人間のアクセスによるトラフィックかボットによるものなのかを識別できるようになった」(ブルモフ氏)
本記事はアフィリエイトプログラムによる収益を得ている場合があります



