





Stability AIは8月8日(現地時間)、同社初のコーディング用LLM生成AI「StableCode」のリリースを発表した。
3つのモデルを用意

StableCode Instructを使用し、指定されたインストラクションに対するレスポンスを生成するコード
画像生成AI「Stable Diffusion」の開発で知られるStability AIが開発したStableCodeは3つのモデルで構成されている。
・stablecode-completion-alpha-3b-4k:ベースモデル
このモデルは、最大4000トークンまでのコンテキストウィンドーから単一行または複数行のコード補完することを目的としている。コードに特化した大規模なデータセットBigCodeの「stack-dataset」(v1.2)の多様なプログラミング言語セットで学習した後、Python、Go、Java、JavaScript、C、Markdown、C++などの一般的な言語でさらに学習をしている。
・stablecode-instruct-alpha-3b:指示モデル
このモデルは、指示に従ってコードを生成することを目的としている。Alpaca形式の約12万のコード指示/応答ペアでベースモデルを微調整している。

stablecode-completionの使用例
・stablecode-completion-alpha-3b : ロングコンテキストウィンドーモデル
このモデルは、ベースモデルの約4倍にあたる最大1万6000トークンまでの長いコンテキストウィンドーから単一行または複数行のコード補完することを目的としており、同時に最大5つの平均サイズのPythonコードを確認または編集できる。
上記の画面では、Pytorchディープラーニングライブラリを利用した比較的複雑なPythonのコードをレビューしている模様を見ることができる(グレーのテキストはStableCodeの予測を示す)。
目的は「テクノロジーへの公平なアクセス」
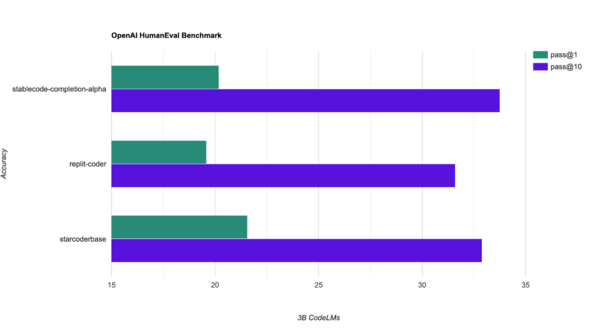
上記のグラフは同じようなパラメータ数とトークン数でトレーニングされた他のモデル(replit-coderおよびstarcoderbase)との比較。一般的なHumanEvalベンチマークで、標準的なpass@1とpass@10のメトリクスを使用している。
Stability AIは「StableCodeが次の10億人のソフトウェア開発者がコードを学ぶ手助けになると同時に、世界中のテクノロジーへの公平なアクセスを提供することを願っている」とリリースを締めくくっている。
Stable Diffusionの会社がなぜコーディング補助ツールを?との疑問も「テクノロジーへの公平なアクセス」という視点から見ると矛盾していないように思える。
本記事はアフィリエイトプログラムによる収益を得ている場合があります






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















