





画像生成AI「Stable Diffusion」の開発で知られる英Stability AIは4月19日(現地時間)、大規模言語モデル「StableLM」をオープンソースでリリース。アルファ版には30億パラメータと70億パラメータのモデルが用意されており、今後150億パラメータから650億パラメータのモデルも用意される予定。
開発者は、CC BY-SA-4.0ライセンスの条件に従って、商用または研究目的で、StableLMベースモデルを自由に検査、使用、適応することができる。
少ないパラメーターにも関わらず高性能を発揮
StableLMは、以前非営利団体のEleutherAIと共同で、GPT-J、GPT-NeoX、Pythiaスイートといった過去の言語モデルをオープンソース化した経験を元に開発された。
トレーニングには、その際に利用されたオープンソースのデータセット「The Pile」を大幅に拡張(1.5兆トークン)したものを利用している。
この巨大なデータセットにより、StableLMは、30億〜70億パラメーター(GPT-3は1750億パラメーター)という比較的小さなサイズにもかかわらず、会話やコーディングのタスクで驚くほど高い性能を発揮するという。
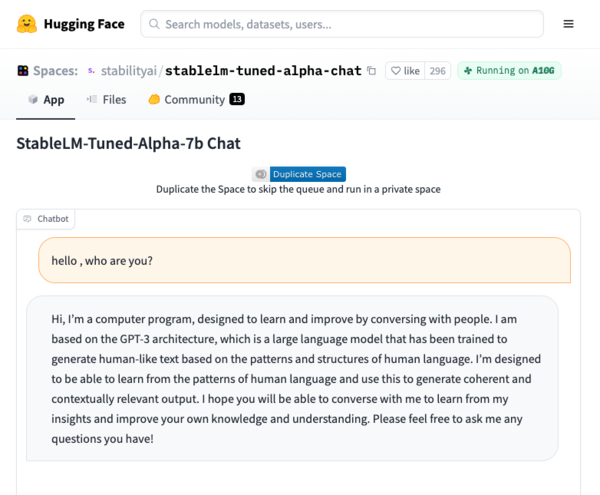
HuggingFace上で実行したところ
なお、StableLM(70億パラメーター)は現在HuggingFaceで試すことができる。入出力は英語のみで、テキストやコードを生成できるという。反応はChatGPTと比べてかなり遅い。
また、StableLMモデルが含まれる「StableLM Suite」には、Alpaca、GPT4All、Dolly、ShareGPT、HHといったオープンソースLLMを使用して微調整された研究用モデルのセットも同梱されている。
これらのモデルは研究用途に限定されるため、非商用のCC BY-NC-SA 4.0ライセンスで公開される。モデルはすべてStability AIのGitHubリポジトリに公開されており当該ライセンスの元、誰でも自由に使用できる。
また、クラウドソーシング型のRLHF(人間のフィードバックに基づいた強化学習)プログラムや、「Open Assistant」と連携したオープンソースデータセットの作成なども計画されているという。
AIは大企業に独占させるべきではないと主張
Stability AIは、「大規模言語モデルはデジタル経済のバックボーンを形成するものであり、その設計において誰もが意見を述べることができるようにしたい」と考えている。
グーグルやマイクロソフトといった少数のビッグテックの独占的サービス(ChatGPTやBing)に依存するのではなく、広く入手可能なハードウェアと互換性のある独立したアプリケーションを構築するため、オープンソースモデルで開発を続けていくとしている。
弊社、オープンな大規模言語モデル「StableLM」をリリース!今は英語がメインですが、日本語版も頑張ります!https://t.co/y0Lah1XQJS#LLM#生成AI
— Stability AI 日本公式 (@StabilityAI_JP) April 19, 2023
なお、Stability AI日本法人のStablity AI Japanは2月20日、日本語に特化したチャットbot「Stable Chat(日本語版)」を開発するとTwitterで発表しているが、「StableLM」については「今は英語がメインですが、日本語版も頑張ります!」としている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります











、バッテリー駆動時間は13時間超え。もう欲しくなる要素しか見つからないッ!")








ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")



