



「HPE Discover 2023」で発表。Crayスパコン+NVIDIA H100 GPU環境を従量制で、サステナビリティ配慮も
生成AI向けスパコンクラウド「HPE GreenLake for LLMs」とはどんなものか
2023年07月13日 10時00分更新

Hewlett Packard Enterprise(HPE)が、今年6月に開催した「HPE Discover 2023」において、大規模言語モデル(LLM)向けのパブリッククラウドサービス「HPE GreenLake for Large Language Models(LLMs)」を発表した。同社が2019年から準備を進めてきた成果として、通常のIaaSとは異なる「ケイパビリティコンピューティング」をクラウドサービスとして提供する、としている。それはいったいどんなものなのだろうか。
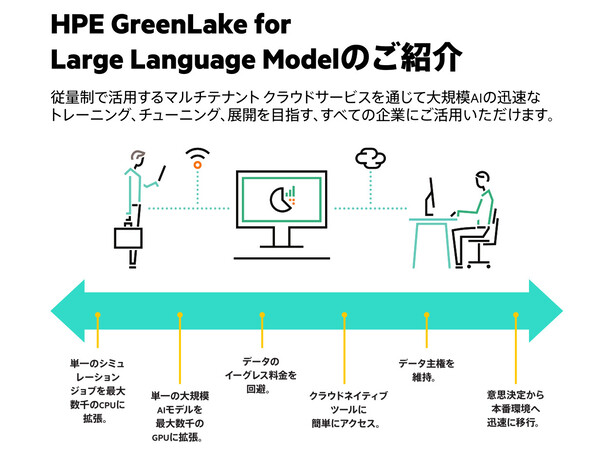
「HPE GreenLake for Large Language Models(LLMs)」は、「NVIDIA H100 GPU」を搭載したスパコンを使い、大規模なAIモデルのトレーニング、チューニング、展開を容易にするクラウドサービス(画像はHPE製品資料より)
スパコンのCrayなどを買収し、着実に「AI時代」の準備を進めてきたHPE
2日目の基調講演のステージに立ったHPE CTOのフィデルマ・ルッソ氏は、「2023年はAI時代の元年」だと述べる。そのうえでAI活用の重要な要素であるスーパーコンピューティング、エンタープライズクラスのミッションクリティカルアーキテクチャは、HPEが得意とする領域だと強調した。

HPE CTOのフィデルマ・ルッソ(Fidelma Russo)氏
HPEでは「AIの可能性を現実のものにするためには、スケーラビリティが重要である」ということを早期から認識していた。そこで2019年、スパコンベンダーのクレイ(Cray)を買収する。この買収によって、米国エネルギー省オークリッジ国立研究所のスパコン「Frontier」の構築と提供を実現したり、大規模アプリケーションをサポートする技術やノウハウを獲得したりすることができた。
ハードウェアとシステムアーキテクチャを揃えたのち、HPEではAIのソフトウェアプラットフォームに対する投資を進めた。LLMのトレーニングや最適化のためのプラットフォームを構築する一環として、2021年にはDetermined AIを買収する。さらに2023年、LLMをベースとするAIアプリケーションのためのデータパイプラインを自動化し、反復/再現可能にする技術を持つPachydermを買収した。
今回発表したHPE GreenLake for LLMsは、こうした戦略的な投資を行ってきた成果となる。
HPE GreenLake for LLMsでは、「NVIDIA H100 GPU」を搭載した「HPE Cray XDスパコン」をサービスインフラとして、まずはドイツAleph Alphaの「Luminous」を事前トレーニング済みで提供する。Luminousは英語など5カ国語をサポートするLLMだ(現状では日本語は非対応)。
「HPE GreenLake for LLMsは、世界で最も洗練されたスーパーコンピューティング技術に基づいて構築されたIaaSサービスだ。どのような規模の企業でも、どこからでも、AIモデルを大規模にトレーニング、最適化、チューニングできる」(ルッソ氏)
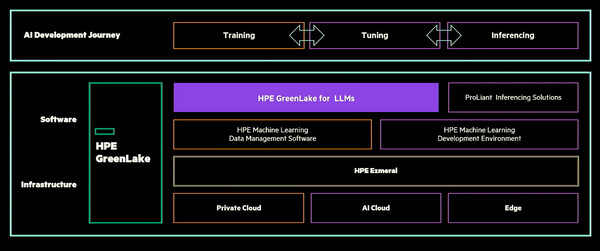
HPE GreenLake for LLMsの位置づけ
高価なスパコンのリソースに容易かつ安価でアクセスできるだけでなく、サステナビリティに配慮している点も大きな特徴だ。
AIモデルのトレーニング、チューニング、推論実行に要するCO2排出量は、すでに無視できないものになっている。ルッソ氏によると、GPT-3モデルのトレーニングだけで、米国の平均的な家庭30軒が1年に費やす量のエネルギーを消費するという。さらに「モデルのトレーニングは消費電力の10%を占めるにすぎない。推論フェーズではその9~10倍の電力を消費する」(ルッソ氏)。
そこでHPE GreenLake for LLMsでは、水冷却、電源設計、サーバー設計、高可用性のシステム設計など、あらゆる面で低消費電力設計が組み込まれている。「ほぼ100%カーボンニュートラルなコロケーション施設で稼働し、発生した熱は温室などに再利用される」(ルッソ氏)。
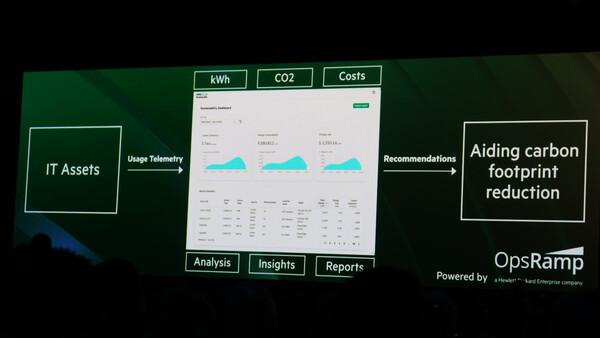
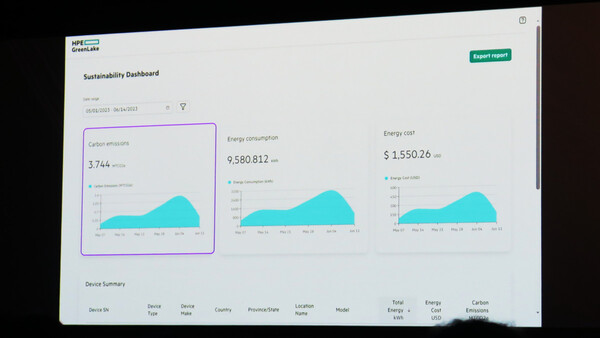
HPEは6月、HPE GreenLakeに持続性の指標を把握できる「Sustainable Dashboard」機能を追加した

「HPE GreenLake for LLMs」はサステナビリティも重要な特徴となる
HPE GreenLake for LLMsは、2023年後半に米国で、2024年に欧州で提供を開始する。日本についても「提供する方向で進めており、1年以内には計画を発表できる見込み」とのことだ。
「ケイパビリティコンピューティング」とは?
AIの取り組みについてのセッションでは、スパコン性能ランキング「TOP500」で2022年に1.1EFLOPS(1.1エクサフロップス)の計算性能を達成し、ランキング1位を獲得したFrontierチームが解説を行った。
HPEのシニアフェローであり、HPC, AI&ラボのチーフアーキテクト兼クラウドサービストップのニック・デュべ氏は、「エクサスケールというマイルストーンに到達したあと、インキュベーションプロジェクトとして『スパコンのクラウド化』に取り組んできた」と明かす。「クラウド化によって、(スパコンを自ら所有している)国立研究所や大企業でなくても大規模なモデルを実行できるようになる」(デュベ氏)。

HPE シニアフェロー HPC, AI&ラボのチーフアーキテクト兼クラウドサービストップのニック・デュべ(Nic Dube)氏
HPE GreenLake for LLMsのシステム面における重要な特徴が「ケイパビリティコンピューティング」だ。これに対し、通常のIaaSで提供されるのは「キャパシティコンピューティング」だという。両者は何が違うのか?
キャパシティコンピューティングとは「何千もの完全に切り離された、独立したワークロードを実行することだ」とデュべ氏は説明する。同じワークロードかもしれないがデータセットは異なり、お互いに関係がない。これに対してケイパビリティコンピューティングは、大量のノードを使った並列分散処理のオーケストレーションを行うことで、「1台のサーバーでは収容できないサイズのワークロードを扱う」(デュべ氏)。
このような特徴から、具体的に言えばキャパシティコンピューティングはWebホスティングやEメールサーバーなどに、ケイパビリティコンピューティングは気象モデルシミュレーションやLLMなどに適しているという。
スケーリングについての考え方も異なる。キャパシティコンピューティングの場合は単体ノードの「弱い」スケーリングにとどまるが、ケイパビリティコンピューティングでは大量のノードを動員することで「強い」スケーリングが実現する。
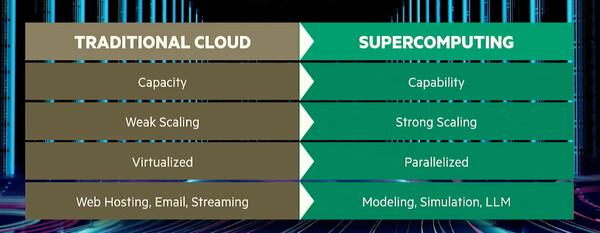
従来型クラウド=キャパシティコンピューティング(左)と、スパコンクラウド=ケイパビリティコンピューティング(右)の違い。モデリング、シミュレーション、LLMといった大規模ワークロードを実行するためには、ケイパビリティコンピューティングの能力が必要だ
キャパシティコンピューティングの環境下で、大きなジョブを複数のGPU上で動かすとどうなるか。1つでもGPUがダウンするとジョブも止まる。しかし、それがSLAの範囲内であれば「完了しないジョブのために使用料金を払い続けることになる」(デュべ氏)。つまり、ジョブがなかなか完了しないためマシンの稼働時間が⻑くなり、料金は膨らみ続ける。コストだけでなく消費電力、サステナビリティの観点でも良くない。
一方でFrontierは4万個のGPUを搭載しており、ダウンすることなく4時間連続で稼働させることができる。これを単一GPUマシンのMTBF(平均故障間隔) に換算すると17年間に相当するが、マシンが17年間ダウンせずに稼働することは不可能だ。
こうした背景から、LLM向けに最適化されたスパコンのクラウドが必要とされるわけだ。
一方で、AI戦略においては「倫理も重要だ」と語るのは、HPE HPC, AI &ラボ担当EVP&GMのジャスティン・ホタード氏だ。HPEでは、倫理的なAIに向けたアプローチとして「プライバシーの保護と安全性」「人間重視」「インクルーシブ」「責任性」「堅牢」という5つの柱を持つと説明する。
「HPEのパーパスは、人々の生活と働き方を改善すること。AIは社会に貢献するものと信じており、Hewlett Packard Labsの活動を通じて責任あるAIをリードしてきた。プライバシー、公平性、コンプライアンスを最初から組み込んだ形で信頼できるAIを実現する」(ホタード氏)

HPE HPC, AI &ラボ担当 EVP&GMのジャスティン・ホタード(Justin Hotard)氏



HPE Discoverの展示会場では「Cray-2」やその水冷装置、「Cray EX4000」などのスパコンが展示されていた
本記事はアフィリエイトプログラムによる収益を得ている場合があります



