




安価でカスタマイズも可能なRISCプロセッサーARCシリーズ
ARC Internationalが最初にリリースしたのがARCtangent(明らかにArcとTangentを掛けたギャグだと思う)という32bitのRISC/DSP混載コア(フロントエンドは通常のRISCプロセッサーだが、バックエンドにDSP処理ユニットが搭載可能)であり、2003年にはARC600という次世代コアも発表している。
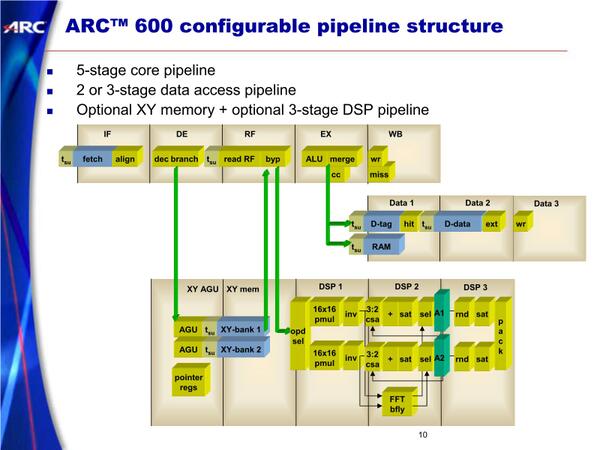
ARC600。RISCコア部はシンプルなシングルイシュー/インオーダー構成。ただこれにDSPユニットががっつり組み合わされているあたりが独特。もちろんIPでの提供なので、DSPユニットを取り除くことも、DSPに最適化することも可能
価格も安く、また構成を自由に変えられる(命令セットに手を入れることも可能)というあたりもあって評判は良く、わりと広範に使われていたARCコアであり、2005年に発表された後継のARC 700シリーズはARM11(ARM 1136J-S)に負けない性能を、より少ないエリアサイズと消費電力で実現できるとしていた。
ただこれに続くコアを開発中の2009年、同社はVirage Logicに買収される。Virage LogicはさまざまなIPを提供するベンダーで、同社のIPポートフォリオ充実のためにARCのIPは最適という判断だったのだろうが、そのVirage Logic自身が2010年にSynopsysに買収されたことで、ARCコアはSynopsysの手に渡ることになった。
といってもSynopsys傘下でも引き続きCPU/DSPコアのIPを提供していることに変わりはない。2020年にはARCv3と呼ばれる新しい命令セットを発表、64bit化が行なわれることになった。
余談であるが、Cadenceも同様にTensilicaというプロセッサーIPのベンダーを2013年に買収しており、こちらもProcessor/DSP IPとして現在も広く提供されている。
さて話を戻すと、このSynopsys傘下でもいろいろなところで同社のコアは利用されている。例えば連載706回でTenstorrentのWormholeをご紹介したが、内部構造のスライドで左側に“4core OoO ARC CPU, runs linux”とあるのがわかる。

Wormholeの内部構造
おそらくはARC HS6xあたりが採用されているものと考えられる。古い話では、インテルが2015年に発表(して2017年には販売終了に)したCurieというチップがあるが、あれにはP5コアに加えて32bit ARCコアが搭載されており、MCUの機能はこのARCコアが担っていた。
ほかにも、WD(Western Digital)が最近はHDDのコントローラーを自社設計のRISC-Vベースに切り替えつつあるが、その前はARCプロセッサーのライセンスを受けて利用していた。要するに直接表に出てこない制御用プロセッサーとして、ARCコアは非常に広範に使われているわけだ。
Synopsysが提供しているプロセッサーIPのラインナップは下表のとおり。
| Synopsysが提供しているプロセッサーIPのラインナップ | ||||||
|---|---|---|---|---|---|---|
| ARC EM | 高効率、低消費電力の組み込み向けコア | |||||
| ARC SEM | ARM EMの機能安全対応版 | |||||
| ARC HS | 高性能のアプリケーションプロセッサ向けコア | |||||
| ARC VPX | 信号処理向けの高性能DSPコア | |||||
| ARC EV | Embedded Vision向けのコア 分類としてはDSPに近く、DNNアクセラレーターを内蔵する |
|||||
このラインナップであっても、AI需要の高まりに向けて、ARC VPXをベースに機械学習のネットワークを稼働させるためのライブラリーを提供したり、より機械学習の性能が必要なエンベデッド・ビジョン(組み込み機器)向けにはARC EVを用意したりしていたのだが、より広範な用途にAIが応用され始める気配が見えてきたことから、これに向けてより強力な性能のプロセッサーIPを提供することにした。
それが2022年に発表されたARC NPXファミリーである。現状はNPX6とNPX6FSの2つがあるが、NPX6FSは車載向けに機能安全対応用の機能が追加されただけで、NPUとしての性能はNPX6とまったく違いがない。
さて、「一般的」というだけあって、わりとどんな用途でもそれなりの性能が出せるようにということで、構成はすさまじい。各々のコアは4096個のMACエンジンが搭載され、これで畳み込み処理を行なう。
それとは別に、ネットワークにまつわる処理(アクティベーションやプーリングなど)はTensor Acceleratorと呼ばれる専用の回路が実施する。またMACエンジンはデフォルトではINT 4/8/16にのみ対応するが、オプションでBF16/FP16にも対応する。このBF16/FP16を利用するには、ライセンス利用扱いになっているTensor FPUを追加する格好だ。
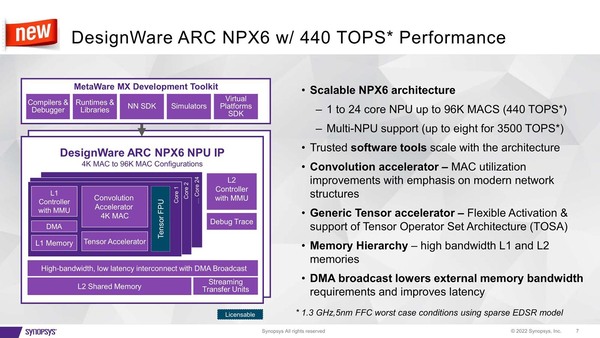
紫の部分が標準的に装備されている部分。いろいろ変更は可能だとは思うが。TOSAはNPX6だけでなく、VPXシリーズのDSP上で動かすことも前提にした、Synopsysが提供するフレームワークのようなものである
個々のコアはL1メモリーを搭載(サイズは未発表)するが、これとは別に共有L2メモリーを最大64MBまで搭載可能である。コアそのものも最大24コアまで搭載可能で、最大構成では実に9万8304個のMAC演算を1サイクルで実施可能となっている。
後で出てくる性能比較ではTSMC N7でのケースだが、一応想定としてはTSMC N5かそれ以下のプロセスを考えているようで、このTSMC N5ではワーストケースでも1.3GHz動作が可能、最大構成での性能は440TOPSにおよぶ。
ちなみにこの440TOPSという数字はSparsityへの対応をTensor Acceleratorで行なった場合で、これをやらないと250TOPどまりだが、それでも結構な性能である。さらにこの24コアのNPUを最大8つ(これをオンチップでやるかオフチップでやるかは全体の設計次第)まで同時に接続可能で、ピークでは3500TOPS(Sparsityなしなら2000TOPS)という化け物で、もうAIトレーニング向けのチップ並みの性能を出せる、としている。
もっとも現実問題としては、64MBものSRAMを実装するとそれなりにダイサイズを喰うことになる。TSMC N5を使うRyzen 7000シリーズのL3が32MBで35mm2くらいなので、64MBでは70mm2に達するわけで、これを8つ実装するとそれだけで560mm2で、モノリシックなダイにするのは無理がある(NPU自身の面積を無視して、L2だけでこのサイズだからだ)。
またNPUはともかくL2をN5で実装するのは効率が悪いわけで、本当にやるならL2はそれこそ3D積層にして、N7かなにかのプロセスにしたいところだろうが、そうした構成はNPX6のままでは都合が悪い。個人的には、仮にNPX6を使って大規模なチップを作るとしたら、L2は最小限に抑えた構成とし、NPX6の外側に大容量のL3コントローラーを接続、そこに3D積層の形でL3メモリーを実装する方が現実的に思える。
もしくは、8つのNPUを同じダイにするのではなく、それぞれ別のダイとして製造の上でチップレット的につなぐ格好だろうか?
ちなみにSynopsysはチップレット用のI/F IPも当然提供しているので、こちらの実装はそう難しくはないだろう(それを言えば、同社は2020年から3DICコンパイラを提供しているので、3D実装もやはり同社のEDAツールを使う限りは相対的に容易だとは思うが)。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























