




映像を扱う場合のネットワークであるが、2018年の研究で、MobileNetV1を実装する際にwidth multiplier(要するに画像の幅である)であるαというパラメーターを実装することで、ネットワーク規模を大幅に抑えられるという話は知られている。
入力画像を絞ると当然精度は落ちることになるが、それこそ人間かどうかの確認であればこの程度の精度でも十分、と言う見極めもできるわけだ
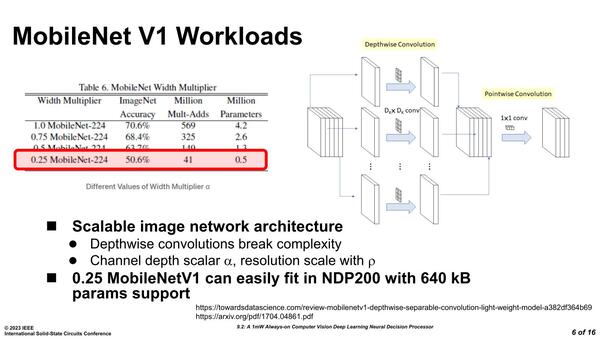
ImageNet V1は224×224ピクセルがデフォルトの画像サイズだが、α=0.25というのは画像サイズが56×56ピクセルまで落ちることになる。ただここまで落とすと、パラメーターの数は500K個に抑えられる。パラメーターは当然8bitなので、パラメーターの保持には500KBが必要と言う計算になる。
NDP200はパラメーター用に640KBのSRAMを内蔵しているので、0.25ImageNet V1を動かすのであれば、外部のメモリーを一切利用せずに内部のSRAMだけで処理が完結することになる。
ただここまで解像度を落としてどの程度の精度で処理ができるのか? という話だがこれも先行研究があり、入力画像を1000クラスの動物に分類するという処理で86.4%の精度を実現したとしている。顔検出であれば十分な精度としていいだろう。

これは入力画像を0.25MobileNet-128、つまり32×32ピクセルまで減らしたケースで、これならパラメーターは200KBで済む計算になる
下の画像が実際のSyntiant 2コアの構成である。
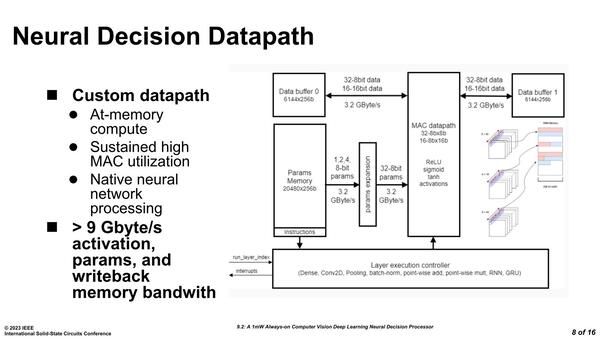
データバッファが2つあるのはダブルバッファリング(例えば画面の取り込みであれば、片方のバッファから前フレームの画面データを読み込んで処理するのと並行して、もう1つのバッファに現フレームの画面データを取り込む)を行なえるようにするためだろう
肝心のプロセッサーエレメントというか、Syntiant風に言うならMACユニットの数そのものは公開されていないが、MACデータパスブロックには2つのデータバッファ(それぞれ192KB)と640KBのパラメーターバッファがそれぞれ3.2GB/秒の帯域で接続され、最大で9.6GB/秒の帯域を利用できるとする。
これ、AIプロセッサーの内部メモリー帯域としてはかなり低い方の部類に入るのだが、消費電力が1mW台のプロセッサーということを考えればかなり高い帯域なのがわかる。1W相当まで動作周波数を上げたら、9.6TB/秒におよぶ計算になるからだ。
このMACユニットは、8bitなら32個、16bitなら16個の同時演算が可能になっている。もっともこれで縦幅が32個なのか? というとそれはおそらく早計で、これが縦横に複数個並んでいると考えるべきだと思われる。
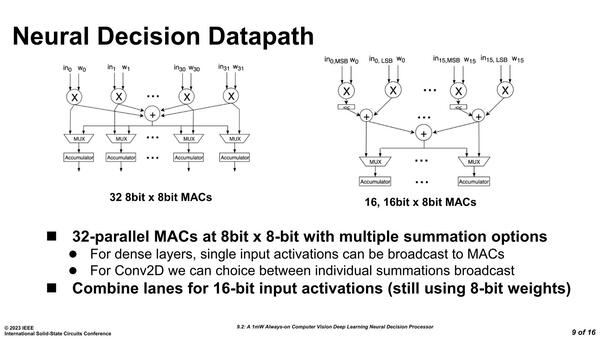
畳み込みでは8bit出力で問題ないが、アクティベーションのための総和の計算は8bitではあふれるおそれがあるので、16bit幅にする必要がある。このあたりは柔軟に構成を変更できるようだ
すでにこのNDP200を搭載した開発ボードも完成しているそうで、Raspberry Piの上にこれを乗せて利用できる格好だ。

オンボードでQVGA CMOSイメージセンサー(Pixart PGA7920)を搭載しており、これを利用しての画像処理アプリケーションがすぐ手掛けられる。ちなみにPAG7920の下に位置しているのは、8×8ピクセルの熱センサーであるPixArtのPAF9701。他にボッシュの6軸加速度センサーも実装されている
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























