




PEをデータフローで動作させて高効率を実現
ちなみにそのPEがどうして効率的か? と言う説明はあった。下の画像は3×3の畳み込み演算の場合だが、まず隣接する4方向との間で演算の半分を行ない、次のサイクルで残り半分の演算ができる格好になる。
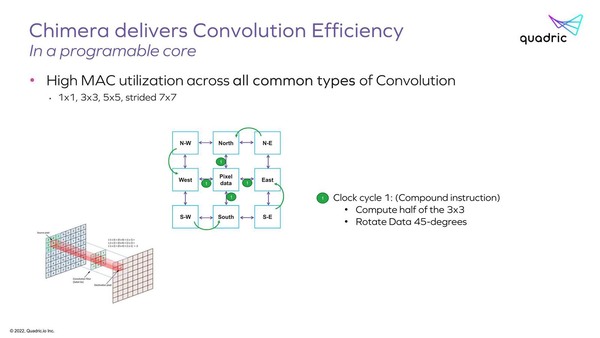
中央のPEと、その上下左右にあるPEの間で演算を行なう。一方斜め方向の4つのPEは、自分の保持するデータを隣りのPEに移動する
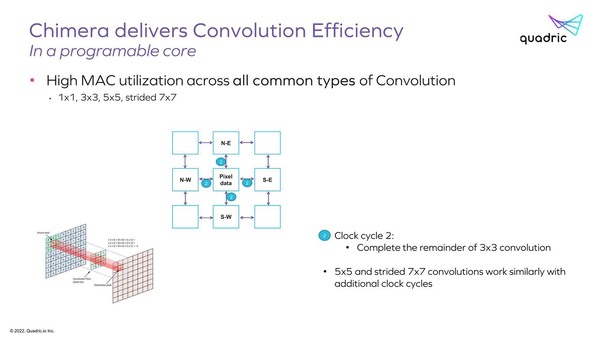
上の画像で行なった、元は斜め方向にあったデータの演算がこのサイクルで行なえる
結果、3x3の畳み込みが2サイクルで実施できるわけだ。同じ仕組みで、より大きなサイズの畳み込み演算も高効率で実現可能というのが同社の説明である。
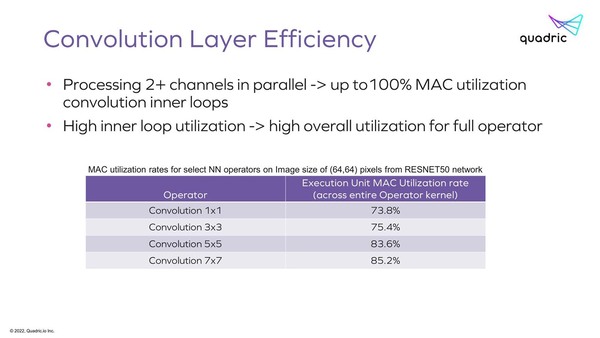
PEをデータフローで動作させるので、結果的に高効率が実現できるわけで、確かにこれを見る限りデータフローっぽい動作になっている
なお、メモリー回りで言えば、2次キャッシュを経由すると最大70倍の電力消費となるそうで、やはりDMAエンジンを経由してアクセスするのはそれなりにコスト増になるのは間違いない。
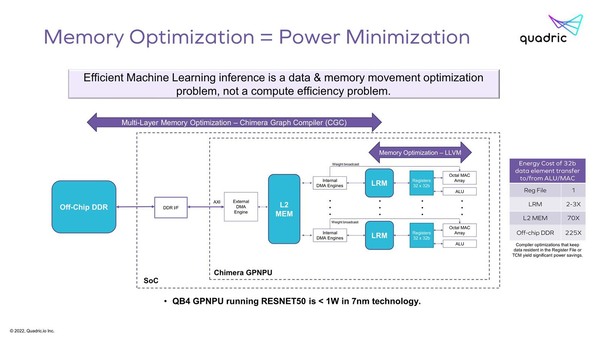
2次キャッシュを経由すると最大70倍の電力消費となる。右の数字はあくまでもデータアクセスの際の消費電力の比であって、速度の比ではないことに注意
でありながらもあえてこんな構成にしたのは、例えばすべてのLRMをファブリックでつなぐような構成にすると、そのほうが複雑さが増し、回路規模が増え消費電力が増えるという判断だったのかもしれない。
後述するQB4の構成では、RESNET-50動作時の消費電力を1W未満に抑えたというあたり、性能と消費電力、複雑さに関してのバーターとしてこの構成になった、と考えるのが妥当なのかもしれない。

QB1が64PE、QB4が256PE、QB16が1024PEという構成になっているようだ。逆に言うとScalar Elementの方は構成が同じ模様
Chimera GPNPUはこのPEの数でQB1~QB16まで3つのラインナップが用意されている。すでにQB4構成に関しての試作チップは存在しており、ラスベガスで開催されるCES 2023に合わせて来年1月5日と1月6日にブースでデモを行なうとしている。

2つ上の画像では7nmで1W未満という説明だったが、この試作チップはTSMCの16FFCの製造とされており、7nmの方は推定値なのかもしれない
また同社は製品だけでなくIPライセンスの形での提供も考えているそうだ。この試作チップはM.2の2280サイズに収まっており、いわゆるエッジ向けAI推論プロセッサーと同じ感じになっている。
この製品版の方は2023年第1四半期中に準備が整うようで、仮にここから量産を始めると第2四半期あたりに最初の量産チップが出てくる格好だろうか。すでにSDKの提供はスタートしており、またLLVM C++コンパイラおよび命令セットシミュレーターも限定的にだが提供を開始しているようだ。

この量産チップのプロセスは未公表。7nmあたりに思えるが、このあたりは価格とのご相談の面もある
根本的なところで、ChimeraをChimeraたらしめている、Scalar ElementとMatrix Elementの謎のパイプライン構造の意味はわからないし、QA4構成で1GHz駆動では4TOPSというのは、性能として低くはないが高くもないという微妙なところである。
とはいえかなりおもしろいプロセッサーではあり、果たしてどこまでマーケットが取れるのか見守りたいところだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 -
第872回
PC
NVIDIAのRubin UltraとKyber Rackの深層 プロトタイプから露見した設計刷新とNVLinkの物理的限界 - この連載の一覧へ









































ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












